✨个人主页: 北 海
🎉所属专栏: C++修行之路
🎃操作环境: Visual Studio 2022 版本 17.6.5

🌇前言
位图(bitset)是一种特殊的数据结构,仅仅依靠 0、1 表示当前位置是否有数据存在,常用于对查找速度和存储空间有着高要求的场景中,除此之外,位图还可以配合宏定义,实现同时传递多个参数,比如系统调用 open,其中的参数2(打开方式)就是一个简单的位图结构
棋盘中棋子表示当前位置是否被占用

🏙️正文
位图可以用来解决实际问题,比如下面这道面试题就需要借助位图
1、问题一
给出
40亿个不重复的无符号整数(无序),再给出一个无符号整数,判断此数是否存在于40亿个无符号整数中
这是一道来自【腾讯】的面试题,题目要求很简单:判断给出的数是否存在
如果按照常规思路:存储数据,排序后查找,首先得先有一个足够大的数组存储这些数据
一个无符号整型大小是 4 字节,40 亿个无符号整型就是:40 * 4 = 160 亿字节,转换一下可知:大约需要 16 GB 的空间(10 亿字节约占 1 GB 空间)
还好,现在的笔记本普遍内存都有 16 GB,但是总不能把这些空间全部用来存数据吧,操作系统不跑了?编译软件不运行了?显然这种方法不现实

可能有的人觉得加装内存条就行了,确实,解决现在这个问题可以,但如果把数据量提至 80亿 呢?还不是照样不够,因此 直接在运行时开辟空间存储数据不可取
此时有人想到了第二种方法:既然内存不够,那我把数据持久化(写入文件)总行了吧,查找的时候读取文件就行了吧
当然可以,把这点数据存储在硬盘中随便存,读取也很方便,无非就是文件流操作嘛,但是此时有了一个新的问题:时间问题
总所周知,IO 是十分影响效率的,在 《Linux 进程信号【信号产生】》中我们就做过相关实验,得出取消 IO 前后,性能差距约 1w 倍,换作文件读取,可想而知得有多慢
并且由于数据无序,只能暴力遍历,耗费时间: 存储数据 + 遍历数据 + IO 的额外开销,这个方案也是不可取的

既然是腾讯的题,那其中肯定有坑,常规思路是无法很好地解决问题的,此时就需要借助我们今天的主角 位图 了

2、位图概念
位图 是个啥?位图 是 哈希思想 的一种应用,哈希表 映射数据时使用的是 vector,而 位图 映射数据时使用的是 比特位,没错,就是只能表示 0 和 1 的比特位(使用直接定址法,只能判断整型)
为什么 位图 能解决这种海量数据问题?
因为位图是哈希的应用,查找速度非常快,并且因为位图使用的是最小的单元:比特,空间利用率极高,而这就是【腾讯】这道面试题的最优解
解题思路:首先 40 亿个无符号的整数,重点在 无符号,这就意味着借助下标可以映射所有的数,无符号整型的最大值为 UINT_MAX(4294967295),这 40 亿个数据的范围 [0, UINT_MAX]

题目不过是 验证某数是否存在,因此我们可以直接创建一个大小为 UINT_MAX 的 位图 结构,将 40 亿个数统统存进去(重复数据不影响),存储完毕后,直接利用 位图 的特性:极速查找(哈希映射),就可以在 O(1) 时间内解决问题
至于内存占用,UINT_MAX 大约相当于 512 mb,就这点内存占用,随便给(某鹅厂应用占用内存随便都是几百兆)
位图的工作原理

在 C++ 中提供了位图结构 bitset(需要包含头文件 <bitset>)


3、位图的模拟实现
注:模拟实现时,只是简单实现,旨在理解位图的原理,与库中的 bitset 存在较大差异
3.1、基本思路
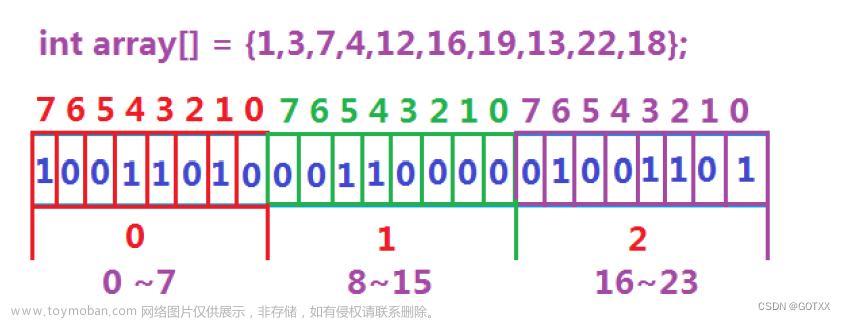
位图 的原理其实十分简单,本质上就是 开辟了一个大小为 N,类型为 Type 的数组
获取值位于哪一个下标中:Val / TypeSize
获取值位于哪一个具体比特位:Val % TypeSize
注:Val 是待 设置/重置/判断 的值,TypeSize 是类型 Type 所占比特位数
感觉有点像 哈希桶(使用开散列实现的哈希表),首先是找到位于哪一个 桶 中,然后去 桶 中遍历查找,不过这里的 桶 是 下标,表示属于数组中的哪一个元素,桶中的值 表示元素中的 比特位
千言万语不如一张图说明问题:

