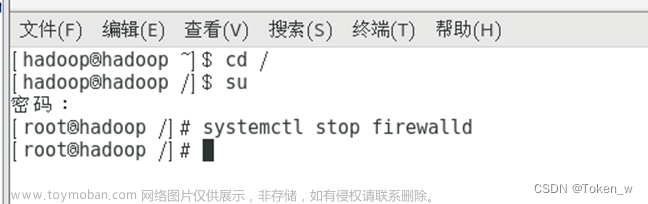
#实现云主机自身使用root用户ssh访问hadoop000免密登陆
搭建环境
vim /etc/hosts hostnamectl set-hostname hadoop000 bash ssh hadoop000 hdfs namenode -format start-all.sh jps systemctl start mysqld.service schematool -dbType mysql -initSchema hive
hdfs操作
创建路径
上传
#创建文件,删除, hadoop fs -mkdir HDFS://phonemodel hdfs dfs -mkdir -p /phonemodel/usergender hadoop fs -touchz /phonemodel/userage/part-r-00000 hadoop fs -rm -r /phonemodel/userage/000000_0 hadoop fs -cat /phonemodel/userage/* #-r删除文件 #上传-f强制覆盖 hadoop fs -put -f /root/phonemodel/gender_age_train.csv /phonemodel/ hadoop fs -put /root/phonemodel/phone_brand_device_model.csv /phonemodel/ hadoop fs -put /root/demo/part-r-00000 /phonemodel/usergender/ hadoop fs -put /root/1/part-r-00000 /phonemodel/agegender/ #究极版 hadoop fs -mkdir -p /phonemodel/agegender && hadoop fs -put /root/1/part-r-00000 /phonemodel/agegender/ /root/internetlogs/journal.log上传至HDFS文件系统/input/下 hadoop fs -mkdir -p /input/ && hadoop fs -put /root/internetlogs/journal.log /input/
INSERT OVERWRITE DIRECTORY '/root/theft/result06' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT COUNT(*) FROM THEFT WHERE case_subtype = '盗窃居民小区车辆';
HIVE数据库操作
创库
建表
导入数据
#建库 CREATE demo IF NOT EXISTS hive; create database demo; #创建表 CREATE EXTERNAL TABLE IF NOT EXISTS user_age ( device_id STRING, gender STRING, age INT, age_group STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'hdfs://phonemodel/'; #导入数据-- 加载数据到表中,上传local,还是inpath LOAD DATA INPATH 'hdfs://your_input_data_path' INTO TABLE user_data; LOAD DATA INPATH '/phonemodel/gender_age_train.csv' INTO TABLE user_data; LOAD DATA INPATH '/phonemodel/gender_age_train.csv' INTO TABLE user_data; LOAD DATA INPATH '/phonemodel/phone_brand_device_model.csv' INTO TABLE user_data;
导出文件
#输出路径
先选
INSERT OVERWRITE DIRECTORY '/phonemodel/userage/' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' SELECT age, COUNT(*) AS user_count FROM user_age GROUP BY age;
insert overwrite local directory '/root/theft/resulte1' #只写到文件夹 row format delimited fields terminated by '\t' select count(report_time)num from project.theft where substr(report_time,1,8)='2821年g5月';
数据分析校验输出
Hive会自动生成输出文件,并将结果写入这些文件中。你不需要提前创建part-r-00000文件,Hive会根据配置自动创建文件并命名
#计算百分比 INSERT OVERWRITE DIRECTORY '/phonemodel/usergender' ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' SELECT gender, COUNT(*) AS gender_count, CONCAT(ROUND(COUNT(*) / t.total_count * 100, 2), '%') AS percentage FROM user_age CROSS JOIN (SELECT COUNT(*) AS total_count FROM user_age) t GROUP BY gender;
#
SELECT gender, COUNT(*) AS gender_count, ROUND(COUNT(*) * 100 / (SELECT COUNT(*) FROM gender_age_train), 2) AS gender_percentage FROM gender_age_train GROUP BY gender; M 64.18% F 35.82%
联合输出
SELECT CONCAT(age, ':', gender) AS age_gender, COUNT(*) AS user_count FROM gender_age_train GROUP BY CONCAT(age, ':', gender);
hadoop
#配置windows cmd C:\WINDOWS\system32\drivers\etc 172.18.39.140 hadoop000 #改成外网ip 创建链接 包-类
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageViewCount {
public static class PageViewMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private Text page = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
if (tokenizer.hasMoreTokens()) {
String pageName = tokenizer.nextToken();
page.set(pageName);
context.write(page, ONE);
}
}
}
public static class PageViewReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Page View Count");
job.setJarByClass(PageViewCount.class);
job.setMapperClass(PageViewMapper.class);
