1、JUC高并发容器
文章来源地址https://www.toymoban.com/news/detail-605751.html
1.1、为什么需要JUC高并发容器
早期的同步容器一般使用 Vector、HashTable、java.util.Collections ,这些同步容器实现线程安全的方式是:在需要同步访问的方法上添加关键字synchronized。
synchronized 在线程没有发生争用的场景下处于偏向锁的状态,其性能是非常高的。但是,一旦发生了线程争用,synchronized 会由偏向锁膨胀成重量级锁,在抢占和释放时发生 CPU 内核态与用户态切换,所以削弱了并发性,降低了吞吐量,而且会严重影响性能。正因为如此,JUC提供了一套高并发容器类。
1.2、什么是 JUC 高并发容器
文章来源:https://www.toymoban.com/news/detail-605751.html
JUC高并发容器是基于非阻塞算法(或者无锁编程算法)实现的容器类,无锁编程算法主要通过 CAS(保障操作的原子性) + Volatile(保障变量内存的可见性)组合实现。
无锁编程算法的主要优点如下:
- ① 开销较小:不需要在内核态和用户态之间切换进程。
- ② 读写不互斥:只有写操作需要使用基于CAS机制的乐观锁,读读操作之间可以不用互斥。
JUC包中提供了List、Set、Queue、Map各种类型的高并发容器。
-
List
JUC包中的高并发List主要有CopyOnWriteArrayList,对应的基础容器为ArrayList。
CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。在读多写少的场景中,其性能远远高于ArrayList的同步包装容器。
-
Set
JUC包中的Set主要有 CopyOnWriteArraySet 和 ConcurrentSkipListSet 。
- CopyOnWriteArraySet继承自AbstractSet类,对应的基础容器为 HashSet 。其内部组合了一个CopyOnWriteArrayList对象,它的核心操作是基于CopyOnWriteArrayList实现的。
- ConcurrentSkipListSet是线程安全的有序集合,对应的基础容器为TreeSet。它继承自AbstractSet,并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的。
-
Map
JUC包中Map主要有 ConcurrentHashMap 和 ConcurrentSkipListMap 。
- ConcurrentHashMap 对应的基础容器为HashMap。JDK 6中的ConcurrentHashMap 采用一种更加细粒度的“分段锁”加锁机制,JDK8中采用CAS无锁算法。
- ConcurrentSkipListMap 对应的基础容器为TreeMap。其内部的 Skip List(跳表)结构是一种可以代替平衡树的数据结构,默认是按照Key值升序的。
-
Queue
JUC包中的 Queue 的实现类包括三类:单向队列、双向队列和阻塞队列。
- ConcurrentLinkedQueue 是基于列表实现的单向队列,按照 FIFO(先进先出)原则对元素进行排序。新元素从队列尾部插入,而获取队列元素则需要从队列头部获取。
- ConcurrentLinkedDeque 是基于链表的双向队列,但是该队列不允许null元素。作为双向队列,ConcurrentLinkedDeque 可以当作“栈”来使用,并且高效地支持并发环境。
- ArrayBlockingQueue:基于数组实现的可阻塞的FIFO队列。
- LinkedBlockingQueue:基于链表实现的可阻塞的FIFO队列。
- PriorityBlockingQueue:按优先级排序的队列。
- DelayQueue:按照元素的Delay时间进行排序的队列。
- SynchronousQueue:无缓冲等待队列。
1.3、CopyOnWriteArrayList
JUC包中的高并发 List 主要有 CopyOnWriteArrayList ,对应的基础容器为ArrayList。CopyOnWriteArrayList 相当于线程安全的 ArrayList,它实现了List接口。在读多写少的场景中,其性能远远高于 ArrayList 的同步包装容器。
写时复制(Copy On Write,COW)的主要 优点 是:如果没有修改器去修改资源,就不会创建副本,因此多个访问器可以共享同一份资源。其 核心思想 是:如果有多个访问器(Accessor)访问一个资源(如内存或者磁盘上的数据存储),它们会共同获取相同的指针指向相同的资源,只要有一个修改器(Mutator)需要修改该资源,系统就会复制一份专用副本(Private Copy)给该修改器,而其他访问器所见到的最初资源仍然保持不变,修改的过程对其他访问器都是透明的(Transparently)。
-
CopyOnWriteArrayList 的优点
CopyOnWriteArrayList 有一个显著的优点,那就是
读取、遍历操作不需要同步,速度会非常快。所以,CopyOnWriteArrayList适用于读操作多、写操作相对较少的场景(读多写少),比如可以在进行“黑名单”拦截时使用CopyOnWriteArrayList。 -
CopyOnWriteArrayList 和 ReentrantReadWriteLock 的比较
CopyOnWriteArrayList 和 ReentrantReadWriteLock 读写锁的思想非常类似,即读读共享、写写互斥、读写互斥、写读互斥。但是前者相比后者的更进一步:为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,而且写入也不会阻塞读取操作,只有写入和写入之间需要进行同步等待,读操作的性能得到大幅度提升。
