网页元素定位
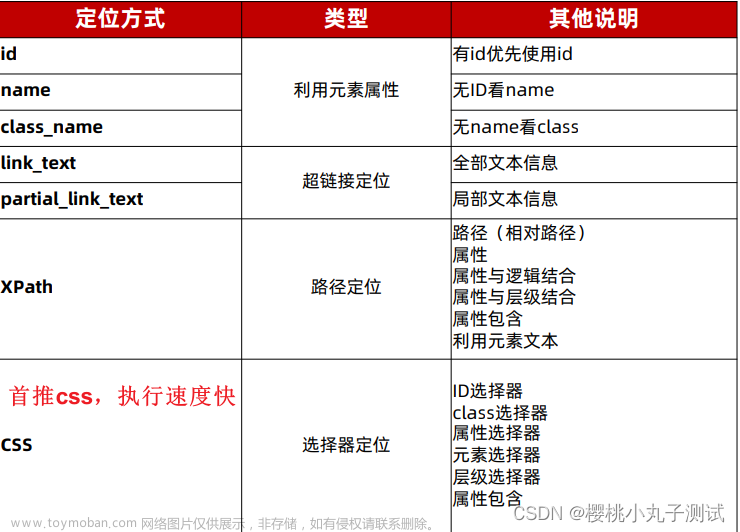
一、id 定位
标签的 id 具有唯一性,就像人的身份证。
二、name 定位
name 指定标签的名称,在页面中可以不唯一。
三、class 定位
class 指定标签的类名,在页面中可以不唯一。
四、tag 定位
每个 tag 往往用来定义一类功能,所以通过 tag 来识别某个元素的成功率很低,每个页面一般都用很多相同的 tag ,比如:\<div\>、\<input\> 等。
五、link 定位
link 专门用来定位文本链接。
六、partial_link 定位
partial_link 翻译过来就是“部分链接”,对于有些文本很长,这时候就可以只指定部分文本即可定位。
七、xpath 定位
xpath 是一种在 XML 文档中定位元素的语言,它拥有多种定位方式,下面通过实例我们看一下它的几种使用方式。
八、css 定位
CSS 使用选择器来为页面元素绑定属性,它可以较为灵活的选择控件的任意属性,一般定位速度比 xpath 要快,但使用起来略有难度。
- 具体操作见示例代码:
from selenium import webdriver #导入selenium库下的webdriver类。
from selenium.webdriver.common.by import By #导入'定位方式'
p = r"F:\....\chromedriver.exe" #版本 107.0.5304.88
dr = webdriver.Chrome(executable_path = p) #1.打开浏览器
dr.get('http://www.txtbook.com.cn/') #输入网址
aa = dr.find_element(By.ID,'bdshare_js') #该写法,需要导入By类。
aa = dr.find_element(By.NAME,"keyword") #name定位,在页面中可能不唯一。
aa = dr.find_element(By.CLASS_NAME,'categoryWrap01') #class定位,在页面中可能不唯一。【样式】
aa = dr.find_element(By.TAG_NAME,'input') #每一组<..>都是一个tag,每个 tag 往往用来定义一类功能,如:输入框、按钮、标签...等。
aa = dr.find_element(By.LINK_TEXT,'武印大陆TXT下载') #link定位,用来[超链接文本]的定位,一定要[完整的文本]。
aa = dr.find_element(By.PARTIAL_LINK_TEXT,'武印') #partial_link定位,功能和link定位一样,不过可以只要[部分文字]。如果页面中有多个,默认选第一个。
以上六种都相对比较简单。
#-----------利用XML进行XPATH定位元素
# 所有<>的标签用/隔开,有多个可以带上下标,如:/div[3]
# <>标签内的可以同样用下标进行判断,如:/a[class="text"];/a[price>30];
# 如果是相对路径,可以通过@加上元素名称进行组合,@起的内容表示条件,*号是通配符<>一个标签。
# 如://*[@id="mainBody"];//body[@id="mainBody"]
# 总的格式 <>标签用:/html; 标签内的属性用:[];如:/html/body/li[1]
# 绝对路径: /html/body/div[3]/div[5]/div[1]/div[2]/ul/li[1]/a
# 相对路径: //*[@id="mainBody"]/div[5]/div[1]/div[2]/ul/li[1]/a
aa = dr.find_element(By.XPATH,'/html/body/div[3]/div[5]/div[1]/div[2]/ul/li[1]/a')