job.setCombinerClass(PageViewReducer.class);
job.setReducerClass(PageViewReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("<输入文件路径>")); // 替换为实际的输入文件路径
FileOutputFormat.setOutputPath(job, new Path("/root/internetlogs/pv")); // 输出到指定目录
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
$ javac -classpath $(hadoop classpath) PageViewCount.java $ jar cf pv.jar PageViewCount*.class
$ hadoop jar pv.jar PageViewCount <输入文件路径>
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class BrowserIdentificationCount {
public static class BrowserIdentificationMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private Text browserIdentification = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
if (tokenizer.hasMoreTokens()) {
String browserId = tokenizer.nextToken(); // 提取浏览器标识
browserIdentification.set(browserId);
context.write(browserIdentification, ONE);
}
}
}
public static class BrowserIdentificationReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Step 4. 定义主类, 描述 Job 并提交 Job
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Browser Identification Count");
job.setJarByClass(BrowserIdentificationCount.class);
job.setMapperClass(BrowserIdentificationMapper.class);
job.setCombinerClass(BrowserIdentificationReducer.class);
job.setReducerClass(BrowserIdentificationReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("<输入文件路径>")); // 替换为实际的输入文件路径
FileOutputFormat.setOutputPath(job, new Path("/root/internetlogs/browser")); // 输出到指定目录
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hadoop jar hadoop_hdfs_operate‐1.0‐SNAPSHOT.jar
WordCountMapper.java
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* Map阶段的业务逻辑需写在自定义的map()方法中
* MapTask会对每一行输入数据调用一次我们自定义的map()方法
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//(1)将MapTask传给我们的文本内容先转换成String
String line = value.toString();
//(2)根据空格将这一行切分成单词
String[] words = line.split(" ");
//(3)将单词输出为<单词,1>
for (String word : words) {
// 将单词作为key,将次数1作为value,以便后续的数据分发,可以根据单词分发,将相同单词分发到同一个ReduceTask中
context.write(new Text(word), new IntWritable(1));
}
}
}
WordCountReducer.java
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* <Deer,1><Deer,1><Deer,1><Deer,1><Deer,1>
* <Car,1><Car,1><Car,1><Car,1>
* 框架在Map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,values{}>,调用一次reduce()方法
* <Deer,{1,1,1,1,1,1.....}>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//做每个单词的结果汇总
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
//写出最后的结果
context.write(key, new IntWritable(sum));
}
}
WordCount Driver
public class WordCount {
/**
* 该MR程序运行的入口,相当于YARN集群(分配运算资源)的客户端
*/
public static void main(String[] args) throws Exception {
// (1)创建配置文件对象
Configuration conf = new Configuration();
// (2)新建一个 job 任务
Job job = Job.getInstance(conf);
// (3)将 job 所用到的那些类(class)文件,打成jar包 (打成jar包在集群运行必须写)
job.setJarByClass(WordCount.class);
// (4)指定 mapper 类和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// (5)指定 MapTask 的输出key-value类型(可以省略)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// (6)指定 ReduceTask 的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// (7)指定该 mapreduce 程序数据的输入和输出路径
Path inPath=new Path("/wordcount/input");
Path outpath=new Path("/wordcount/output");
FileSystem fs=FileSystem.get(conf);
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileInputFormat.setInputPaths(job,inPath);
FileOutputFormat.setOutputPath(job, outpath);
// (8)最后给YARN来运行,等着集群运行完成返回反馈信息,客户端退出
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
}
}
流量
hdfs dfs -put /root/internetlogs/journal.log /input/
