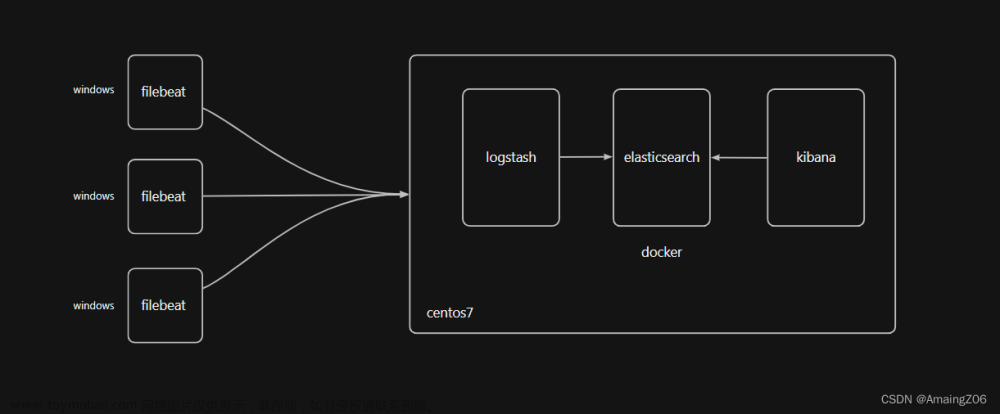
docker run -d \
--name=filebeat_7.14_0 \ #filebeat名称
--user=root \
--volume="/data/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml" \ #映射filebeat.yml配置
--volume="/data/filebeat/log:/usr/share/filebeat/log" \ #映射filebeat日志
--volume="/data/filebeat/data:/usr/share/filebeat/data" \ #映射filebeat数据
--volume="/data/log:/path/to/host/log" \ #映射主机的宿日志路径、很重要
docker.elastic.co/beats/filebeat:7.14.0 #filebeat版本
/data/filebeat:
[root@xx filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/to/host/log/net/zb/10.1.1.1* #真实宿主机路径是/data/log/net/zb/10.1.1.1*的日志
fields:
device_model: "test"
kafka_topic: "测试-topic" #卡卡夫卡 topic
#filebeat.config.modules:
# path: ${path.config}/modules.d/*.yml
# reload.enabled: false
#setup.template.settings:
# index.number_of_shards: 1
#setup.template.enabled: true
#setup.template.fields: fields.yml
#setup.template.overwrite: true
processors:
- drop_fields:
fields: ['agent', 'ecs', 'beat', 'input_type', 'tags', 'count', '@version', 'log', 'offset', 'type', 'host']
ignore_missing: false
output.kafka:
enabled: true
hosts: ["10.10.10.10:9092"] #输出到kafka中,写kafka的IP
topic: "%{[fields.kafka_topic]}"
compression: gzip
max_message_bytes: 1000000
python3测试有没有数据:
# -*- coding: utf-8 -*-
import sys
import json
from kafka import KafkaConsumer #pip3 install kafka-python文章来源:https://www.toymoban.com/news/detail-605463.html
for msg in KafkaConsumer('测试-topic',bootstrap_servers=['10.10.10.10:9092']):
jsonData = msg.value.decode('utf-8')
info = json.loads(jsonData)
print(info)
#
# print(len("cmdb-crm-CRMkehuguanli-prd"))文章来源地址https://www.toymoban.com/news/detail-605463.html
到了这里,关于filebeat到kafka示例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!