机器学习根据任务的不同,可以分为监督学习、无监督学习、半监督学习、强化学习。
1. 无监督学习
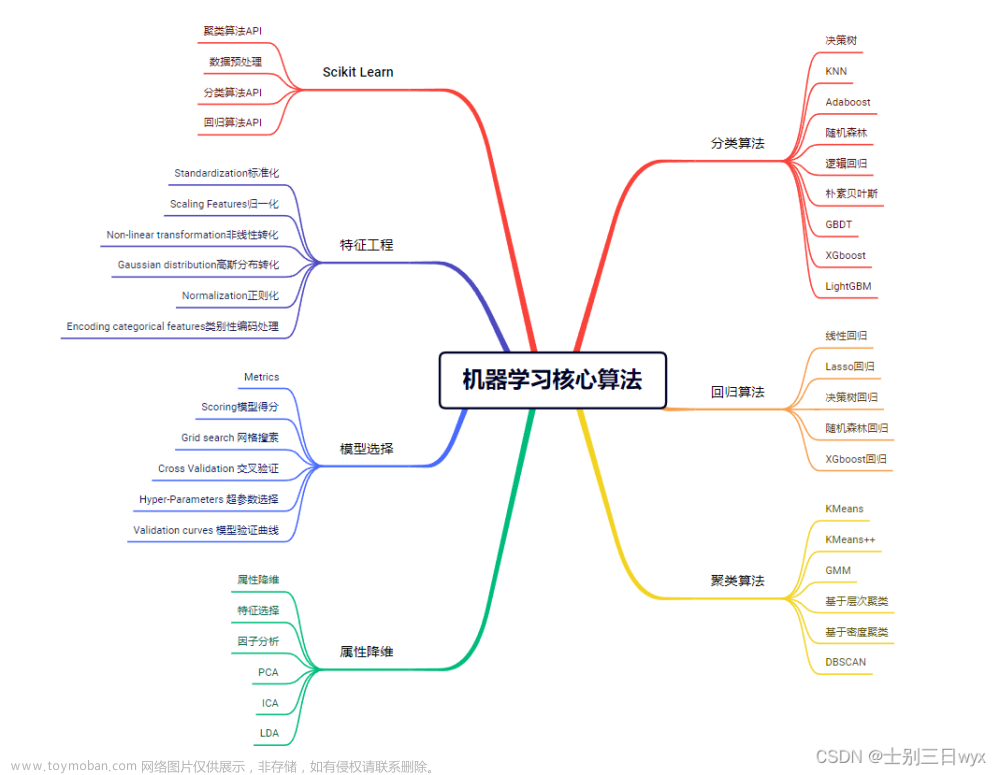
训练数据不包含任何类别信息。无监督学习里典型例子是聚类。要解决的问题是聚类问题和降维问题,聚类算法利用样本的特征,将具有相似特征的样本划分到同一类别中,不关心这个类别具体是什么,聚类典型算法有K-means算法和DBSCAN算法。降维是将样本本点通过线性和非线性变换映射到低维度空间,得到一个关于数据集紧致的低维表示。降维算法有奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)等。
2.监督学习
这是最常见的类型,它包括一个目标/结果变量(或因变量),该变量将被预测,以及一个或多个预测变量(或自变量)之间的关系。使用这些变量我们生成一个函数,该函数将输入映射到期望的输出。训练过程继续进行,直到模型达到所需要的精度水平。监督学习包括回归、决策树、随机森林等。
分类和回归的区别:分类算法中的标签是离散的值,如+1,-1;回归算法中的标签值是连续的值,如通过人的身高、性别等信息预测人的年龄,年龄是连续的整数。

3. 半监督学习
半监督学习 (Semi-Supervised Learning,SSL) 是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。它是利用少量标注数据和大量无标注数据进行学习的模式。典型算法有生成模型算法、自训练算法、联合算法、半监督支持向量机、基于图论的方法。
4. 强化学习
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习类似于监督学习,但未使用样本数据进行训练,是通过不断试错进行学习的模式。常见算法有:Q-learning、SARSA、DQN等。
以上内容,总结如下:文章来源:https://www.toymoban.com/news/detail-603357.html
 文章来源地址https://www.toymoban.com/news/detail-603357.html
文章来源地址https://www.toymoban.com/news/detail-603357.html
到了这里,关于机器学习算法分类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[机器学习]分类算法系列①:初识概念](https://imgs.yssmx.com/Uploads/2024/02/691505-1.png)