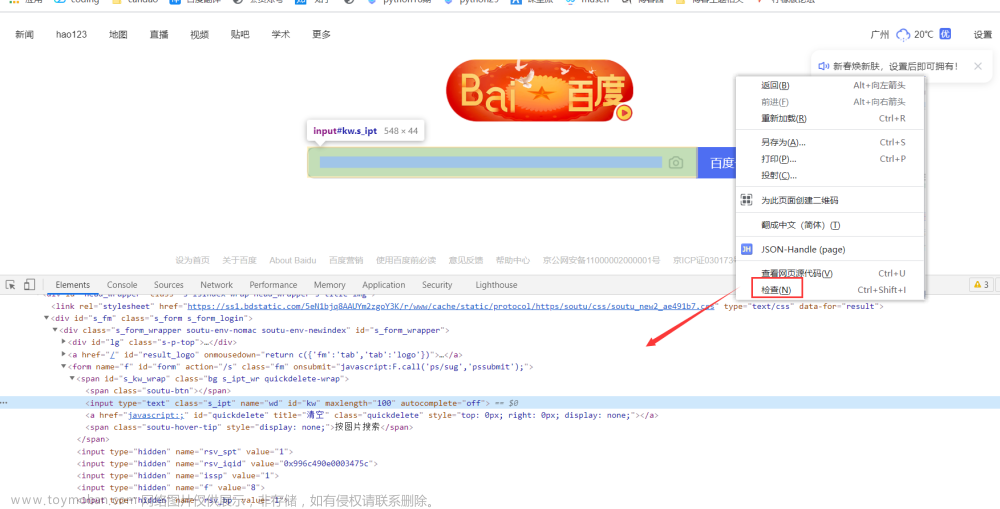
aa = dr.find_element(By.XPATH,'//*[@id="mainBody"]/div[5]/div[1]/div[2]/ul/li[1]/a')#元素路径的获取还可以通过:浏览器,F12开发者模式,元素选择工具,点击页面元素,然后再F12中的代码位置。右击,复制,复制Xpath。

示例:
<html>
<head>...<head/>
<body>
<div id="csdn-toolbar">
<div class="toolbar-inside">
<div class="toolbar-container">
<div class="toolbar-container-left">...</div>
<div class="toolbar-container-middle">
<div class="toolbar-search onlySearch">
<div class="toolbar-search-container">
<input id="toolbar-search-input" autocomplete="off" type="text" value="" placeholder="C++难在哪里?">
根据上面的标签需要定位 最后一行 input 标签,以下列出了四种方式,xpath 定位的方式多样并不唯一,使用时根据情况进行解析即可。
# 绝对路径(层级关系)定位
driver.find_element_by_xpath(
"/html/body/div/div/div/div[2]/div/div/input[1]")
# 利用元素属性定位
driver.find_element_by_xpath(
"//*[@id='toolbar-search-input']"))
# 层级+元素属性定位
driver.find_element_by_xpath(
"//div[@id='csdn-toolbar']/div/div/div[2]/div/div/input[1]")
# 逻辑运算符定位
driver.find_element_by_xpath(
"//*[@id='toolbar-search-input' and @autocomplete='off']")
#-----------利用CSS层级定位,相对xpath要简洁,但符号多,相对复杂一点。
#代表id; .代表class; >子元素层级
aa = dr.find_element(By.CSS_SELECTOR,'#bdshare_js')
aa = dr.find_element(By.CSS_SELECTOR,'.categoryWrap01')
常见语法示例:

同样定位上面实例中的 input 标签。文章来源:https://www.toymoban.com/news/detail-606646.html
driver.find_element_by_css_selector('#toolbar-search-input')
driver.find_element_by_css_selector('html>body>div>div>div>div>div>div>input')
文章来源地址https://www.toymoban.com/news/detail-606646.html
到了这里,关于【selenium模块-WEB自动化】八大网页元素定位方法(三)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!