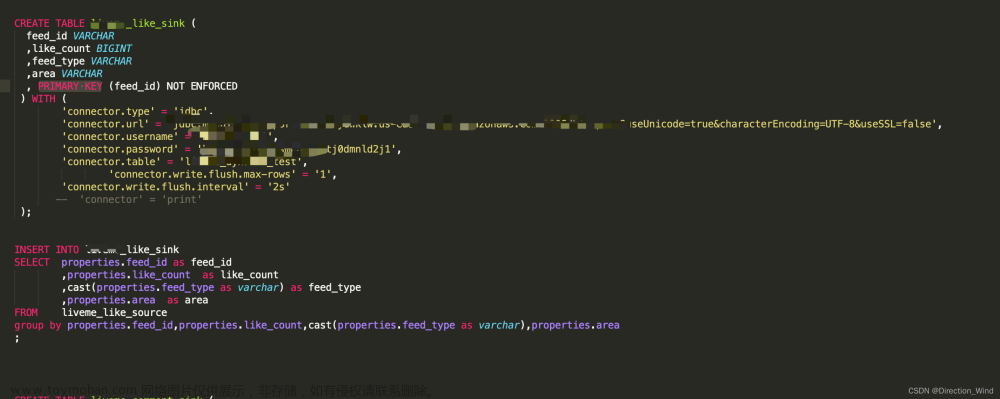
某互联网大厂的一道比较有深度的面试题,
参考文章 : hive|性能优化|_Hive ROW_NUMBER TopN 性能优化
问题
有50W个 店铺,每个顾客访客访问任何一个店铺的任何一个商品时都会产生一条访问日志,
访问日志存储的表名为Visit,访客的用户id为user_id,被访问的店铺名称为shop,数据如下:
user_id shop
u1 a
u2 b
u1 b
u1 a
u3 c
u4 b
u1 a
u2 c
u5 b
请统计:
(1)每个店铺的UV(访客数)
(2)每个店铺访问次数top3的访客信息。输出店铺名称、访客id、访问次数
问题(1)解法
问题一的目的是考察能否在大数据量下考虑用 group做去重预聚合,而不是直接用count(distinct)
正确解法
with
user_dist_log as (
select
user_id,
shop,
count(1) as pv_cnt
from visit
group by
user_id,
shop
)
select
shop,
count(1) as uv
from user_dist_log
group by shop;问题(2)解法
问题二的目的是考察开窗函数情况下的数据倾斜如何解决
由于开窗函数是把数据分发到同一个 executor 进行单点的数据排序,那么热点数据很容易导致数据倾斜,所以这里的解决方案是2步聚合的方式,加盐打散,二次聚合。文章来源:https://www.toymoban.com/news/detail-606728.html
具体代码文章来源地址https://www.toymoban.com/news/detail-606728.html
with
user_dist_log as (
select
user_id,
shop,
count(1) as pv_cnt
from visit
group by
user_id,
shop
)
select
shop,
user_id,
shop_rank2
from
(
select
shop,
user_id,
row_number() over(partition by shop order by pv_cnt desc) as shop_rank2
from
(
select
shop,
rand1,
user_id,
pv_cnt
from
(
select
shop,
ceil(rand()*100) as rand1,
user_id,
pv_cnt,
row_number() over(partition by shop, ceil(rand()*100) order by pv_cnt desc) as shop_rank
from user_dist_log
) mid_tmp
where shop_rank <= 3
)
)
where shop_rank2 <= 3测试数据构建
with
visit as (
select
'u1' as user_id,
'a' as shop
union all
select
'u2' as user_id,
'b' as shop
union all
select
'u1' as user_id,
'b' as shop
union all
select
'u1' as user_id,
'a' as shop
union all
select
'u3' as user_id,
'c' as shop
union all
select
'u4' as user_id,
'b' as shop
union all
select
'u1' as user_id,
'a' as shop
union all
select
'u2' as user_id,
'c' as shop
union all
select
'u5' as user_id,
'b' as shop
),到了这里,关于SQL_求店铺的topN && 开窗函数数据倾斜的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!