CopyOnWriteArrayList的写入操作 add() 方法,在执行时加了独占锁以确保只能有一个线程进行写入操作,避免多线程写的时候会复制出多个副本。在每次进行添加操作时,CopyOnWriteArrayList底层都是重新复制一份数组,再往新的数组中添加新元素,待添加完了,再将新的array引用指向新的数组。当add()操作完成后,array的引用就已经指向另一个存储空间了。
JDK8 源码:
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
每次添加元素的时候都会重新复制一份新的数组,这样增加了内存的开销,如果容器的写操作比较频繁,那么其开销就比较大。所以,在实际应用的时候,CopyOnWriteArrayList并不适合进行添加操作。
使用CopyOnWriteArrayList容器,可以在进行元素迭代的同时,进行元素添加操作。代码示例:
import lombok.extern.slf4j.Slf4j;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.concurrent.TimeUnit;
public class ListDemo {
public static void main(String[] args) throws InterruptedException {
List<String> notSafeList = Arrays.asList("a", "b", "c");
//创建一个CopyOnWriteArrayList队列
List<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
copyOnWriteArrayList.addAll(notSafeList);
//并发执行目标
ListThread listThread = new ListThread(copyOnWriteArrayList);
for (int i = 0; i < 10; i++) {
new Thread(listThread, "线程" + i).start();
}
//主线程等待
TimeUnit.SECONDS.sleep(2);
}
}
@Slf4j
class ListThread implements Runnable{
// 并发操作的 目标集合
List<String> targetList = null;
public ListThread (List<String> list) {
this.targetList = list;
}
@Override
public void run() {
Iterator<String> iterator = targetList.iterator();
//迭代操作
while (iterator.hasNext()) {
// 在迭代操作时,进行列表的修改
String threadName = Thread.currentThread().getName();
targetList.add(threadName);
log.info("开始往同步队列加入线程名称:{}", threadName);
}
}
}
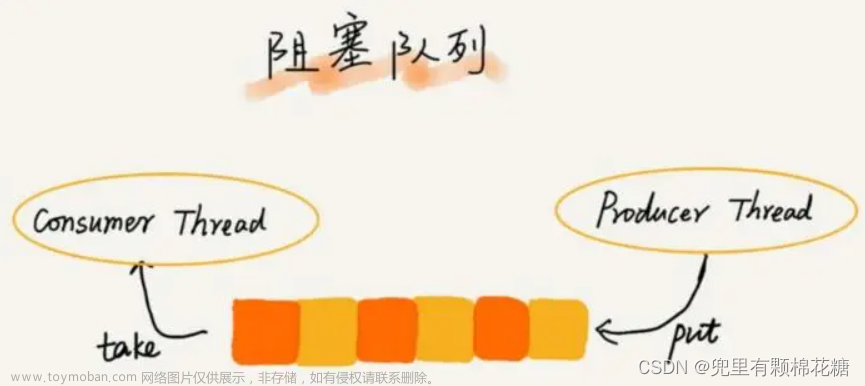
1.4、BlockingQueue
BlockingQueue的常用实现类有 ArrayBlockingQueue、DelayQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue 等。
阻塞队列与普通队列(ArrayDeque等)之间的最大不同点,在于阻塞队列提供了阻塞式的添加和删除方法。
- 阻塞添加
阻塞添加是指当阻塞队列元素已满时,队列会阻塞添加元素的线程,直到队列元素不满时,才重新唤醒线程执行元素添加操作。 - 阻塞删除
阻塞删除是指在队列元素为空时,删除队列元素的线程将被阻塞,直到队列不为空时,才重新唤醒删除线程,再执行删除操作。
1.4.1、阻塞队列的常用方法
阻塞队列三类方法的特征:
| 方法类别 | 抛出异常 | 特殊值 | 阻塞 | 限时阻塞 |
|---|---|---|---|---|
| 添 加 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 删 除 | remove() | poll() | take() | poll(time,unit) |
| 获取元素 | element() | peek() | 不可用 | 不可用 |
特征说明:
-
抛出异常 :如果试图的操作无法立即执行,就抛出一个异常。
-
特殊值 :如果尝试的操作无法立即执行,就返回一个特定的值(通常是 true/false)。
-
阻塞 :如果尝试的操作无法立即执行,该方法的调用就会发生阻塞,直到能够执行。
-
限时阻塞 :如果尝试的操作无法立即执行,该方法的调用就会发生阻塞,直到能够执行,但等待时间不会超过设置的上限值。
public interface BlockingQueue<E> extends Queue<E> {
/**
* 将指定的元素添加到此队列的尾部
* 在成功时返回true,如果此队列已满,就抛出
**/
IllegalStateException boolean add(E e);
/**
* 非阻塞式添加:将指定的元素添加到此队列的尾部(如果立即可行且不会超过该队列的容量)
* 如果该队列已满,就直接返回
**/
boolean offer(E e);
/**
* 限时阻塞式添加:将指定的元素添加到此队列的尾部
* 如果该队列已满,那么在到达指定的等待时间之前,添加线程会阻塞,等待可用的时间,该方法可中断
