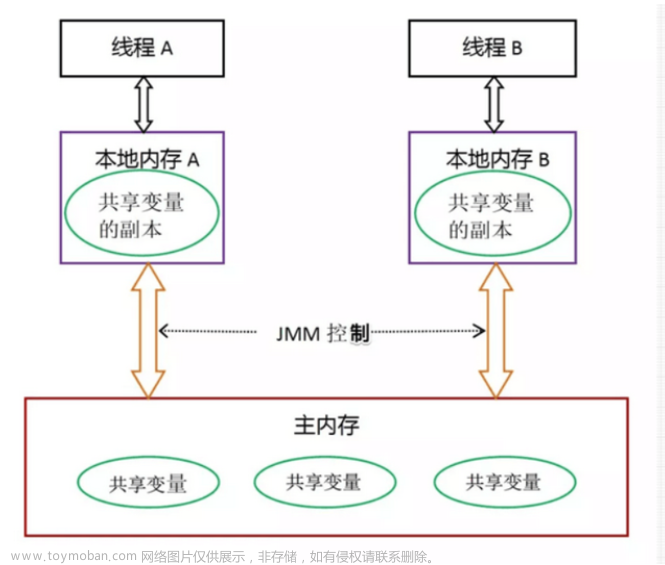
线程创建和生命周期
线程的创建和生命周期涉及到线程的产生、执行和结束过程。让我们继续深入探索这个主题:
线程的创建方式有多种,你可以选择适合你场景的方式:
继承Thread类: 创建一个类,继承自Thread类,并重写run()方法。通过实例化这个类的对象,并调用start()方法,系统会自动调用run()方法执行线程逻辑。
public class MyThread extends Thread {
public void run() {
// 线程逻辑代码
}
}
// 创建并启动线程
MyThread thread = new MyThread();
thread.start();
实现Runnable接口: 创建一个类,实现Runnable接口,并实现run()方法。通过将实现了Runnable接口的对象作为参数传递给Thread类的构造函数,然后调用start()方法启动线程。
public class MyRunnable implements Runnable {
public void run() {
// 线程逻辑代码
}
}
// 创建并启动线程
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();
实现Callable接口: 创建一个类,实现Callable接口,并实现call()方法。通过创建一个FutureTask对象,将Callable对象作为参数传递给FutureTask构造函数,然后将FutureTask对象传递给Thread类的构造函数,最后调用start()方法启动线程。
public class MyCallable implements Callable<Integer> {
public Integer call() {
// 线程逻辑代码
return 1;
}
}
// 创建并启动线程
MyCallable callable = new MyCallable();
FutureTask<Integer> futureTask = new FutureTask<>(callable);
Thread thread = new Thread(futureTask);
thread.start();
通过线程池创建线程: 使用Java的线程池ExecutorService来管理线程的生命周期。通过提交Runnable或Callable任务给线程池,线程池会负责创建、执行和终止线程。
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.execute(new Runnable() {
public void run() {
// 线程逻辑代码
}
});
executorService.shutdown();
线程的生命周期经历以下几个状态:
- 创建状态: 通过实例化Thread对象或者线程池来创建线程。此时线程处于新建状态。
- 就绪状态: 线程被创建后,调用start()方法使其进入就绪状态。在就绪状态下,线程等待系统分配执行的时间片。
- 运行状态: 一旦线程获取到CPU的时间片,就进入运行状态,执行run()方法中的线程逻辑。
- 阻塞状态(Blocked/Waiting/Sleeping): 在某些情况下,线程需要暂时放弃CPU的执行权,进入阻塞状态。阻塞状态可以分为多种情况:
- 中断状态: 可以通过调用线程的interrupt()方法将线程从运行状态转移到中断状态。线程可以检查自身是否被中断,并根据需要作出适当的处理。
- 终止状态: 线程执行完run()方法中的逻辑或者通过调用stop()方法被终止后,线程进入终止状态。终止的线程不能再次启动。
理解线程的创建和生命周期对于处理并发编程非常重要。通过选择合适的创建方式和正确地管理线程的生命周期,可以确保线程安全、高效地运行,从而优化程序性能。
深入剖析synchronized
synchronized关键字在Java中用于实现线程安全的代码块,在其背后使用JVM底层内置的锁机制。synchronized的设计考虑了各种并发情况,因此具有以下优点:
- 优点: 由于官方对synchronized进行升级优化,如当前锁升级机制,因此它具有不断改进的潜力。JVM会进行锁的升级优化,以提高并发性能。
然而,synchronized也有一些缺点: - 缺点: 如果使用不当,可能会导致锁粒度过大或锁失效的问题。此外,synchronized只适用于单机情况,对于分布式集群环境的锁机制不适用。
synchronized的锁机制包括以下几个阶段的升级过程:
- 无锁状态: 初始状态为无锁状态,多个线程可以同时访问临界区。
- 偏向锁: 当只有一个线程访问临界区时,JVM会将锁升级为偏向锁,以提高性能。在偏向锁状态下,偏向线程可以直接获取锁,无需竞争。
- (自旋)轻量级锁: 当多个线程竞争同一个锁时,偏向锁会升级为轻量级锁。在轻量级锁状态下,线程会自旋一定次数,尝试获取锁,而不是直接阻塞。
- 重量级锁: 当自旋次数超过阈值或者存在多个线程竞争同一个锁时,轻量级锁会升级为重量级锁。重量级锁使用了传统的互斥量机制,需要进行阻塞和唤醒操作。
