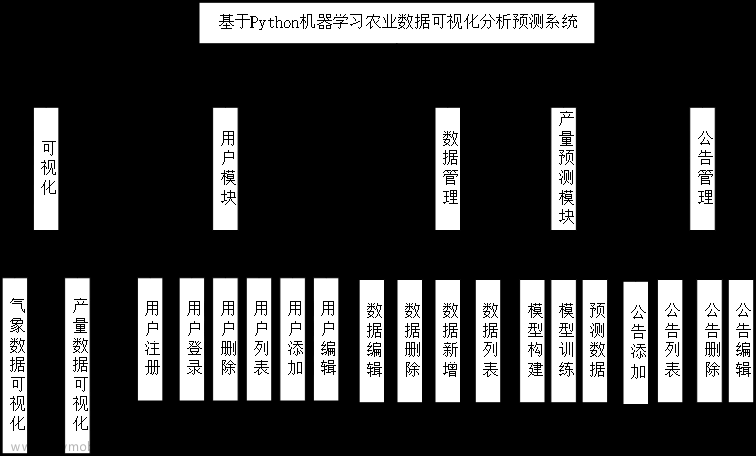
1、Boosting算法

Boosting算法是通过串联的方式,将一组弱学习器提升为强学习器算法。它的工作机制如下:
(1)用初始训练集训练出一个基学习器;
(2)依据基学习器的表现对训练样本分布进行调整,使得之前做错的训练样本在之后中得到最大的关注;
(3)用调整后的样本分布进行下一个基学习器;
(4)重复2-3的步骤,直到基学习器的数量达到了指定的T值后
(5)将T个基学习器进行加权组合得到集成的学习器。
而根据策略不同,会有Adaboost和GBDT、XGBoost三种常见的Boosting算法。
2、Adaboost算法
Adaboost强调Adaptive(自适应),通过不断修改样本权重(增大分错样本权重,降低分对样本权重),不断加入弱分类器进行boosting。它的核心步骤为以下两个:
权值调整:提高上一轮错误分类的样本权值,降低正确分类的样本权值,从而使得错误分类的样本在下一轮基分类器中获得更大的关注。
基分类器组合:采用加权多数表决的方法,即加大分类误差小的分类器权值,减少误差大的分类器权值。
Adaboost的步骤和考虑点和Boosting算法一致,步骤也基本一致。
Adaboost算法特点
- 可以使用各种方法构建子分类器,本身提供框架
- 子分类器容易构建
- 速度快,不怎么调节参数
- 泛化错误率低
3、GBDT算法
GBDT是旨在不断减少残差(回归),通过不断加入新的树旨在在残差减少(负梯度)的方向上建立一个新的模型。——即损失函数是旨在最快速度降低残差。为了得到残差,所有的决策树都是使用CART回归树。其中Shrinkage(缩减)是GBDT的一个重要分支,它通过每次走小步的方式来逼近真实的结果,这种方式可以有效减少过拟合的风险,因为每棵树的只学习一小部分,累加的结果也是这小部分的内容,通过多学习几棵树来逼近目标。
残差:真实值与预测值的差值。
基本原理

(1)训练一个模型m1(20岁),产生错误e1(10岁);
(2)针对e1训练第二个模型m2(6岁),产生错误e2(4岁);
(3)针对e2训练第三个模型m3(3岁),产生错误e3(3岁);
(4)针对e3训练第四个模型m4(1岁)…
(5)最终的预测结果为:m1+m2+m3+m4 = 20+6+3+1=30岁
当然实际的流程中不会只对一个特征进行预测,实际的GBDT的过程会像下面类似的,不同的特征进行预测,然后对于每棵树的结果给予不同的权重,最后将不同树相加:
GBDT特点
优点:文章来源:https://www.toymoban.com/news/detail-605072.html
- 预测阶段,因为每棵树的结构都已确定,可并行化计算,计算速度快。
- 适用稠密数据,泛化能力和表达能力都不错,数据科学竞赛榜首常见模型。
- 可解释性不错,鲁棒性亦可,能够自动发现特征间的高阶关系。
缺点:文章来源地址https://www.toymoban.com/news/detail-605072.html
- GBDT在高维稀疏的数据集上,效率较差,且效果表现不如SVM或神经网络。
- 适合数值型特征,在NLP或文本特征上表现弱。
- 训练过程无法并行,工程加速只能体现在单颗树构建过程中。
问题1:为什么不用CART分类树呢?