**/
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
/**
* 阻塞式添加:将指定的元素添加到此队列的尾部,如果该队列已满,就一直等待(阻塞)
**/
void put(E e) throws InterruptedException;
/**
* 从此队列中移除指定元素,返回删除是否成功
**/
boolean remove(Object o);
/**
* 非阻塞式删除:获取并移除此队列的头部,如果没有元素就直接返回null(空)
**/
E poll() throws InterruptedException;
/**
* 阻塞式删除:获取并移除此队列的头部,如果没有元素就等待(阻塞)
* 直到有元素,将唤醒等待线程执行该操作
**/
E take() throws InterruptedException;
/**
* 限时阻塞式删除:获取并移除此队列的头部,在指定的等待时间前一直等
* 待获取元素,超过时间,方法将结束
**/
E poll(long timeout, TimeUnit unit) throws InterruptedException;
/**
* 获取但不移除此队列的头元素,没有则抛出异常NoSuchElementException
**/
E element();
/**
* 获取但不移除此队列的头元素,如果此队列为空,就返回null
**/
E peek();
}
1.4.2、ArrayBlockingQueue
ArrayBlockingQueue 是一个常用的阻塞队列,是基于数组实现的,其内部使用一个定长数组来存储元素。除了一个定长数组外,ArrayBlockingQueue 内部还保存着两个整型变量,分别标识着队列的头部和尾部在数组中的位置。ArrayBlockingQueue 的添加和删除操作共用同一个锁对象,由此意味着添加和删除无法并行运行。
为什么ArrayBlockingQueue比LinkedBlockingQueue更加常用?
ArrayBlockingQueue在添加或删除元素时,不会产生或销毁任何额外的Node(节点)实例。而 LinkedBlockingQueue 会生成一个额外的 Node 实例。在长时间、高并发处理大批量数据的场景中,LinkedBlockingQueue 产生的额外 Node 实例会加大系统的GC压力。
构造函数:
/**
* 默认非公平阻塞队列
* @param capacity 这个队列容量
* @throws IllegalArgumentException if {@code capacity < 1}
*/
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
/**
*
* @param capacity 这个队列容量
* @param fair 是否公平阻塞队列,如果true然后队列访问线程阻塞在插入或移除,
* 以FIFO的顺序处理;如果 false存取顺序是不确定的。
* @throws IllegalArgumentException 如果 capacity小于 c.size(),或小于1。
*/
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
// 根据fair参数构造公平锁
lock = new ReentrantLock(fair);
// 有元素加入,队列为非空
notEmpty = lock.newCondition();
// 有元素被取出,队列为未满
notFull = lock.newCondition();
}
/**
*
* @param capacity 这个队列容量
* @param fair 是否公平阻塞队列,如果true然后队列访问线程阻塞在插入或移除,
* 以FIFO的顺序处理;如果 false存取顺序是不确定的。
* @param c 最初包含元素的集合
* @throws IllegalArgumentException 如果 capacity小于 c.size(),或小于1。
* @throws NullPointerException 如果指定集合或其任何元素都是空的
*/
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
final Object[] items = this.items;
int i = 0;
try {
for (E e : c)
items[i++] = Objects.requireNonNull(e);
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
代码示例:
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ArrayBlockingQueue;
/**
* 数据缓存区
*/
@Slf4j
public class DataBuffer<T> {
// 数据缓存区,指定阻塞队列的长度为 10
public static final int MAX_AMOUNT = 10;
// 使用阻塞队列保存数据
private ArrayBlockingQueue<T> queue = new ArrayBlockingQueue<>(MAX_AMOUNT);
// 向数据区增加一个元素,委托给阻塞队列
public void add(T t) throws InterruptedException {
// 直接委托给 ArrayBlockingQueue 阻塞队列去添加元素
// put(T t) 方法,阻塞式添加:将指定的元素添加到此队列的尾部,如果该队列已满,就一直等待(阻塞)
queue.put(t);
log.info("数据缓存区添加元素成功,{}", t);
}