PageViewCount是一个Java类,它是用于实现页面访问量统计的MapReduce程序的主类。在这个类中,包含了Map函数和Reduce函数的定义,以及配置作业的相关信息。这个类负责设置作业的输入和输出路径,指定Map和Reduce函数的实现类,以及其他作业配置参数。在main方法中,创建了一个作业实例并运行它
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PageViewCount {
public static class PageViewMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text resource = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] parts = value.toString().split(" ");
if (parts.length >= 4) {
String resourcePath = parts[3];
resource.set(resourcePath);
context.write(resource, one);
}
}
}
public static class PageViewReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "PageViewCount");
job.setJarByClass(PageViewCount.class);
job.setMapperClass(PageViewMapper.class);
job.setCombinerClass(PageViewReducer.class);
job.setReducerClass(PageViewReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/journal.log"));
FileOutputFormat.setOutputPath(job, new Path("/output/pv"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
#编译 hadoop com.sun.tools.javac.Main PageViewCount.java #执行jar包 hadoop jar pv.jar PageViewCount /input/journal.log /output/pv
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class IPCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text ipAddress = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] parts = value.toString().split(" ");
if (parts.length >= 1) {
String ip = parts[0];
ipAddress.set(ip);
context.write(ipAddress, one);
}
}
}
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IPCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class IPCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "IPCount");
job.setJarByClass(IPCount.class);
job.setMapperClass(IPCountMapper.class);
job.setCombinerClass(IPCountReducer.class);
job.setReducerClass(IPCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input/journal.log"));
FileOutputFormat.setOutputPath(job, new Path("/output/ip"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Step 5: 编译和打包程序,将其生成为一个JAR文件。
Step 6: 将journal.log文件上传到HDFS的输入目录,例如/input/journal.log。
Step 7: 运行MapReduce作业,将结果保存到指定的输出目录,例如/output/ip。
Step 8: 将结果从HDFS中复制到本地目录/root/internetlogs/ip/下的part-00000文件。
打包执行
在hdfs文件系统上创建输入文件的目录文章来源:https://www.toymoban.com/news/detail-603845.html
上传输入文件到目录中,上传后查看文件是否在该目录下存在文章来源地址https://www.toymoban.com/news/detail-603845.html
javac -classpath /usr/local/hadoop/share/hadoop/common/hadoop-common-2.7.1.jar:/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:/usr/local/maven/lib/commons-cli-1.2.jar WordCount.java jar -cvf WordCount/WordCount.jar *.class hadoop fs -mkdir /input hadoop fs -put 1.txt /input ./hadoop jar /usr/local/hadoop/bin/WordCount/WordCount.jar org.apache.hadoop.examples.WordCount /input /output 收起
mysql
#见表 CREATE TABLE attendance ( id INT NOT NULL, check_date DATE NOT NULL, emp_id INT NOT NULL, clock_in TIMESTAMP, clock_out TIMESTAMP, PRIMARY KEY (id), UNIQUE KEY uk_attendance (check_date, emp_id) );
#导入数据,用navicat LOAD DATA local INFILE '/root/mysq1/employee/employee.csv' INTO TABLE employee FIELDS TERMINATED BY LINES TERMINATED BY '\n' IGNORE 1 ROWS;
4. 查询“系乐”和“姚欣然”的共同好友信息(ID),结果存入视图table4。(字段:user_name1,user_name2,friend_id)(8.80 / 10分) 操作环境: qingjiao CREATE VIEW table4 AS SELECT u1.user_name AS user_name1, u2.user_name AS f_name, f.friend_id FROM friend f JOIN user u1 ON f.user_id = u1.user_id JOIN user u2 ON f.friend_id = u2.user_id WHERE (u1.user_name = '系乐' OR u1.user_name = '姚欣然') AND (u2.user_name = '系乐' OR u2.user_name = '姚欣然');
到了这里,关于搭建hadoop和hive分析脚本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!