哈喽大家好,现在刚毕业,很多小伙伴因为找不到工作或者找了很多也不喜欢,再有懒一点的,太热了根本不想出门到处找。
所以今天给大家分享使用Python批量采集招聘数据,进行可视化分析,轻松找到心仪工作!
话不多说,我们直接开始~
准备工作
软件工具
- Python 3.8
- Pycharm
- 谷歌浏览器
- 谷歌驱动
selenium --> 自动化测试模块
模拟人的行为去操作浏览器
手动操作
- 打开浏览器
- 输入网址
- 找到我们需要的数据内容
- 手动复制粘贴放到表格文件
模块使用
selenium # pip install selenium==3.141.0 自动化测试 操作浏览器
csv # 保存数据 保存csv文件
win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内镜像源)
文章不理解的话,我还准备了视频讲解,和代码一起打包好了,文末名片自取
数据获取部分代码
打开浏览器
浏览器驱动选择以及下载:
- 查看浏览器版本
- 驱动版本选择和你浏览器版本最相近的
- 驱动文件<不需要双击安装>, 直接放到你python安装目录里面
主要代码
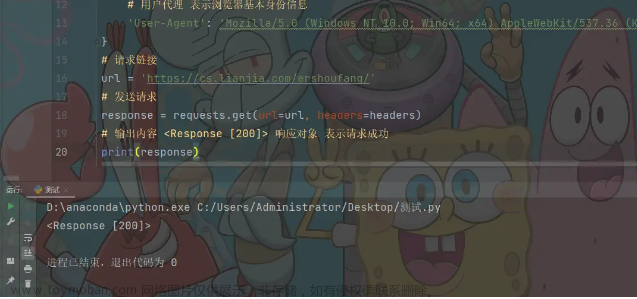
driver = webdriver.Chrome()
# 访问网站
driver.get(
'https://www.***.com/zhaopin/?inputFrom=www_index&workYearCode=0&key=python&scene=input&ckId=rn8762mqhk78fi3d9fiqzzoobk7f66u9&dq=')
"""
找到我们需要的数据内容
前提 -> 你要让网页元素<数据>加载出来
通过元素定位, 获取数据内容 <通过标签提取数据>
"""
# 设置延时, 让网页元素加载完整
driver.implicitly_wait(10) # 隐式等待, 只要网页加载出来就运行下面的代码
time.sleep(1) # 死等, 一定要等够
# 获取所有招聘信息对应div标签
divs = driver.find_elements_by_css_selector('.job-list-box div .job-card-left-box')
# print(driver) # webdriver.Chrome() 返回selenium对象
# print(divs) # 返回列表, 列表里面元素是selenium对象
for div in divs:
"""
提取具体数据内容, 提取每个div标签里面所包含的数据内容
.job-title-box div.ellipsis-1
"""
# 职位
title = div.find_element_by_css_selector('.job-title-box div.ellipsis-1').text
# 城市
city = div.find_element_by_css_selector('.job-title-box span.ellipsis-1').text
salary = div.find_element_by_css_selector('.job-salary').text
# 列表推导式
info_list = [i.text for i in div.find_elements_by_css_selector('.job-labels-box .labels-tag')]
print(info_list)
exp = info_list[0]
edu = info_list[1]
labels = ','.join(info_list[2:])
company = div.find_element_by_css_selector('.company-name').text
company_type = div.find_element_by_css_selector('.company-tags-box span').text
company_num = div.find_element_by_css_selector('.company-tags-box span:last-of-type').text
href = div.find_element_by_css_selector('.job-detail-box a').get_attribute('href')
dit = {
'职位': title,
'城市': city,
'薪资': salary,
'经验': exp,
'学历': edu,
'技术点': labels,
'公司': company,
'公司领域': company_type,
'公司规模': company_num,
'详情页': href,
}
csv_writer.writerow(dit)
print(dit)
保存表格
f = open('python.csv', mode='w', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'职位',
'城市',
'薪资',
'经验',
'学历',
'技术点',
'公司',
'公司领域',
'公司规模',
'详情页',
])
csv_writer.writeheader()
可视化展示
读取文件
import pandas as pd
df = pd.read_csv('data.csv')
df.head()
python职位学历需求分布
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
edu_type,
edu_num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="python职位学历需求分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.load_javascript()
python职位学历需求分布
edu_num = df['经验'].value_counts().to_list()
edu_type = df['经验'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
edu_type,
edu_num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="python职位经验需求分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
python职位城市分布
edu_num = df['城市'].str[:2].value_counts().to_list()
edu_type = df['城市'].str[:2].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
edu_type,
edu_num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="python职位城市分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
python公司领域分布文章来源:https://www.toymoban.com/news/detail-606526.html
edu_num = df['公司领域'].value_counts().to_list()
edu_type = df['公司领域'].value_counts().index.to_list()
c = (
Pie()
.add(
"",
[
list(z)
for z in zip(
edu_type,
edu_num,
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="python公司领域分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
c.render_notebook()
好了今天的分享就到这结束了,咱们下次再见!文章来源地址https://www.toymoban.com/news/detail-606526.html
到了这里,关于简单的用Python采集招聘数据内容,并做可视化分析!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!