所以我们模拟实现的 位图 本质上就是一个 vector<char> 的数组,不过此时使用的是 比特位
结构如下:
//非类型模板参数,这里的含义是比特位的总个数
template<size_t N>
class bitset
{
enum { SIZE = 8 }; //char 的大小
public:
//初始化(开辟足量的空间)
bitset()
{
//除 8 是因为此时基本类型为 char
//加 1 是为了避免不能被整除时,造成比特位丢失,宁可多开,也不能缺失
_bits.resize(N / SIZE + 1, 0);
}
//其他默认成员函数不必写了,会自动调用 vector 的
private:
vector<char> _bits;
};
为什么要选 char ?
在 C语言 阶段,我们学习过一个知识点:大小端字节序,对于多字节的数据类型,诸如 int 存在大小端问题,比如 int a = 1
在大端机器中为:00 00 00 01
而在小端机器中为:01 00 00 00
不同机器中的二进制位排列方式略有差异(后续位运算依赖于二进制的排列方式),为了确保兼容性,我们可以直接使用 char,因为它就 1 字节(8 比特),不存在大小端字节序问题;并且 8 比特位足够少,便于学习理解位图结构
3.2、set
首先来看看 如何添加数据
位图 中没有直接插入数据的概念,取而代之的是将数据对应的比特位置为 1
假设现在 位图 Bit 的大小为 32 bit,待设置的数据为 28
首先获取具体的下标:i = 28 / 8 = 3
其次获取具体的比特位:j = 28 % 8 = 4
现在只需要把 Bit[3] 元素的第五个比特位(下标为 4)置为 1 即可成功设置 数据 28
这里考虑冗余的情况,即使目标位置为 1,照样置为 1
想要把某个比特位置为 1 可以使用 | 进行位运算:遇 1 变 1
因此 set 数据 28 时可以这样做:Bit[3] |= (1 << 4),如下图所示

将上述逻辑转化为代码,可得到 set 函数的实现:
//设置数据
void set(size_t val)
{
//首先获取下标 i
size_t i = val / SIZE;
//然后获取具体比特位 j
size_t j = val % SIZE;
//置 1
_bits[i] |= (1 << j);
}
注意:此处的具体比特位 j 并非代表 _bits[i] 元素中比特位的下标,而是 下标 + 1,比如 j = 4,表示的是 _bits[i] 元素中的第 4 个比特位,此时的比特位下标为 3,因为下标是从 0 开始的
3.3、reset
有 设置 就要有 重置(取消),也就是 reset
设置 的目的是 将指定的比特位置 1,而 重置 的目的是 把指定的比特位重置 0
至于获取 下标 和 比特位,和 设置 一样,或者说 位图 中的基本操作都离不开这两步
首先获取具体的下标:i = 28 / 8 = 3
其次获取具体的比特位:j = 28 % 8 = 4
将某个比特位置为 0,可以使用 & 进行位运算:遇 0 变 0
下面把之前 设置 的 28 进行 重置:Bit[3] &= ~(1 << 4),如下图所示

reset 的代码实现如下:
//重置数据
void reset(size_t val)
{
//首先获取下标 i
size_t i = val / SIZE;
//然后获取具体比特位 j
size_t j = val % SIZE;
//置 0
_bits[i] &= ~(1 << j);
}
这里不必担心 优先级问题,因为所有的 xxx= 优先级 都是很低的,所以可以保证计算出 ~(1 << j) 后才对 _bits[i] 进行 与等 运算
3.4、test
位图 中的必备功能:判断某个数据是否位于位图中(test)
这是 位图 的核心功能,毕竟 位图 的主要作用就是 判断某个数在不在
- 存在:对应的比特位为
1 - 不存在:对应的比特位为
0
一样的老套路:获取 下标 和 比特位,这里依旧请出老演员 28
首先获取具体的下标:i = 28 / 8 = 3
其次获取具体的比特位:j = 28 % 8 = 4
如何判断在不在?
简答,如果存在的话,对应的比特位肯定为 1,我们只需要把该位置的其他比特位置为 0,再判断该元素是否为 0 即可
可以这样操作:Bit[3] & (1 << 4)

