概述
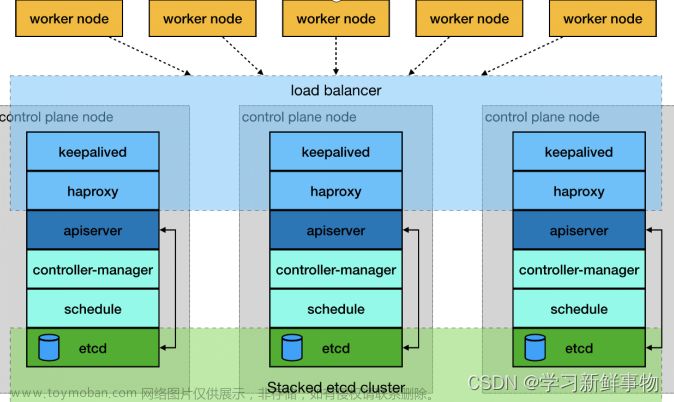
从前面的基础章节了解到,kubernetes的mastere节点基础组件大致包括kube-apiserver、kube-controller-manager、kube-scheduler,还有一个重要的数据存储服务etcd。这些主件作为master节点的服务相当重要,很多时候我们都需要保证其高可用。下面将分享在实际工作中的一些常见做法。
kube-apiserver 高可用方案
在使用私有云的时候,我们一般采用haproxy+keepalived的方式来做高可用(注意:在生成证书的时候一定要把VIP地址加入进证书)
[root@k8s-m1 k8s-resource]# openssl x509 -in /etc/kubernetes/pki/apiserver.crt -text -noout
......
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Server Authentication
X509v3 Subject Alternative Name:
DNS:k8s-m1, DNS:k8s-m2, DNS:k8s-m3, DNS:kubernetes, DNS:kubernetes.default, DNS:kubernetes.default.svc, DNS:kubernetes.default.svc.cluster.local, DNS:localhost, IP Address:10.96.0.1, IP Address:192.168.2.140, IP Address:192.168.2.250, IP Address:127.0.0.1, IP Address:192.168.2.141, IP Address:192.168.2.142
......
##可以看到有192.468.2.250这个VIP
haproxy+keepalived 安装和配置
[root@k8s-m1 ]# yum install haproxy keepalived -y
#以我现有测试集群为例,节点分别为192.168.2.140/141/142,vip为192.168.2.250,修改配置
[root@k8s-m1 ]# cat <<EOF > /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
listen stats
bind *:8006
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth admin:admin
frontend k8s-api
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-api
backend k8s-api
mode tcp
option tcplog
option httpchk GET /healthz
http-check expect string ok
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server api1 192.168.2.140:6443 check check-ssl verify none
server api2 192.168.2.141:6443 check check-ssl verify none
server api3 192.168.2.142:6443 check check-ssl verify none
EOF
[root@k8s-m1 ]# cat <<EOF > /etc/keepalived/keepalived.conf
global_defs {
enable_script_security
}
vrrp_script haproxy-check {
user root
script "/bin/bash /etc/keepalived/check_haproxy.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance haproxy-vip {
state MASTER ##注意修改,其中主为MASTER,从为BACKUP
priority 100 ##注意修改,数字越大,优先级越高,主>从
interface eth0 #注意实际环境中网卡名字,有的是ens*啥的
virtual_router_id 48 #所有节点的id要一致
advert_int 3
unicast_src_ip 192.168.2.140 # 本机IP
unicast_peer {
192.168.2.141 # 对端IP
192.168.2.142 # 对端IP
}
virtual_ipaddress {
192.168.2.250/24 # VIP地址
}
track_script {
haproxy-check
}
}
EOF
[root@k8s-m1 ]# cat <<'EOF'> /etc/keepalived/check_haproxy.sh
#!/bin/bash
VIRTUAL_IP=192.168.2.250.250
errorExit() {
echo "*** $*" 1>&2
exit 1
}
if ip addr | grep -q $VIRTUAL_IP ; then
curl -s --max-time 2 --insecure https://${VIRTUAL_IP}:8443/healthz -o /dev/null || errorExit "Error GET https://${VIRTUAL_IP}:8443/healthz"
fi
EOF
[root@k8s-m1 ]# systemctl enable haproxy
[root@k8s-m1 ]# systemctl enable keepalived
[root@k8s-m1 ]# systemctl restart haproxy
[root@k8s-m1 ]# systemctl restart keepalived
#其他节点类似配置
到此kube-apiserver高可用就搭建完成,在所有连接apiserver中的地址都填写这个VIP地址尤其是kubectl客服端中连接kubernetes集群的地址。
kube-scheduler和kube-controller-manager高可用方案
在部署kube-scheduer和kube-controller-manager使用一主多从的高可用方案,在同一时刻只允许一个服务处理具体的任务。Kubernetes中实现了一套简单的选主逻辑,依赖Etcd实现scheduler和controller-manager的选主功能。
scheduler和controller-manager在启动的时候设置了--leader-elect=true参数,启动后将通过竞争选举机制产生一个 leader 节点,只有在获取leader节点身份后才可以执行具体的业务逻辑。它们分别会在Etcd中创建kube-scheduler和kube-controller-manager的endpoint,endpoint的信息中记录了当前的leader节点信息,以及记录的上次更新时间。leader节点会定期更新endpoint的信息,维护自己的leader身份。每个从节点的服务都会定期检查endpoint的信息,如果endpoint的信息在时间范围内没有更新,它们会尝试更新自己为leader节点。scheduler服务以及controller-manager服务之间不会进行通信,利用Etcd的强一致性,能够保证在分布式高并发情况下leader节点的全局唯一性。
当集群中的leader节点服务异常后,其它节点的服务会尝试更新自身为leader节点,当有多个节点同时更新endpoint时,由Etcd保证只有一个服务的更新请求能够成功。通过这种机制sheduler和controller-manager可以保证在leader节点宕机后其它的节点可以顺利选主,保证服务故障后快速恢复。
当集群中的网络出现故障时对服务的选主影响不是很大,因为scheduler和controller-manager是依赖Etcd进行选主的,在网络故障后,可以和Etcd通信的主机依然可以按照之前的逻辑进行选主,就算集群被切分,Etcd也可以保证同一时刻只有一个节点的服务处于leader状态。
查看kube-controller-manager当前的 leader