// 从数据区取出一个商品,委托给阻塞队列
public T fetch() throws InterruptedException {
// 取出操作直接委托给 ArrayBlockingQueue 阻塞队列
// take() 方法 是阻塞式删除:获取并移除此队列的头部,如果没有元素就等待(阻塞)
T t = queue.take();
log.info("数据缓存区取出元素成功,{}", t);
return t;
}
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @description: 生产的产品
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Good implements Cloneable {
private String name;
@Override
public Good clone() {
Good good = null;
try {
good = (Good) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return good;
}
}
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Callable;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @description: 生产者
*/
@Slf4j
public class Producer implements Runnable {
// 生产次数计数器
static final AtomicInteger TURN = new AtomicInteger(1);
// 生产的动作
Callable action = null;
// 生产者生产,默认耗时2s
private int gap = 2;
public Producer(Callable action, int gap) {
this.action = action;
this.gap = gap;
}
@Override
public void run() {
// 这里一直生产
while (true) {
try {
//执行生产动作
Object out = action.call();
// 模拟生产者生产耗时
TimeUnit.SECONDS.sleep(gap);
//增加生产轮次
TURN.incrementAndGet();
//输出生产的结果
if (null != out) {
log.info("线程{}->第{}次生产:{}",
Thread.currentThread().getName(), TURN.get(), out);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Callable;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class Consumer extends Thread {
//消费总次数计数器
static final AtomicInteger TURN = new AtomicInteger(0);
//消费的动作
Callable action = null;
//消费默认消费耗时3s
int gap = 3;
public Consumer(Callable action, int gap) {
this.action = action;
this.gap = gap;
}
@Override
public void run() {
while (true) {
//增加消费次数
TURN.incrementAndGet();
try {
//执行消费动作
Object out = action.call();
if (null != out) {
log.info("线程{}->第{}次消费:{}",
Thread.currentThread().getName(),TURN.get(), out);
}
// 模拟消费者消费耗时
TimeUnit.SECONDS.sleep(gap);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class ArrayBlockingQueuePetStore {
public static void main(String[] args) {
// 新建一个缓存区
DataBuffer<Good> dataBuffer = new DataBuffer<>();
Good goodBase = new Good("蓝莓");
final AtomicInteger goodCount = new AtomicInteger(0);
// 定义生产者
Callable<Good> produceAction = () -> {
//首先生成一个随机的商品
Good good = goodBase.clone();
int aa = goodCount.incrementAndGet();
good.setName(good.getName() + aa);
//将商品加上共享数据区
dataBuffer.add(good);
return good;
};
// 定义消费者
Callable<Good> consumerAction = () -> {
// 从缓存区获取商品
Good goods = null;
goods = dataBuffer.fetch();
return goods;
};
// 定义线程池
ExecutorService pool = Executors.newFixedThreadPool(3);
// 执行逻辑,假定共3个线程,其中有2个消费者,但是只有1个生产者
