批量文本的处理方法
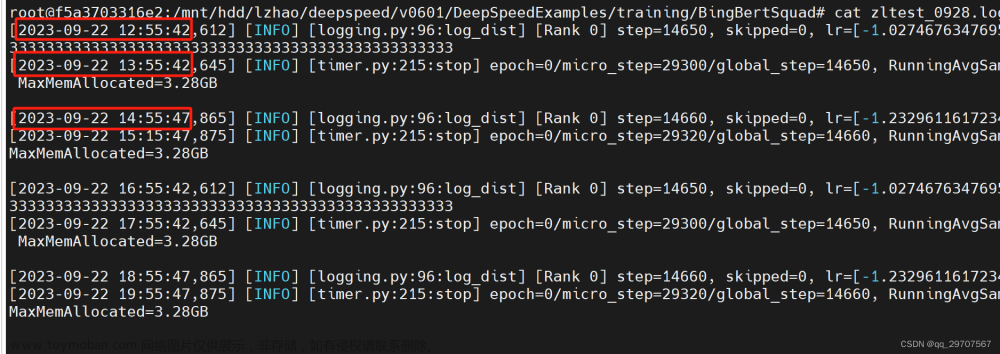
在报文中有很多指标和值都具有固定的格式,比如是 a="1" 这类格式,那么我们只取前面的指标a,就会比较复杂,而使用正则表达式就会快乐许多!
采用以下第二种方法
查找目标 =(.+?)\" 表示查找以等号开头,引号和空格 结尾的字符串,可以避免查到第一个引号,然后批量可以替换为\n,即每个指标单独进行换行罗列
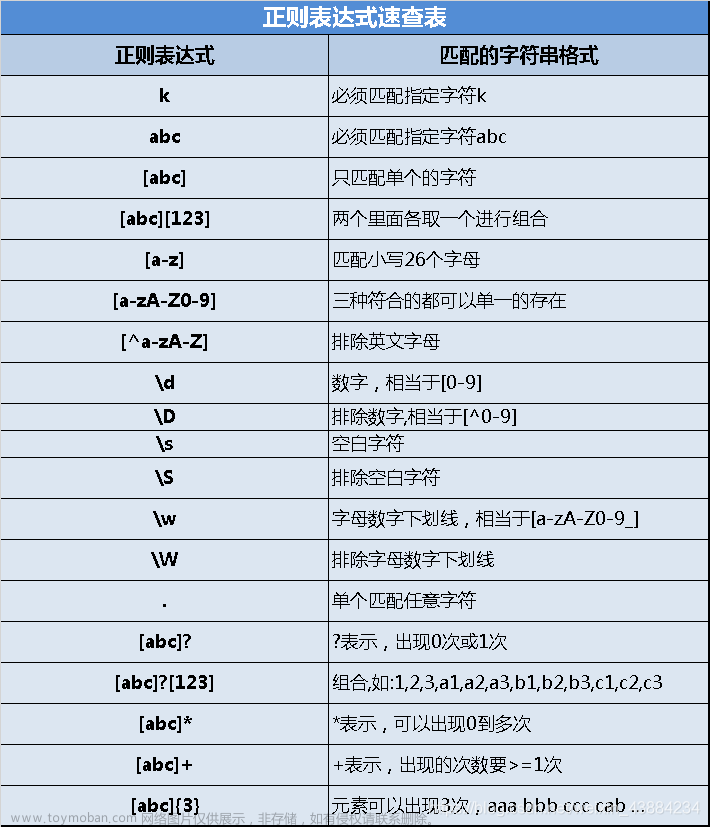
1.正则表达式匹配以某字符开头的这一行数据
表达式:
(?:^|\n)字符位置.*
示例:
(?:^|\n)prompt.*表示以prompt开头的这一行字符串。
2.正则表达式匹配以a字符串开头,b字符串结尾的字符,中间不管
表达式:
a字符串位置(.+?)b字符串位置 ,注意很多字符有特殊意义,要加上\来转义
示例:
匹配以to_date开头,以), 字符串结尾的字符串
to_date(.+?)\), 即可,注意对)进行转义。
注意:
上述说的是以(括号逗号)结尾。
3.只匹配纯数字的字符串
表达式:
^[0-9]+$
解释:
^:匹配行首
[0-9]+:匹配1个或多个数字
$:匹配行尾,总的来说就是匹配一行数字
示例:
只匹配文档中全是数字的某一行,任何符号都不能有。
4.只匹配纯字母的字符串
表达式:
^[A-Za-z]+$
解释:
^:匹配行首
[A-Za-z]+:匹配1个或多个字母
$:匹配行尾,总的来说就是匹配一行字母
示例:
只匹配文档中全是字母的某一行,任何符号都不能有。
5.同时查找多个字符串
表达式:
a|b
示例:
张三|李四|王五
解释:
同时查找文中包含张三、李四、王五字符串所在的行。
正则表达式(.+)和(.+?)的区别
1、符号释义
① () 分组符,把括号内的字符当成一个整体处理。
② . 与换行符外的字符都匹配,针对单字符。
③ + 前一字符必须存在,可以重复1次或更多次
④ ?跟在子串后,表示匹配前面的字符串1次或0次,即前一字符可以存在也可以不存在,但是存在只能有一次;
跟在.、+、?后,表示进入非贪婪模式,也称为惰性模式。
正则默认贪婪模式
贪婪模式
尽可能匹配最长的字符串。贪婪匹配是先看整体字符串是否匹配,如果不匹配,它会去掉字符串中的最后一个字符再次尝试匹配。以此循环,直至匹配成功。
非贪婪模式
尽可能匹配最短的字符串。惰性匹配是从左侧第一个字符向右匹配,先看是否匹配,若不匹配,就加入右侧下一个字符再次尝试匹配。以此循环,直至匹配成功。
3、实例
存在字符串"<1><123>"
①正则表达式<(.+)>表示尽可能匹配最长的符合规则<字符串>的内容,最终返回"<1><123>"文章来源:https://www.toymoban.com/news/detail-606155.html
②正则表达式<(.+?)>表示尽可能匹配最短的符合规则<字符串>的内容,最终返回"<1>"
————————————————
版权声明:本文为CSDN博主「Bitup_bitwin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_44259499/article/details/129342053文章来源地址https://www.toymoban.com/news/detail-606155.html
到了这里,关于notepad++ 正则表达式查找特定字符串的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!