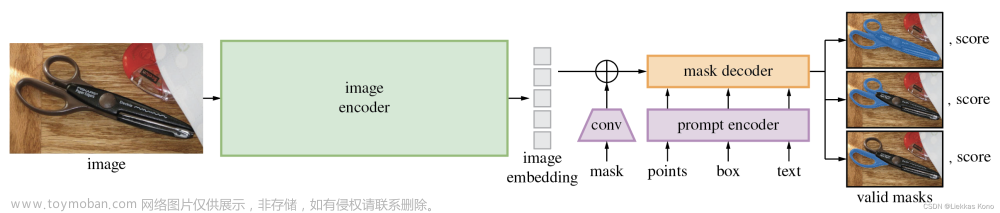
1. 文章简介
- 标题:Skip-Thought Vectors
- 作者:Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler
- 日期:2015
- 期刊:NIPS
2. 文章概括
文章提出了Skip Thought模型,旨在提供一种句向量的预训练方式。文章的核心思想类似于Word2Vec的skip-gram方法,即通过当前句子预测上下文句子。整体架构如下
3 文章重点技术
3.1 Skip Thought Vectors
文章的整体架构选用基于GRU的encoder-decoder网络架构。给定输入的句子三元组
(
s
i
−
1
,
s
i
,
s
i
+
1
)
(s_{i-1}, s_{i}, s_{i+1})
(si−1,si,si+1),令
w
i
t
w_i^t
wit表示句子
s
i
s_i
si的第
t
t
t个单词,
x
i
t
x_i^t
xit表示其对应的单词嵌入。
首先模型对输入的句子
s
i
s_i
si进行编码,encoder国策可表示为下面的GRU公式:
r
t
=
σ
(
W
r
x
t
+
U
r
h
t
−
1
)
∈
(
0
,
1
)
,
z
t
=
σ
(
W
z
x
t
+
U
z
h
t
−
1
)
∈
(
0
,
1
)
,
h
‾
t
=
tanh
(
W
x
t
+
U
(
r
t
⊙
h
t
−
1
)
)
,
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
‾
t
r^t = \sigma (W_r x^t + U_r h^{t-1}) \in (0, 1), \\z^t = \sigma (W_z x^t + U_z h^{t-1}) \in (0, 1), \\\overline{h}^t = \tanh (Wx^t + U(r^t \odot h^{t-1})) ,\\ h^t = (1-z^t)\odot h^{t-1} + z^t \odot \overline{h}^t
rt=σ(Wrxt+Urht−1)∈(0,1),zt=σ(Wzxt+Uzht−1)∈(0,1),ht=tanh(Wxt+U(rt⊙ht−1)),ht=(1−zt)⊙ht−1+zt⊙ht,其中
r
t
,
z
t
∈
(
0
,
1
)
r^t, z^t \in (0, 1)
rt,zt∈(0,1)表示重置门和更新门,
h
‾
t
\overline{h}^t
ht表示候选的隐藏状态,其更新到
t
t
t时刻的隐藏层比例由更新门
z
t
z^t
zt确定,其从上一个时刻隐藏层输入的比例由重置门
r
t
r^t
rt确定。
接下来将句子编码分别传入到解码GRU中,用于预测当前句子相邻的上/下一个句子
s
i
−
1
,
s
i
+
1
s_{i-1}, s_{i+1}
si−1,si+1,省略角标
i
−
1
,
i
+
1
i-1, i+1
i−1,i+1,相邻两个句子的解码公式均为
r
t
=
σ
(
W
r
d
x
t
−
1
+
U
r
d
h
t
−
1
+
C
r
h
i
)
∈
(
0
,
1
)
,
z
t
=
σ
(
W
z
d
x
t
+
U
z
d
h
t
−
1
)
+
C
z
h
i
∈
(
0
,
1
)
,
h
‾
t
=
tanh
(
W
d
x
t
+
U
d
(
r
t
⊙
h
t
−
1
)
+
C
h
i
)
,
h
t
=
(
1
−
z
t
)
⊙
h
t
−
1
+
z
t
⊙
h
‾
t
r^t = \sigma (W_r^d x^{t-1} + U_r^d h^{t-1} + C_r h_i )\in (0, 1), \\z^t = \sigma (W_z^d x^t + U_z^d h^{t-1}) + C_z h_i \in (0, 1), \\\overline{h}^t = \tanh (W^dx^t + U^d(r^t \odot h^{t-1}) + Ch_i) ,\\ h^t = (1-z^t)\odot h^{t-1} + z^t \odot \overline{h}^t
