使用的源码来自于github: GitHub - davabase/whisper_real_time: Real time transcription with OpenAI Whisper.
安装speech_recognition时需要安装依赖包PyAudio、pocketsphinx
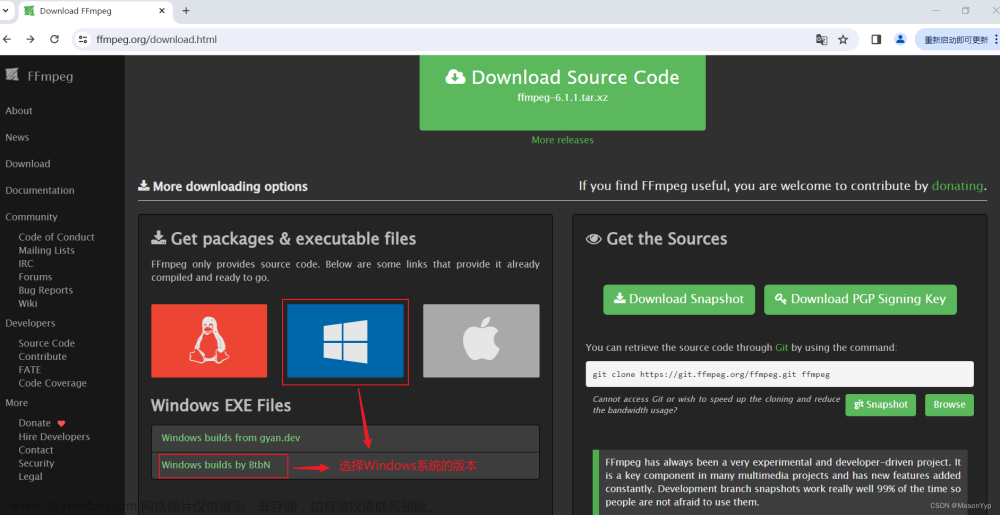
还需要安装ffmpeg-python否则会报错
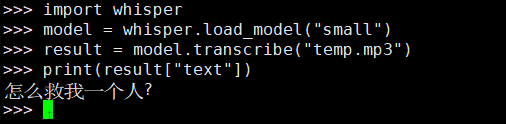
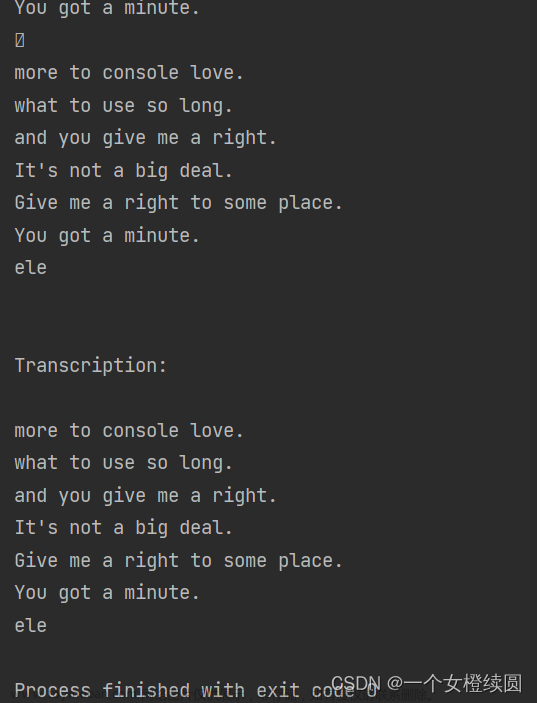
运行效果如下:
 文章来源:https://www.toymoban.com/news/detail-605889.html
文章来源:https://www.toymoban.com/news/detail-605889.html
点击运行程序后出现model loaded 没有错误然后直接对着麦克风说话即可文章来源地址https://www.toymoban.com/news/detail-605889.html
到了这里,关于记录第一个复现的实时whisper语音转文字demo的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!