一、DSL查询文档
(一)DSL查询分类
ES提供了基于JSON的DSL来定义查询。
1、常见查询类型:
- 查询所有: 查询出所有的数据,例如,match_all
-
全文检索(full text)查询: 利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
- match_query
- multi_match_query
-
精确查询: 根据精确词条值查找数据,一般查找精确值,例如:
- ids
- range
- term
-
地理(geo)坐标查询: 根据经纬度查询,例如:
- geo_distance
- geo_bounding_box
-
复合(compound)查询: 复合查询可以将伤处查询条件组合起来,合并查询条件,例如:
- bool
- function_score
2、查询的基本语法
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
3、match_all的使用
GET /indexName/_search
{
"query": {
"match_all": { }
}
}
查询效果
{
"took" : 446,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"info" : "这是我的ES拆分Demo",
"age" : 18,
"email" : "zengoo@163.com",
"name" : {
"firstName" : "Zengoo",
"lastName" : "En"
}
}
}
]
}
}
(二)全文检索查询
全文检索查询,会对用户输入内容分词,常用于搜索框搜索。
1、match查询
(1)结构
GET /indexName/_search
{
"query": {
"match": {
"FILED": "TEXT"
}
}
}
(2)简单使用
GET /test/_search
{
"query": {
"match": {
"info": "ES" #当有联合属性all,进行匹配,就可以进行多条件匹配,按照匹配数量来确定权值大小。
}
}
}
使用结果
{
"took" : 71,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"info" : "这是我的ES拆分Demo",
"age" : 18,
"email" : "zengoo@163.com",
"name" : {
"firstName" : "Zengoo",
"lastName" : "En"
}
}
}
]
}
}
2、multi_match查询
从使用效果上,与条件查询的"all"字段相同。
(1)结构
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", "FIELD2"]
}
}
}
(2)简单使用
GET /test/_search
{
"query": {
"multi_match": {
"query": "ES",
"fields": ["info","age"]
}
}
}
(三)精准查询
精确查询一般是查找精确值,所以不会对搜索条件分词。
1、term: 根据词条精确值查询,在商城项目中,通常会用在类型筛选上。
(1)结构
GET /test/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
(2)简单使用
GET /test/_search
{
"query": {
"term": {
"city": {
"value": "杭州" #精确值
}
}
}
}
2、range: 根据值范围查询,在商城项目中,通常会用在价值筛选上。
(1)结构
GET /test/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}
(2)简单使用
GET /test/_search
{
"query": {
"range": {
"price": {
"gte": 699, #最低值,gte 大于等于,gt 大于
"lte": 1899 #最高值,lte 小于等于,lt 小于
}
}
}
}
(四)地理坐标查询
1、geo_distance: 查询到指定中心小于某个距离值的所有文档(圆形范围圈)。
(1)结构
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"FIELD": "13.21,121.5"
}
}
}
(2)简单使用
GET /test/_search
{
"query": {
"geo_distance": {
"distance": "20km",
"location": "13.21,121.5"
}
}
}
2、geo_bounding_box: 查询geo_point值落在某个举行范围的所有文档(矩形范围圈)。
(1)结构
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
(五)复合查询
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
1、function score: 算分函数查询,可以控制文档相关性算分,控制文档排名。
当我们利用match查询时,文档结果会根据搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
例如,在搜索CSDNJava。
[
{
"_score": 17.85048,
"_source": {
"name": "Java语法菜鸟教程"
}
},
{
"_score": 12.587963,
"_source": {
"name": "Java语法W3CScool"
}
},
{
"_score": 11.158756,
