表格文字识别(异步接口)
图片转excel
百度ai官方文档:https://ai.baidu.com/ai-doc/OCR/Ik3h7y238
使用的是表格文字识别(异步接口),同步接口已经下线
 文章来源:https://www.toymoban.com/news/detail-605564.html
文章来源:https://www.toymoban.com/news/detail-605564.html
import requests
import json
import base64
import time
'''
文档:https://ai.baidu.com/ai-doc/OCR/Ik3h7y238
'''
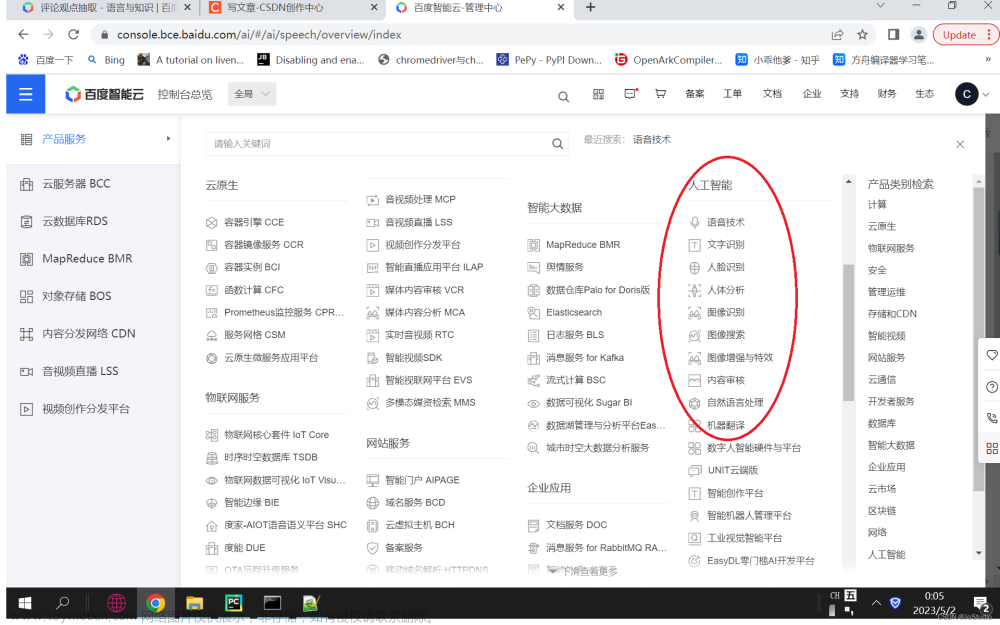
# 获取access_token地址:https://console.bce.baidu.com/ai/#/ai/ocr/app/list
def get_access_token():
client_id = "xxxxxxxxxxxxxxxxxx" # 你的apikey
client_secret = "xxxxxxxxxxxxxxxxxxxxxx" # 你的Secret Key
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(
client_id, client_secret)
response = requests.get(host).text
data = json.loads(response)
access_token = data['access_token']
return access_token
# 获取识别结果
def get_info(access_token):
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/request"
# 二进制方式打开图片文件
f = open('1.jpg', 'rb')
img = base64.b64encode(f.read()) # base64编码
params = {"image": img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
# if response:
# print(response.json())
data_1 = response.json()
return data_1
# 获取excel
def get_excel(requests_id, access_token):
headers = {'content-type': 'application/x-www-form-urlencoded'}
pargams = {
'request_id': requests_id,
'result_type': 'excel'
}
url = 'https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/get_request_result'
url_all = url + "?access_token=" + access_token
res = requests.post(url_all, headers=headers, params=pargams) # 访问链接获取excel下载页
info_1 = res.json()['result']['ret_msg']
excel_url = res.json()['result']['result_data']
excel_1 = requests.get(excel_url).content
print(excel_1)
with open('识别结果.xls', 'wb+') as f:
f.write(excel_1)
print(info_1)
def main():
print('正在处理中请稍后')
access_token = get_access_token()
data_1 = get_info(access_token)
try:
requests_id = data_1['result'][0]['request_id']
if requests_id != '':
print('识别完成')
except:
print('识别错误')
print('正在获取excel')
time.sleep(10) # 延时十秒让网页图片转excel完毕,excel量多的话,转化会慢,可以延时长一点
get_excel(requests_id, access_token)
main()
表格文字识别V2
图片/pdf转excel通用
import requests
import json
import base64
CLIENT_ID = "xxxxxxxxxxxxxxxxx" # 你的apikey,需要修改
CLIENT_SECRET = "xxxxxxxxxxxxxxxxxxxxx" # 你的Secret Key,需要修改
# 获取access_token
def get_access_token():
auth_url = 'https://aip.baidubce.com/oauth/2.0/token'
params = {
'grant_type': 'client_credentials',
'client_id': CLIENT_ID,
'client_secret': CLIENT_SECRET,
}
response = requests.post(auth_url, data=params)
data = response.json()
access_token = data.get('access_token')
if not access_token:
raise "请输入正确的client_id 和 client_secret"
return access_token
def save_excel(b64_excel, excel_name):
# 将base64编码的excel文件解码并保存为本地文件
excel = base64.b64decode(b64_excel)
with open(excel_name, 'wb') as f:
f.write(excel)
def to_excel(file_path, excel_name):
access_token = get_access_token()
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/table"
# 以二进制方式打开图片文件,并将其转换为base64编码
with open(file_path, 'rb') as f:
file = base64.b64encode(f.read())
ext = file_path.split('.')[-1]
if ext in ['jpg', 'jpeg', 'png', 'bmp']:
# 图片格式
data = {
"image": file,
"return_excel": 'true',
}
elif ext == 'pdf':
# pdf格式
data = {
"pdf_file": file,
"return_excel": 'true',
}
headers = {'content-type': 'application/x-www-form-urlencoded'}
# 发送POST请求进行表格文字识别
response = requests.post(request_url, params={'access_token': access_token}, data=data, headers=headers)
if response.ok:
data = response.json()
# 将返回的excel文件保存到本地
save_excel(data.get('excel_file', ''), excel_name)
print('转换完成')
else:
print('转换失败')
if __name__ == '__main__':
img_path = '1.png' # 要转换的图片文件名
pdf_path = 'table.pdf' # 要转换的pdf文件名
to_excel(file_path=img_path, excel_name='out_pic.xlsx') # 转换后的excel文件名
to_excel(file_path=pdf_path, excel_name='out_pdf.xlsx') # 转换后的excel文件名
 文章来源地址https://www.toymoban.com/news/detail-605564.html
文章来源地址https://www.toymoban.com/news/detail-605564.html
到了这里,关于python调用百度ai将图片识别为表格excel的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!