test 的代码实现如下:
//判断是否存在
bool test(size_t val) const //这里直接使用 const 修饰,避免被修改
{
//首先获取下标 i
size_t i = val / SIZE;
//然后获取具体比特位 j
size_t j = val % SIZE;
return _bits[i] & (1 << j); //返回的是临时变量,真正的元素不会被修改
}
注意:此时不能使用 &=,不能改变原来的比特位状态,因为这里只是判断是否存在!
3.5、代码测试
切忌 纸上谈兵,下面来看看 位图 是否有用
void testBitSet1()
{
Yohifo::bitset<10> Bit; //创建可容纳 [0, 10]数值 的位图
for (int i = 0; i <= 10; i++)
{
//这里设置奇数
if (i % 2)
Bit.set(i);
}
//判断一下 [0, 10] 有多少数存在
for (int i = 0; i <= 10; i++)
{
if (Bit.test(i))
cout << i << "存在" << endl;
else
cout << i << "不存在" << endl;
}
}

程序正常运行
为什么之前开空间时要 +1?
一是为了避免不能被整除时,比特位的丢失,比如 10 / 8 = 1,如果不 +1,显然 第9、第10 个比特位都没办法使用,所以 +1 多开一点空间可以避免这个问题。二是即使能被整除,也要保证 N 也能正常存入,比如 16 / 8 = 2,第 1~20 个比特位都可用,数据范围为 [0, 20),为了使 20 也能被顺利使用,可以多开一个空间。总的来说,有一点点浪费,但绝对是 利大于弊
接下来简单验证下存 40 亿个无符号整数只需要 约 512 mb 空间
注:传递 -1 时,因为参数类型为 size_t ,会隐式类型转换为 UINT_MAX;当然,直接传递 UINT_MAX 也是可以的
void testBitSet2()
{
Yohifo::bitset<-1> Bit; //创建可容纳 [0, UINT_MAX]数值 的位图
//Yohifo::bitset<UINT_MAX> Bit; //创建可容纳 [0, UINT_MAX]数值 的位图
while (true); //查看任务管理器中的内存占用情况
}

所以说,用 位图 可以解决 【腾讯】的那一道海量数据面试题,同时也是最优解,查找速度为 O(1)
注意:此时的测试环境为 x86,x64 环境下会报错
4、问题二
还有一个与开篇的问题相似的姊妹问题
给出
100亿个不重复的无符号整数(无序),设计算法找到其中只出现一次的数
数据量变大了一倍多,没事,再多开一点,需要约 1.2 GB 的内存空间,此时内存不是问题的重点,重点在于如何设计 算法
对于这种在两堆数中找只出现一次的数,避免不了同时遍历两堆数,所以我们需要 2 个 位图,并且大小都为 100 亿,总占用约 2.4 GB 的内存空间
解题思路:二进制,我们把 位图1 看作高位,位图2 看作低位,第一次出现时,给 位图2 进行设置,后续第二次乃至第N次出现时,重置 位图2,设置 位图1;经过这样操作后,只要是 位图2 为 1,就说明该数仅出现了一次
约定:
0 0没有出现0 1只出现一次1 0出现多次
转换成代码如下(这里直接封装成一个类了)
template<size_t N>
class twoBitSet
{
public:
void twoSet(size_t val)
{
//约定:1 0 表示出现过多次(位图2不存在值),0 1 表示只出现过一次(位图2存在值)
if (_bs1.test(val) == false && _bs2.test(val) == false)
_bs2.set(val); //第一次出现,位图2 置 1
else if (_bs1.test(val) == false && _bs2.test(val) == true)
{
//此时为第二次或更多次出现,往前进位
_bs1.set(val);
_bs2.reset(val);
}
}
void print()
{
//输出只出现一次的数字
//判断 位图2 就好了
for (int i = 0; i <= N; i++)
{
if (_bs2.test(i) == true)
{
std::cout << i << " " << std::endl;
}
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
通过下面这个 demo 测试一下
void testTwoBitSet1()
{
int a[] = { 3, 45, 53, 32, 32, 43, 3, 2, 5, 2, 32, 55, 5, 53, 43, 9, 8, 7, 8 };
Yohifo::twoBitSet<100> Bits; //最大的值不过 100,所以 100 足够了
for (auto e : a)
{
Bits.twoSet(e);
}
Bits.print();
}