"_source": {
"name": "CSDNJava语法学习树"
}
},
]
相关算法:
- 最开始的算分算法:TF(词条频率) = 词条 / 文档词条总数
-
避免公共词条改良的算分算法:TF-IDF算法
- IDF(逆文档频率) = Log( 文档总数 / 包含词条的文档总数 )
- socre = (∑(i,n) TF) * IDF
- BM25算法: 现在默认采用的算法,该算法比较复杂,其词频曲度最终会趋于水平。
(1)结构
GET /hotel/_search
{
"query": {
"function_socre": { #查询类型
"query": { #查询原始数据
"match": {
"all": "外滩"
}
},
"functions": [ #解析方法
{
"filter": { # 过滤条件
"term": {
"id": "1"
}
},
"weight": 10 # score算分方法,weight是直接以常量为函数结果,其它的还有feild_value_factor:以某字段作为函数结果,random_score: 随机值作为函数结果,script_score:定义计算公式
}
],
"boost_mode": "multiply" # 加权模式,定义function score 与 query score的运算方式,包括 multiply:两者相乘(默认);replace:用function score 替换 query score;其它: sum、avg、max、min
}
}
}
(2)简单使用
需求: 将用户给的词条排名靠前
需要考虑的元素:
- 哪些文档需要算分加权 : 包含词条内容的文档
- 算分函数是什么: weight
- 加权模式用哪个: sum
实现:
GET /hotel/_search
{
"query": {
"function_socre": { # 算分算法
"query": {
"match": {
"all": "速8快捷酒店"
}
},
"functions": [
{
"filter": { # 满足条件,品牌必须是速8
"term": {
"brand": "速8"
}
},
"weight": 2 #算分权重为 2
}
],
"boost_mode": "sum"
}
}
}
2、复合查询 Boolean Query
子查询的组合方式:
- must: 必须匹配每个子查询,类似 “与”
- should: 选择性匹配子查询,类似 “或”
- must_not: 排除匹配模式,不参与算分,类似 “非”
- filter: 必须匹配,不参与算分
实现案例
#搜查位置位于上海,品牌为“皇冠假日”或是“华美达”,并且价格500<price<600元,且评分大于等于45的酒店
GET /hotel/_search
{
"query": {
"bool": {
"must": [ # 必须匹配的条件
{ "term": { "city: "上海" } }
],
"should": [ # 可以匹配到条件
{ "term": { "brand": "皇冠假日" } },
{ "term": { "brand": "华美达" } }
],
"must_not": [ #不匹配的条件
{ "range": { "price": {"lte": 500, "gte": 600} }}
],
"filter": [ #筛选条件
{ "range": { "score": { "gte": 45 } } }
]
}
}
}
二、搜索结果处理
(一)排序
ES支持对搜索结果排序,默认根据(_score)来排序,可以排序的字段类型有:keyword、数值类型、地理坐标类型、日期类型等
1、结构:
# 普通类型排序
GET /test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": {
"order": "desc" # 排序字段和排序方式ASC、DESC
}
}
]
}
# 地理坐标型排序
GET /test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"FIELD": { #精度维度
"lat": 40,
"lon": -70
},
"order": "asc",
"unit": "km"
}
}
]
}
2、实现案例
排序需求: 按照用户评价降序,评价相同的按照价格升序。
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": { # 简化结构可以使用,"score": "desc"
"order": "desc"
},
"price": {
"order": "asc"
}
}
]
}
排序需求: 按照距离用户位置的距离进行升序。
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 40.58489,
"lon": -70.59873
},
"order": "asc",
"unit": "km"
}
}
]
}
(二)分页
修改分页参数
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": "asc"
}
],
"from": 100, # 分页开始的位置,默认为0
"size": 20, # 期望获取的文档总数
}
深度分页问题
当我们将ES做成一个集群服务,那么我们需要选择前10的数据时,ES底层会如何去实现呢?
ES由于使用的是倒排索引,每一台ES都会分片数据。
1、每个数据分片上都排序并查询前1000条文档。
2、聚合所有节点的结果,在内存中重新排序选出前1000条文档。
3、从前1000挑中,选取from=990,size=10的文档
如果搜索页数过深,或者结果集过大,对内存和CPU的消耗越高,因此ES设置的结果集查询上限是10000条。
如何解决深度分页的问题?