final int consumerTotal = 2;
final int produceTotal = 3;
/** 这个地方如果先执行 pool.submit(new Producer(produceAction, 2)); 循环,
* 会导致,生产者任务数瞬间达到线程池 pool 的最大线程数3,消费者者任务进入pool的 LinkedBlockingQueue
* 生产者Producer 的 run.while 会导致一直占用线程
* 然后生产的任务瞬间达到缓存区dataBuffer阻塞队列queue的最大长度10,并继续put,出现阻塞。
* 由于 ArrayBlockingQueue 的添加和删除操作共用同一个锁对象,且 queue 无法消费,而 put 又处于堵塞,
* 所以这段程序一直会堵塞下去 。 可以尝试先执行消费者的遍历逻辑,或pool 的最大线程数大于 生产者的任务数**/
for (int i = 0; i < produceTotal; i++) {
//生产者线程每生产一个商品,需要1秒
pool.submit(new Producer(produceAction, 2));
}
for (int i = 0; i < consumerTotal; i++) {
//消费者线程每消费一个商品,需要两秒
pool.submit(new Consumer(consumerAction, 1));
}
log.info("执行主线程逻辑");
pool.shutdown();
}
}
1.4.3、LinkedBlockingQueue
LinkedBlockingQueue 是基于链表的阻塞队列,其内部也维持着一个数据缓冲队列(该队列由一个链表构成)。LinkedBlockingQueue 对于添加和删除元素,分别采用了独立的锁来控制数据同步,所以在高并发的情况下,生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
在新建一个LinkedBlockingQueue对象时,若没有指定其容量大小,则LinkedBlockingQueue 会默认一个类似无限大小的容量(Integer.MAX_VALUE)。需要注意生产者速度大于消费者速度的场景,也许还没有等到队列满阻塞产生,系统内存就已经被消耗殆尽了。
1.4.4、DelayQueue
DelayQueue 中的元素只有当其指定的延迟时间到了,才能够从队列中获取该元素。DelayQueue 是一个没有大小限制的队列。所以往队列中添加数据的操作(生产者)永远不会被阻塞,而只有获取数据的操作(消费者)才会被阻塞。
DelayQueue的使用场景较少,常见场景是使用 DelayQueue 来管理一个超时未响应的连接队列。
1.4.5、PriorityBlockingQueue
PriorityBlockingQueue 是基于优先级的阻塞队列。其并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。要特别注意:生产者生产数据的速度,绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间,同没有指定长度的 LinkedBlockingQueue 一样。
1.4.6、SynchronousQueue
SynchronousQueue 是比较独特的队列,其本身是没有容量大小。举例:如果我放一个数据到队列中,我是不能够立马返回的,我必须等待别人把我放进去的数据消费掉了,才能够返回。对单个消息的响应要求高的场景可以使用SynchronousQueue。
SynchronousQueue 有两种模式:公平模式和非公平模式。
-
公平模式的SynchronousQueue会采用公平锁,并配合一个FIFO队列来阻塞多余的生产者和消费者,从而体现出整体的公平特征。
-
非公平模式(默认情况)的SynchronousQueue采用非公平锁,同时配合一个LIFO堆栈(TransferStack内部实例)来管理多余的生产者和消费者。对于非公平模式,如果生产者和消费者的处理速度有差距,就很容易出现线程饥渴的情况,即可能出现某些生产者或者消费者的数据永远都得不到处理。
1.5、ConcurrentHashMap
ConcurrentHashMap是一个常用的高并发容器类,也是一种线程安全的哈希表。
ConcurrentHashMap 和同步容器 HashTable 的主要区别在锁的类型和粒度上。
HashTable 实现同步是利用synchronized关键字进行锁定的,其实是针对整张哈希表进行锁定的,即每次锁住整张表让线程独占,虽然解决了线程安全问题,但是造成了巨大的资源浪费。当一个线程访问HashTable的同步方法时,其他访问HashTable同步方法的线程就会进入阻塞或轮询状态。若有一个线程在调用put()方法添加元素,则其他线程不但不能调用put()方法添加元素,而且不能调用get()方法来获取元素,相当于将所有的操作串行化。所以,HashTable的效率非常低下。
JDK 1.8的ConcurrentHashMap引入红黑树的原因是:链表查询的时间复杂度为O(n),红黑树查询的时间复杂度为O(log(n)),所以在节点比较多的情况下,使用红黑树可以大大提升性能。
线程系列博文:
线程系列 1 - 线程基础
线程系列 2 - 并发编程之线程池 ThreadPool 的那些事
线程系列 3 - 关于 CompletableFuture
线程系列 4 - synchronized 和线程间的通信
线程系列 5 - CAS 和 JUC原子类
线程系列 6 - JUC相关的显示锁
.
到了这里,关于线程系列 7 - JUC高并发容器类的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!