这样就可以解决问题了
5、问题三
给两个文件,分别有
100亿个整数(无序),我们只有1 GB内存,如何找到两个文件交集?
此时只有 1 GB 的可用空间,意味着我们只有一个 位图(100 亿整数中有大量重复的数据,至多有 42 亿多个数,所以 1 GB 空间足够了)
解决方案一:先读取其中一个文件,将数据设置入 位图 中;然后再读取另一个文件,此时是判断第二个文件中的数据是否存在于 位图 中,如存在,就说明是交集
这种方案面临一个问题:存在重复的值,比如 文件1{1, 2,},文件2{1, 3, 1, 2},此时得出的交集为 {1, 1, 2},交集中是没有重复值的,想要解决这个问题有两个方法:
- 初步得到交集后进行去重,就能得到最终的交集
- 判断该数是否为交集,如果是,记录数值后,把位图中的值给
reset,这样即使后续有重复的值,也不会被纳入交集了
解决方案二(无内存空间限制的情况下):直接搞两个位图,把两个文件都读进去,然后同时遍历,通过 & 位运算求出交集就行了
这种方案很暴力,对空间要求较高,且每次遍历的时间都是恒定的(42 亿次)
抛开题目中的内存空间限制,解决方案一、二各有自己的使用场景
- 数据量过大时,比如
42亿或更多,适合使用方案二(个数相关),因为 不管值再大,整数不过42亿多个,方案二在进行遍历时,也只需要遍历42亿次,是比较合适的 - 当数据量较小时,比如
1亿,就可以考虑方案一了(值相关),原因很简单:节省空间的同时不至于遍历太多次,方案一遍历时,遍历的是数据量,只需要遍历1亿次
奈何本题有内存空间限制,还是老老实实的使用方案一吧
6、问题四
一个文件有
100亿个int,1 GB内存,设计算法找到出现次数不超过2次的所有整数
这道题是 问题二 的变形,只需要推广 约定 即可,照样使用两个 位图
约定:
- 一次都没有出现:
0 0 - 只出现一次:
0 1 - 出现两次:
1 0 - 出现三次或更多:
1 1
把代码稍微修改下,可得出代码
template<size_t N>
class twoBitSet
{
public:
void twoSet(size_t val)
{
//约定: 0 0 表示没有出现, 0 1 表示只出现过一次, 1 0 表示出现两次, 1 1 表示出现三次或更多
if (_bs1.test(val) == false && _bs2.test(val) == false)
_bs2.set(val); //第一次出现,位图2 置 1
else if (_bs1.test(val) == false && _bs2.test(val) == true)
{
//此时为第二次出现, 往前进位
_bs1.set(val);
_bs2.reset(val);
}
else if (_bs1.test(val) == true && _bs2.test(val) == false)
{
//出现三次或更多
_bs2.set(val);
}
}
void print()
{
//输出只出现一次的数字
//判断 位图1 及 位图2
for (int i = 0; i <= N; i++)
{
if ((!_bs1.test(i) && _bs2.test(i)) || (_bs1.test(i) && !_bs2.test(i)))
{
std::cout << i << " " << std::endl;
}
}
}
private:
bitset<N> _bs1;
bitset<N> _bs2;
};
借助 demo 进行简单测试
void testTwoBitSet2()
{
int a[] = { 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 5, 6, 7, 8, 8 };
Yohifo::twoBitSet<100> Bits; //最大的值不过 100,所以 100 足够了
for (auto e : a)
{
Bits.twoSet(e);
}
Bits.print();
}

不得不说,二进制进位统计的思想还是很好用的
7、位图小结
位图 是一种十分特殊的数据结构,其主要依靠 0 和 1 表征状态,结合 哈希 的映射思想,即保证了 速度,又保证了 空间
位图 的优点如下:
- 速度极快
O(1) - 节省空间 使用粒度最细的比特位
位图 的缺点如下:
- 只能映射整型
- 对于浮点符、字符串等数据无法做到很好的映射
位图 的应用场景:
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
映射字符串时,主要是无法确保唯一性,但可以判断字符串 是否存在,这就是 哈希 的另一个应用场景:布隆过滤器
弗雷尔卓德之心 布隆

🌆总结
以上就是本次关于 C++ 哈希的应用【位图】的全部内容了,在本文中,首先引入了一道来自【腾讯】的海量数据面试题,明确需要使用 位图 解决问题,简单模拟实现位图之后,又引入了几道海量数据面试题,进一步加深对 位图 结构的认识,位图 还可以用来实现其他结构,比如 布隆过滤器,常用于字符串快速判断,详细内容移步下一篇文章

文章来源地址https://www.toymoban.com/news/detail-605882.html
相关文章推荐 文章来源:https://www.toymoban.com/news/detail-605882.html
C++ 进阶知识
C++【哈希表的完善及封装】
C++【哈希表的模拟实现】
C++【初识哈希】
C++【一棵红黑树封装 set 和 map】
C++【红黑树】
C++【AVL树】
C++【set 和 map 学习及使用】
C++【二叉搜索树】
C++【多态】
C++【继承】
到了这里,关于C++ 哈希的应用【位图】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[C++]哈希应用之位图&布隆过滤器](https://imgs.yssmx.com/Uploads/2024/04/852662-1.gif)