目 录
一、SadTalker介绍
二、准备工作
三、数字人案例(图片转视频)
四、展示效果
五、参考资料
一、SadTalker介绍
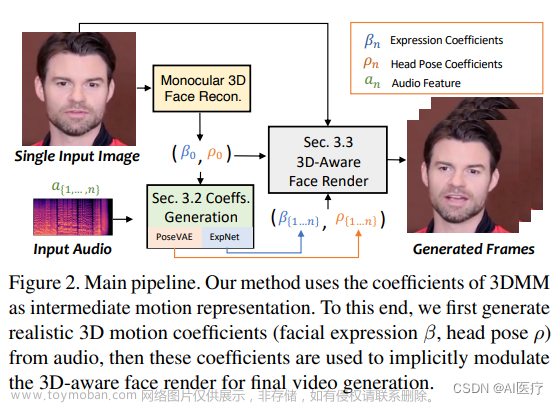
SadTalker是一个开源的虚拟数字人制作工具,可以用一张图片生成数字人口播视频。SadTalker生成3DMM的三维(头部姿势、表情)系数,利用三维面部渲染器进行视频生成。SadTalker还提供了一些新的模式,例如静态模式、参考模式、调整大小模式等,以便更好地进行自定义应用程序。
二、准备工作
部署好AutoDL镜像并开启终端;
部署教程:基于Wav2Lip+GFPGAN的AI数字人视频(以AutoDL算力云平台部署为例)
从我的百度网盘中下载我的源码到AutoDL(该源码包括权重,懒人必备,十分推荐!)
链接:https://pan.baidu.com/s/1etXmmJ_ftwVSaqIe1EK37g?pwd=i2on
提取码:i2on
也可运行以下命令下载源码。(下载该源码还得另外下载权重,不推荐!)
(另外说明,此SadTalker版本为 v0.0.2 )
git clone https://github.com/Winfredy/SadTalker.git首先cd到SadTalker目录下,然后按步骤运行以下命令。
sudo apt update
sudo apt install ffmpeg
pip install -r requirements.txt三、数字人案例(图片转视频)
在命令行中输入以下指令即可跑模型。
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--result_dir <a file to store results> \
--still \
--preprocess full \
--enhancer gfpgan
下面命令是我输入的例子,仅供参考,那些路径都是需要修改的。
python inference.py --driven_audio AIHuman/audio/AIHuman.mp3 --source_image AIHuman/images/03.jpeg --result_dir AIHuman/results --still --preprocess full --enhancer gfpgan参数说明
--driven_audio:输入的音频文件路径。
--source_image:输入的图像文件路径,支持音频文件和视频MP4格式。
--checkpoint_dir:模型存放路径。
--result_dir:数据导出路径。
--enhancer:高清模型,选择gfpgan或RestoreFormer
四、展示效果

五、参考资料
参考项目:SadTalker-GitHub
参考资料:基于SadTalker的AI主播,Stable Diffusion也可用_Mr数据杨的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-603863.html
 文章来源地址https://www.toymoban.com/news/detail-603863.html
文章来源地址https://www.toymoban.com/news/detail-603863.html
到了这里,关于基于SadTalker的AI数字人视频(以AutoDL算力云平台部署为例)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!