[root@k8s-m1 k8s-resource]# kubectl get endpoints kube-controller-manager --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"k8s-m2_433b35d2-7454-46ab-9743-9d9547421c95","leaseDurationSeconds":15,"acquireTime":"2023-07-03T02:06:11Z","renewTime":"2023-07-20T02:29:26Z","leaderTransitions":134}'
endpoints.kubernetes.io/last-change-trigger-time: "2023-07-03T10:07:05+08:00"
creationTimestamp: "2022-11-07T08:00:04Z"
labels:
k8s-app: kube-controller-manager
service.kubernetes.io/headless: ""
可见,kube-controller-manager组件当前的 leader 为 k8s-m2 节点
查看kube-scheduler当前的 leader
[root@k8s-m1 k8s-resource]# kubectl get endpoints kube-scheduler --namespace=kube-system -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"k8s-m2_6d296080-bbed-4cca-88d2-cb9ccb3f73b5","leaseDurationSeconds":15,"acquireTime":"2023-07-03T02:05:48Z","renewTime":"2023-07-20T02:29:41Z","leaderTransitions":127}'
endpoints.kubernetes.io/last-change-trigger-time: "2023-07-03T10:07:23+08:00"
creationTimestamp: "2022-11-07T08:00:04Z"
labels:
k8s-app: kube-scheduler
service.kubernetes.io/headless: ""
可见,kube-scheduler组件当前的 leader 为 k8s-m2节点。
可以在测试环境随便找一个或两个 master 节点,停掉kube-scheduler或者kube-controller-manager服务,看其它节点是否获取了 leader 权限(systemd 日志)
ETCD服务的高可用方案
在生产环境,一般建议通过systemd的方式部署多节点的etcd集群(基数个),方便排错备份等工作。每个 etcd cluster 都是有若干个 member 组成的,每个 member 是一个独立运行的 etcd 实例,单台机器上可以运行多个 member。
在正常运行的状态下,集群中会有一个 leader,其余的 member 都是 followers。leader 向 followers 同步日志,保证数据在各个 member 都有副本。leader 还会定时向所有的 member 发送心跳报文,如果在规定的时间里 follower 没有收到心跳,就会重新进行选举。
客户端所有的请求都会先发送给 leader,leader 向所有的 followers 同步日志,等收到超过半数的确认后就把该日志存储到磁盘,并返回响应客户端。采用了 raft 算法,实现分布式系统数据的可用性和一致性
每个 etcd 服务有三大主要部分组成:raft 实现、WAL 日志存储、数据的存储和索引。WAL 会在本地磁盘(就是之前提到的 --data-dir)上存储日志内容(wal file)和快照(snapshot)。
查看当前etcd集群状态
[root@k8s-m1 ~]# cat <<EOF > /etc/profile.d/etcd.sh
alias etcd_v2='etcdctl --cert-file /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key-file /etc/kubernetes/pki/etcd/healthcheck-client.key \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://192.168.2.140:2379,https://192.168.2.141:2379,https://192.168.2.142:2379'
alias etcd_v3='ETCDCTL_API=3 \
etcdctl \
--cert /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key /etc/kubernetes/pki/etcd/healthcheck-client.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://192.168.2.140:2379,https://192.168.2.141:2379,https://192.168.2.142:2379'
EOF
[root@k8s-m1 ~]# source /etc/profile.d/etcd.sh
[root@k8s-m1 pki]# etcd_v3 --write-out=table endpoint status
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.2.140:2379 | 19df3a9852e0345a | 3.4.13 | 24 MB | true | 267803 | 107799988 |
| https://192.168.2.141:2379 | 66d402f1ef2c996e | 3.4.13 | 24 MB | false | 267803 | 107799988 |
| https://192.168.2.142:2379 | 3bb3629d60bef3f6 | 3.4.13 | 24 MB | false | 267803 | 107799989 |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
[root@k8s-m1 pki]#
可以发先当前etcd集群中192.168.2.140为leader节点。将192.168.2.140节点上的etcd停掉后,集群会自动选举去一个新的leader节点。文章来源:https://www.toymoban.com/news/detail-604829.html
[root@k8s-m1 pki]# systemctl stop etcd
[root@k8s-m1 pki]# etcd_v3 --write-out=table endpoint status
Failed to get the status of endpoint https://192.168.2.140:2379 (context deadline exceeded)
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.2.141:2379 | 66d402f1ef2c996e | 3.4.13 | 24 MB | true | 267804 | 107800390 |
| https://192.168.2.142:2379 | 3bb3629d60bef3f6 | 3.4.13 | 24 MB | false | 267804 | 107800390 |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
更多关于kubernetes的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出文章来源地址https://www.toymoban.com/news/detail-604829.html
到了这里,关于【kubernetes系列】kubernetes之基础组件高可用方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!