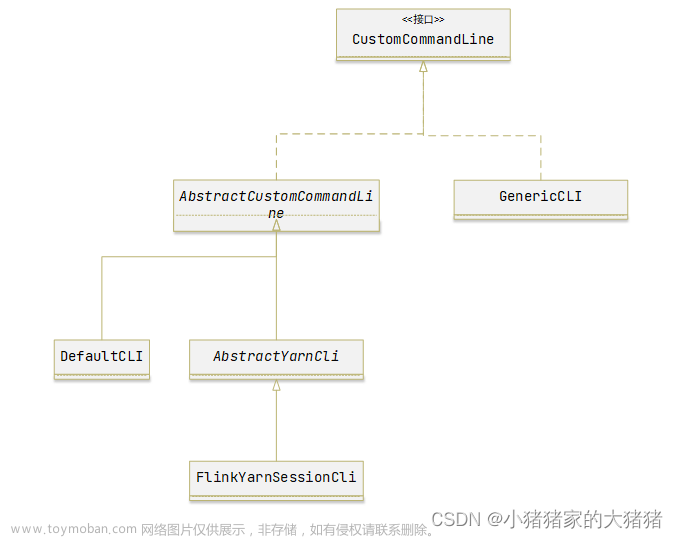
1、seatunnel简单介绍
seatunnel 是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于Apache Spark 和 Apache Flink之上。
seatunnel 让Spark和Flink的使用更简单,更高效。
注:当前版本用的是2.1.3版本 如果在github下载自己编译有问题 可在此地址下载编译好的文件seatunnel-2.1.3-bin包
特性
- 简单易用,灵活配置,无需开发
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
集成Spark和Flink官方教程
集成Spark教程
集成Flink教程
2、提交Spark任务
参考官方文档:https://interestinglab.github.io/seatunnel-docs/#/zh-cn/v2/spark/quick-start
案例:实现Hive表导出到ClickHouse
创建测试文件
vim /usr/local/apache-seatunnel-incubating-2.1.3/config/hive-console.confClickHouse建表
#配置Spark参数
spark { spark.sql.catalogImplementation = "hive"
spark.app.name = "hive2clickhouse"
spark.executor.instances = 30
spark.executor.cores = 1
spark.executor.memory = "2g"
spark.ui.port = 13000
}
input {
hive {
pre_sql = "select id,name,create_time from table"
table_name = "table_tmp"
}
}
filter {
convert {
source_field = "data_source"
new_type = "UInt8"
}
org.interestinglab.waterdrop.filter.Slice {
source_table_name = "table_tmp"
source_field = "id"
slice_num = 2
slice_code = 0
result_table_name = "table_8123"
}
org.interestinglab.waterdrop.filter.Slice {
source_table_name = "table_tmp"
source_field = "id"
slice_num = 2
slice_code = 1
result_table_name = "table_8124"
}
}
output {
clickhouse {
source_table_name="table_8123"
host = "ip1:8123"
database = "db_name"
username="username"
password="xxxxx"
table = "model_score_local"
fields = ["id","name","create_time"]
clickhouse.socket_timeout = 50000
retry_codes = [209, 210]
retry = 3
bulk_size = 500000
}
clickhouse {
source_table_name="table_8124"
host = "ip2:8123"
database = "db_name"
username="username"
password="xxxxx"
table = "model_score_local"
fields = ["id","name","create_time"]
clickhouse.socket_timeout = 50000
retry_codes = [209, 210]
retry = 3
bulk_size = 500000
}
}运行seatunnel将数据写入ClickHouse
/bin/start-seatunnel-spark.sh --master local --deploy-mode client --config/hive-console.conf3、提交Flink任务
参考文档:Document
案例1:Kafka到Kafka的数据同步
业务场景:对test_csv主题中的数据进行过滤,仅保留年龄在18岁以上的记录
env {
# You can set flink configuration here
execution.parallelism = 1
#execution.checkpoint.interval = 10000
#execution.checkpoint.data-uri = "hdfs://hadoop102:9092/checkpoint"
}
# 在source所属的块中配置数据源
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel-learn"
topics = test_csv
result_table_name = test
format.type = csv
schema = "[{\"field\":\"name\",\"type\":\"string\"},{\"field\":\"age\", \"type\": \"int\"}]"
format.field-delimiter = ";"
format.allow-comments = "true"
format.ignore-parse-errors = "true"
}
}
# 在transform的块中声明转换插件
transform {
sql {
sql = "select name,age from test where age > '"${age}"'"
}
}
# 在sink块中声明要输出到哪
sink {
kafkaTable {
topics = "test_sink"
producer.bootstrap.servers = "node1:9092"
}
}
启动Flink任务
bin/start-seatunnel-flink.sh --config config/kafka_kafka.conf -i age=18
案例2:Kafka 输出到Doris进行指标统计
业务场景:使用回话日志统计用户的总观看视频数,用户最常会话市场,用户最小会话时长,用户最后一次会话时间
Doris初始化操作
create database test_db;
CREATE TABLE `example_user_video` (
`user_id` largeint(40) NOT NULL COMMENT "用户id",
`city` varchar(20) NOT NULL COMMENT "用户所在城市",
`age` smallint(6) NULL COMMENT "用户年龄",
`video_sum` bigint(20) SUM NULL DEFAULT "0" COMMENT "总观看视频数",
`max_duration_time` int(11) MAX NULL DEFAULT "0" COMMENT "用户最长会话时长",
`min_duration_time` int(11) MIN NULL DEFAULT "999999999" COMMENT "用户最小会话时长",
`last_session_date` datetime REPLACE NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次会话时间"
) ENGINE=OLAP
AGGREGATE KEY(`user_id`, `city`, `age`)
COMMENT "OLAP"
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
;
seatunnel任务配置:文章来源:https://www.toymoban.com/news/detail-605652.html
env {
execution.parallelism = 1
}
source {
KafkaTableStream {
consumer.bootstrap.servers = "node1:9092"
consumer.group.id = "seatunnel5"
topics = test
result_table_name = test
format.type = json
schema = "{\"session_id\":\"string\",\"video_count\":\"int\",\"duration_time\":\"long\",\"user_id\":\"string\",\"user_age\":\"int\",\"city\":\"string\",\"session_start_time\":\"datetime\",\"session_end_time\":\"datetime\"}"
format.ignore-parse-errors = "true"
}
}
transform{
sql {
sql = "select user_id,city,user_age as age,video_count as video_sum,duration_time as max_duration_time,duration_time as min_duration_time,session_end_time as last_session_date from test"
result_table_name = test2
}
}
sink{
DorisSink {
source_table_name = test2
fenodes = "node1:8030"
database = test_db
table = example_user_video
user = atguigu
password = 123321
batch_size = 50
doris.column_separator="\t"
doris.columns="user_id,city,age,video_sum,max_duration_time,min_duration_time,last_session_date"
}
}
启动flink任务文章来源地址https://www.toymoban.com/news/detail-605652.html
bin/start-seatunnel-flink.sh --config config/kafka_doris.conf到了这里,关于采用seatunnel提交Flink和Spark任务的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!