GBDT每次的迭代要拟合的是梯度值,所以要用连续值的回归树
问题2:回归树和分类树的区别?
1.对于回归树来说最重要的是寻找最佳的划分点,而划分点包含了所有特征的可取值。
2.分类树的最佳划分点都是熵或者基尼系数,也就说用纯度来衡量,但回归树的样本中都是连续标签值,用熵就不合适,用平方误差能够更好的拟合。
4、XGBOOST算法
XGBOOST的原理跟GBDT差不多,它是经过优化的分布式梯度提升库,同时还是大规模并行boosting tree的工具。
XGBOOST和GBDT的区别:
- CART树复杂度:XGBoost考虑了树的复杂度,而GBDT未考虑;
- 损失函数:XGBoost是拟合上一轮损失函数的二阶导展开,而GBDT是上一轮损失函数的一阶导,所以前者的准确性和迭代次数较少;
- 多线程:XGBoost在选取最佳切分点时开启多线程进行,运行速度更快。
LightGBM算法
微软开源的一个梯度提升框架,主要体现在高效并行训练,速度比XGBoost快10倍,内存占用率为后者的1/6。它主要是通过以下方式来进行优化的:
- 基于Histogram直方图的决策树算法;
- 对Histogram直方图做差加速;
- 使用带深度限制的leaf-wise的叶子生长策略;
- 直接支持类别特征;
- 直接支持高效并行。
基于Histogram直方图的决策树算法
简单理解就是把连续值离散化为k个整数,从而构造一个直方图,那么在遍历数据的时候也是直接对直方图遍历寻找最优的划分点。这样虽然在一定程度上降低了精确性,但在内存消耗和计算速度上得到了很大的优化;同时由于决策树本身是弱模型,划分点的精确性影响不大,而且还能有效防止过拟合。
对Histogram直方图做差加速
通常构造直方图需要遍历叶子上的所有数据,但通过对直方图做差,只需要遍历直方图的k个桶。这样在构造一个叶子的直方图后,很容易就能得到兄弟叶子的直方图,速度又可以提升一倍。
带深度限制的leaf-wise的叶子生长策略
XGBoost采用level-wise的叶子生长策略,它可以进行多线程优化,也能控制模型复杂度,不容易过拟合,但它对同一层的叶子一视同仁,会导致很多增益低的也进行分裂和搜索,这就会带来很多没必要的开销。
lightGBM采用leaf-wise的叶子生成策略,它是找到叶子分裂增益最大的那个,进行分裂。这种方法在相同分裂次数的情况下,该方法误差更低,精度也更高。但相应的可能会产生太深的决策树,从而产生过拟合,因此需要增加一个最大深度限制。
直接支持类别特征
一般机器学习工具需要将类别特征转化为数值特征,这降低了空间和时间的效率,而lightGBM可以直接输入类别特征。
直接支持高效并行
特征并行:在每台机器上保存全部训练数据,不用进行数据垂直划分,在得到最佳划分后直接在本地执行,不用在机器之间进行通信。
数据并行:将直方图合并的任务分给不同的机器,降低通信和计算,并利用直方图做差进一步减少通信量。
投票并行:通过本地找出TOP k特征,这些基于投票筛选出来的特征可能是最优划分点,那么在合并的时候也只合并筛选出来的特征,从而降低通信。
lightGBM的特点:
优点:
- 速度快:遍历直方图降低时间复杂度;使用leaf-wise算法减少大量计算;采用特征并行、数据并行和投票并行,加快计算;对缓存进行优化,增加缓存命中率。
- 内存小:使用直方图算法将特征转变为bin值,少记录索引减少内存消耗;将特征存储变为存储bin值减少内存消耗;采用互斥特征捆绑算法减少特征数量。
缺点:
- 可能会长出较深的决策树,产生过拟合,需要使用深度限制防止过拟合;
- 传统boosting算法通过迭代会让误差越来越小,而lightGBM基于偏差算法,对噪点比较敏感;
- 没有将最优解的全部特征考虑进去,会出现考虑不全的情况。
到了这里,关于集成学习——Boosting算法:Adaboost、GBDT、XGBOOST和lightGBM的简要原理和区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!