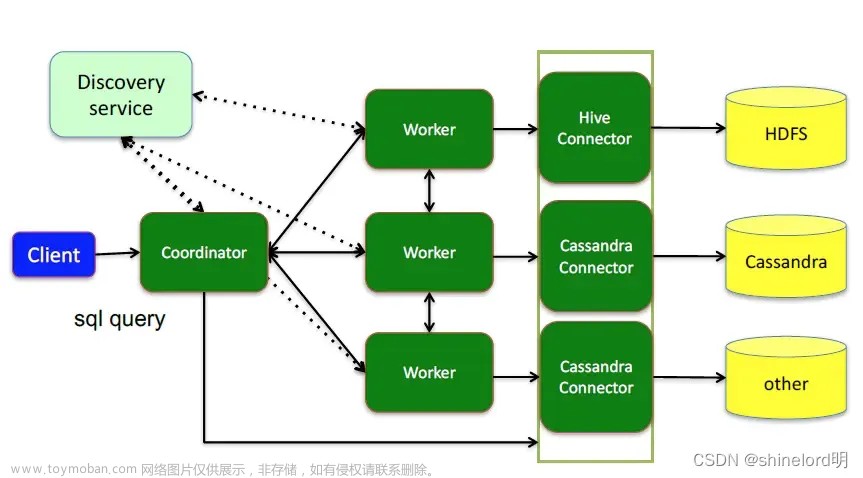
1.Trino介绍

EMR的数据湖架构以OSS和HDFS作为数据湖的存储层。在存储层的基础上,精心安装了存储优化器,主要是JindoFS和ALLUXIO系列。在存储格式方面,EMR的数据湖支持Hudi,Iceberg和ORC等格式。在计算层,它支持多种计算,比如Flink,Spark,Trino和Hive等等。

- 稳定
- 减少成本
- 生态
- 性能高
EMR Trino的特性, 首先在稳定向方面,EMR Trino支持内置Coordinator HA赫尔Worker Label功能。由于EMR Trino集成了EMR弹性伸缩的能力,并且支持Trino on K8s产品形态,所以它大大节省了运维成本。在生态方面,EMR Trino不但支持Iceberg、Hudi、Delta Connector等云上生态,而且支持优化的ClickHouse、Hive等Connector。在性能方面,EMR Trino针对Parquet/Orc等格式,进行优化。并且利用JindoFS的缓存层加速数据湖查询。大幅提升了查询效率。
2.客户案例
- 在线教育
- 社区领域
- 电商领域

它每天的数据量高达几十亿条,同时还存在订单数据变更,特征人群圈选,机器学习训练等需求。原有的解决方案,存在数据处理不及时,无法应对Upsert场景,并且拉链表笨拙,耗费资源大。经过改造之后,完美支持Upsert场景,Presto可以查询明细数据,CK的宽表数也可供Ad-hoc查询,CK的物化视图供BI系统查询。

它每天有5TB的数据规模,需要支持实时大屏,业务系统点查和业务人员随机查询。在改造之前,Hive是分钟级数仓,它面临算不完,查不出,系统运维复杂的痛点。我们将宽表查询落入CK和Ad-hoc查询,将明细表落入StarRocks,实现了复杂Ad-hoc查询,报表分析,物化视图点查能力。让数据仓库的运维变得简单高效。
 文章来源:https://www.toymoban.com/news/detail-606393.html
文章来源:https://www.toymoban.com/news/detail-606393.html
上图是某电商领域的客户,它的大量业务依赖OLTP系统,在GMV,订单,物流,客户分析,推荐系统等方面,都有升级的需求。原先的Hadoop数仓和离线T+1分析系统的方式,让整个系统运维复杂,成本居高不下。我们将OLTP系统逐步过渡到OLAP系统,替代了原有数仓结构的同时,让链路变得极其简化,让Ad-hoc查询灵活,方便运维人员分析细节数据,对接线上系统点查。简化系统的同时,提升了运维人员的工作效率,大幅降低了运维成本。文章来源地址https://www.toymoban.com/news/detail-606393.html
到了这里,关于[技术选型] Trino介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!