需要注意的是,如果在轻量级锁状态下,有线程获取对象的HashCode时,会直接升级为重量级锁。这是因为锁升级过程中使用的mark头将HashCode部分隐去,以确保锁升级过程的正确性。
底层实现中,synchronized使用了monitor enter和monitor exit指令来进行进入锁和退出锁的同步操作。对于用户来说,这些操作是不可见的。synchronized锁的等待队列存储在对象的waitset属性中,用于线程的等待和唤醒操作。
双重检查单例模式解析
示例代码:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
// 私有构造方法
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
为什么需要使用volatile: 虽然synchronized关键字可以确保线程安全,但是如果没有volatile修饰,可能会发生指令重排的问题。volatile关键字的主要作用是防止指令重排,保证可见性和有序性。尽
管在实际工作中很少遇到指令重排导致的问题,但是理论上存在这种可能性,因此使用volatile修饰变量可以避免出现意外情况。
指令重排原因及影响: 指令重排是为了优化程序的执行速度,由于CPU的工作速度远大于内存的工作速度,为了充分利用CPU资源,处理器会对指令进行重新排序。例如在创建一个对象的过程中,通常被拆分为三个步骤:1)申请空间并初始化,2)赋值,3)建立地址链接关系。如果没有考虑逃逸分析,可能会发生指令重排的情况。
这种重排可能导致的问题是,当一个线程在某个时刻执行到步骤2,而另一个线程在此时获取到了对象的引用,但是这个对象还没有完成初始化,导致使用到未完全初始化的对象,可能会出现异常或不正确的结果。通过使用volatile关键字,可以禁止指令重排,确保对象的完全初始化后再进行赋值操作。
抽象队列同步器(Abstract Queued Synchronizer)解析
抽象队列同步器(Abstract Queued Synchronizer)是Java并发编程中非常重要的同步框架,被广泛应用于各种锁实现类,如ReentrantLock、CountDownLatch等。AQS提供了基于双端队列的同步机制,支持独占模式和共享模式,并提供了一些基本的操作方法。
在AQS中,用来表示是否是独占锁的Exclusive属性对象非常重要。它可以控制同一时间只有一个线程能够获取锁,并且支持重入机制。另外,AQS的state属性也非常关键,state的含义和具体用途是由具体的子类决定的。子类可以通过对state属性的操作来实现不同的同步逻辑。例如,在ReentrantLock中,state表示锁的持有数;在CountDownLatch中,state表示还需要等待的线程数。
此外,AQS还使用两个Node节点来表示双端队列,用于存储被阻塞的线程。这些节点会根据线程的不同状态(如等待获取锁、等待释放锁)被添加到队列的不同位置,从而实现线程同步和调度。
以下是一个简化的示例代码,展示了如何使用ReentrantLock和AQS进行线程同步:
import java.util.concurrent.locks.ReentrantLock;
public class Example {
private static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
lock.lock();
try {
// 执行线程1的逻辑
} finally {
lock.unlock();
}
});
Thread thread2 = new Thread(() -> {
lock.lock();
try {
// 执行线程2的逻辑
} finally {
lock.unlock();
}
});
thread1.start();
thread2.start();
}
}
在上述代码中,我们使用了ReentrantLock作为锁工具,它内部使用了AQS来实现线程同步。通过调用lock()方法获取锁,并在finally块中调用unlock()方法释放锁,确保线程安全执行。这样,只有一个线程能够获取到锁,并执行相应的逻辑。
总之,AQS作为Java线程同步的核心框架,在并发编程中起到了至关重要的作用。它提供了强大的同步机制,可以支持各种锁的实现,帮助我们实现线程安全的代码。
利用Java线程池
使用Java线程池是一种优化并行性的有效方式。线程池可以管理和复用线程,减少了线程创建和销毁的开销,提高了系统的性能和资源利用率。
在Java中,可以使用ExecutorService接口来创建和管理线程池。ExecutorService提供了一些方法来提交任务并返回Future对象,可以用于获取任务的执行结果。
在创建线程池时,可以根据实际需求选择不同的线程池类型。常用的线程池类型包括:
- FixedThreadPool:固定大小的线程池,线程数固定不变。
- CachedThreadPool:可根据需要自动调整线程数的线程池。
- SingleThreadExecutor:只有一个线程的线程池,适用于顺序执行任务的场景。
- ScheduledThreadPool:用于定时执行任务的线程池。