rt=σ(Wrdxt−1+Urdht−1+Crhi)∈(0,1),zt=σ(Wzdxt+Uzdht−1)+Czhi∈(0,1),ht=tanh(Wdxt+Ud(rt⊙ht−1)+Chi),ht=(1−zt)⊙ht−1+zt⊙ht,即计算当前时刻的解码输出时,会考虑上一时刻的输入词嵌入和当前时刻的编码输出
h
i
h_i
hi。给定
h
i
+
1
t
h_{i+1}^t
hi+1t,训练目标为通过前面时刻的单词预测(输入单词及对应编码嵌入)当前时刻
t
t
t的单词:
P
(
w
i
+
1
t
∣
w
i
+
1
<
t
,
h
i
)
∝
exp
(
v
w
i
+
1
t
,
h
i
+
1
t
)
P(w_{i+1}^t|w_{i+1}^{<t}, h_i) \propto \exp (v_{w_{i+1}^t}, h_{i+1}^t)
P(wi+1t∣wi+1<t,hi)∝exp(vwi+1t,hi+1t),其中
v
w
i
+
1
t
v_{w_{i+1}^t}
vwi+1t表示
w
i
+
1
t
w_{i+1}^t
wi+1t对应的词表矩阵的行向量。
总结来说,模型会首先对输入句子进行编码,然后将该编码得到的隐藏状态输入到其相邻句子的解码GRU中,尝试生成与其相邻的句子。类似于word2vec中的通过中心词预测上下文,只是上下文窗口固定为1。
最终训练的目标函数即为相邻句子解码的目标函数之和:
∑
t
log
P
(
w
i
+
1
t
∣
w
i
+
1
<
t
,
h
i
)
+
log
P
(
w
i
−
1
t
∣
w
i
−
1
<
t
,
h
i
)
\sum_t \log P(w_{i+1}^t|w_{i+1}^{<t}, h_i) + \log P(w_{i-1}^t|w_{i-1}^{<t}, h_i)
t∑logP(wi+1t∣wi+1<t,hi)+logP(wi−1t∣wi−1<t,hi)
3.2 词表拓展
为了处理词表中未出现的单词,文章选择采用Word2Vec等较全的预训练单词嵌入进行补充。由于该单词嵌入和Skip-thought训练的单词嵌入有一定的偏差,所以文章先训练一个从Word2Vec到RNN(Skip-thought)的l2线性回归: f : V w 2 v → V r n n f: \mathcal{V}_{w2v}\to \mathcal{V}_{rnn} f:Vw2v→Vrnn。推理阶段,针对词表中未出现的单词 v v v,会首先查找其在Word2Vec下的嵌入 v w 2 v v_{w2v} vw2v,再通过学习好的映射 f f f预测其在文章训练的空间下的嵌入表达; v r n n ≈ f ( v w 2 v ) v_{rnn} \approx f(v_{w2v}) vrnn≈f(vw2v)。
4. 文章亮点
文章参考Skip-gram的思想,通过训练一个基于RNN的编码-解码模型,得到句子的预训练嵌入。实验证明,只需要在预训练的嵌入上增加一个简单的Logistic Regression,就可以持平针对下游任务精心设计的模型的表现,在当下(2015年)达到了SOTA水平。且文章通过t-SNE方法对训练的句向量进行了可视化表达,发现训练的句向量在多个数据集上呈现较为理想(按照标签组团)的分布,如下图所示。
文章给出的Skip-thought向量可以较好的捕捉到句子特征,可供开发人员在此基础上进一步研究基于句向量的NLP任务。
5. 原文传送门
Skip-Thought Vectors文章来源:https://www.toymoban.com/news/detail-604610.html
6. References
[1] 论文笔记–Efficient Estimation of Word Representations in Vector Space文章来源地址https://www.toymoban.com/news/detail-604610.html
到了这里,关于论文笔记--Skip-Thought Vectors的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[论文阅读笔记18] DiffusionDet论文笔记与代码解读](https://imgs.yssmx.com/Uploads/2024/01/401181-1.png)