- seach after: 分页时需要排序,原理是从上一次的排序值开始,查询下一页数据(官方推荐)。
- scroll: 原理是将排序数据形成缓存保存在内存(官方不推荐)。
(三)高亮
1、概念: 在搜索结果中搜索关键字突出显示。
2、原理
- 将搜索结果中的关键字用标签标记出来
- 在页面中给标签添加css样式
3、语法:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
},
"highlight": { #高亮字段
"fields": {
"FIELD": {
"pre_tags": "<em>", #标签前缀
"post_tags": "</em>", #标签后缀
"require_field_match": "false" #判断该字段是否与前面查询的字段匹配
}
}
}
}
三、RestClient查询文档
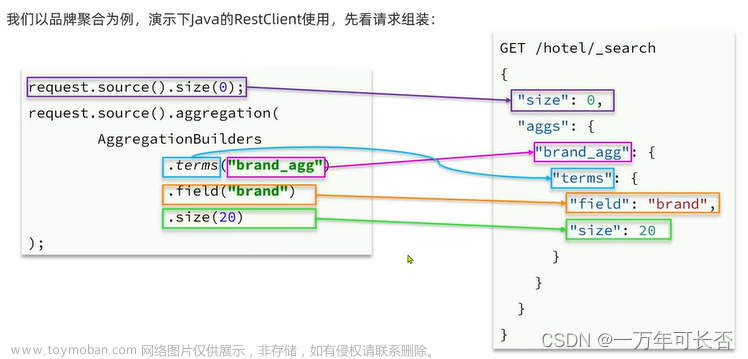
(一)实现简单查询案例
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、组织DSL参数,QueryBuilders是ES的查询API库
request.source().query(QueryBuilders.matchAllQuery());
//3、发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析响应结果,搜索结果会放置在Hits集合中
SearchHits searchHits = response.getHits();
//5、查询总数
long total = searchHits.getTotalHits().value;
//6、查询的结果数组
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits) {
//得到source,source就是查询出来的实体信息
String json = hit.getSourceAsString();
//序列化
HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);
}
(二)match查询
//1、准备Request
SearchRequest request = new SearchRequest("hotel");
//2、组织DSL参数,QueryBuilders是ES的查询API库
//单字段查询
request.source().query(QueryBuilders.matchQuery("all","皇家"));
//多字段查询
//request.source().query(QueryBuilders.multiMatchQuery("皇家","name","buisiness"));
//3、发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//4、解析响应结果,搜索结果会放置在Hits集合中
SearchHits searchHits = response.getHits();
//5、查询总数
long total = searchHits.getTotalHits().value;
//6、查询的结果数组
SearchHit[] hits = searchHits.getHits();
for(SearchHit hit: hits) {
//得到source,source就是查询出来的实体信息
String json = hit.getSourceAsString();
//序列化
HotelDoc hotelDoc = JSON.parseObject(json,HotelDoc.class);
}
(三)精确查询
//词条查询
QueryBuilders.termQuery("city","杭州");
//范围查询
QueryBuilders.rangeQuery("price").gte(100).lte(150);
(四)复合查询
//创建布尔查询
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//添加must条件
boolQuery.must(QueryBuilders.termQuery("city","杭州"));
//添加filter条件
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
(五)排序、分页、高亮
1、排序与分页
// 查询
request.source().query(QueryBuilders.matchAllQuery());
// 分页配置
request.source().from(0).size(5);
// 价格排序
request.source().sort("price", SortOrder.ASC);
2、高亮
高亮查询请求文章来源:https://www.toymoban.com/news/detail-604513.html
request.source().highlighter(new HighLightBuilder().field("name").requireFieldMatch(false));
处理高亮结果文章来源地址https://www.toymoban.com/news/detail-604513.html
// 获取source
HotelDoc hotelDoc = JSON.parseObject(hit.getSourceAsString(), HotelDoc.class);
// 处理高亮
Map<String, HighlightFields> highlightFields = hit.getHighlightFields();
if(!CollectionUtils.isEmpty(highlightFields)) {
// 获取字段结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 去除高亮结果数组的第一个
String name = highlightField.getFragments()[0].string();
hotelDoc.setName(name);
}
}
到了这里,关于SpringCloud学习路线(11)——分布式搜索ElasticSeach场景使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![SpringCloud系列(十六)[分布式搜索引擎篇] - DSL 查询及相关性算分的学习 (部分)](https://imgs.yssmx.com/Uploads/2024/02/580205-1.png)