使用线程池时,可以将任务分解为多个小任务,提交给线程池并发执行。这样可以充分利用系统资源,提高任务执行的并行性。
同时,线程池还可以控制并发线程的数量,避免系统资源耗尽和任务过载的问题。通过设置合适的线程池大小,可以平衡系统的并发能力和资源消耗。
探索Java中的Fork/Join框架
Fork/Join框架是Java中用于处理并行任务的一个强大工具。它基于分治的思想,将大任务划分成小任务,并利用多线程并行执行这些小任务,最后将结果合并。
在Fork/Join框架中,主要有两个核心类:ForkJoinTask和ForkJoinPool。ForkJoinTask是一个可以被分割成更小任务的任务,我们需要继承ForkJoinTask类并实现compute()方法来定义具体的任务逻辑。ForkJoinPool是一个线程池,用于管理和调度ForkJoinTask。
下面是一个简单的例子,展示如何使用Fork/Join框架来计算一个整数数组的总和:
import java.util.concurrent.*;
public class SumTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 10;
private int[] array;
private int start;
private int end;
public SumTask(int[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if (end - start <= THRESHOLD) {
int sum = 0;
for (int i = start; i < end; i++) {
sum += array[i];
}
return sum;
} else {
int mid = (start + end) / 2;
SumTask leftTask = new SumTask(array, start, mid);
SumTask rightTask = new SumTask(array, mid, end);
leftTask.fork(); // 将左半部分任务提交到线程池
rightTask.fork(); // 将右半部分任务提交到线程池
int leftResult = leftTask.join(); // 等待左半部分任务的完成并获取结果
int rightResult = rightTask.join(); // 等待右半部分任务的完成并获取结果
return leftResult + rightResult;
}
}
public static void main(String[] args) {
int[] array = new int[100];
for (int i = 0; i < array.length; i++) {
array[i] = i + 1;
}
ForkJoinPool forkJoinPool = new ForkJoinPool();
SumTask sumTask = new SumTask(array, 0, array.length);
int result = forkJoinPool.invoke(sumTask); // 使用线程池来执行任务
System.out.println("Sum: " + result);
}
}
在这个例子中,我们定义了一个SumTask类,继承自RecursiveTask类,并实现了compute()方法。在compute()方法中,我们判断任务的大小是否小于阈值,如果是,则直接计算数组的总和;如果不是,则将任务划分成两个子任务,并使用fork()方法将子任务提交到线程池中,然后使用join()方法等待子任务的完成并获取结果,最后返回子任务结果的和。
在main()方法中,我们创建了一个ForkJoinPool对象,然后创建了一个SumTask对象,并使用invoke()方法来执行任务。最后打印出结果。
通过使用Fork/Join框架,我们可以方便地处理并行任务,并利用多核处理器的性能优势。这个框架在处理一些需要递归分解的问题时非常高效。文章来源:https://www.toymoban.com/news/detail-604426.html
总结
文章涉及了几个常见的并发编程相关的主题。首先,线程的创建和生命周期是面试中常被问及的话题,面试官可能会询问如何创建线程、线程的状态转换以及如何控制线程的执行顺序等。其次,synchronized关键字是用于实现线程同步的重要工具,面试中可能会涉及到它的使用场景以及与其他同步机制的比较。此外,抽象队列同步器(AQS)是Java并发编程中的核心概念,了解其原理和应用场景可以展示对并发编程的深入理解。最后,面试中可能会考察对Java线程池和Fork/Join框架的了解,包括它们的使用方法、优势和适用场景等。种子题目务必学会文章来源地址https://www.toymoban.com/news/detail-604426.html
到了这里,关于Java并发篇:6个必备的Java并发面试种子题目的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!