概述
目前来说,kubernetes集群搭建的方式很多,选择一个稳定的适合自己的很重要。目前使用kubeadm方式搭建k8s集群还是很常见的,使用kubeadm搭建可以很简单差不多两条命令就行,也可以稍微复杂一点做一些基础优化,本文将分享一下使用kubeadm搭建集群并做了一定的优化。
安装
本环境将使用centos7.6.1810 的系统安装kubernetes1.19.16版本集群,也可以选择稍高版本的系统和k8s版本。但建议不要使用centos7.4以一下,要不然就自己升级一下内核版本。容器技术依赖于内核技术,低版本系统部署和运行后可能出去一些奇怪的问题。
环境规划
| IP | HOSTNAME | role | CPU | Memory |
|---|---|---|---|---|
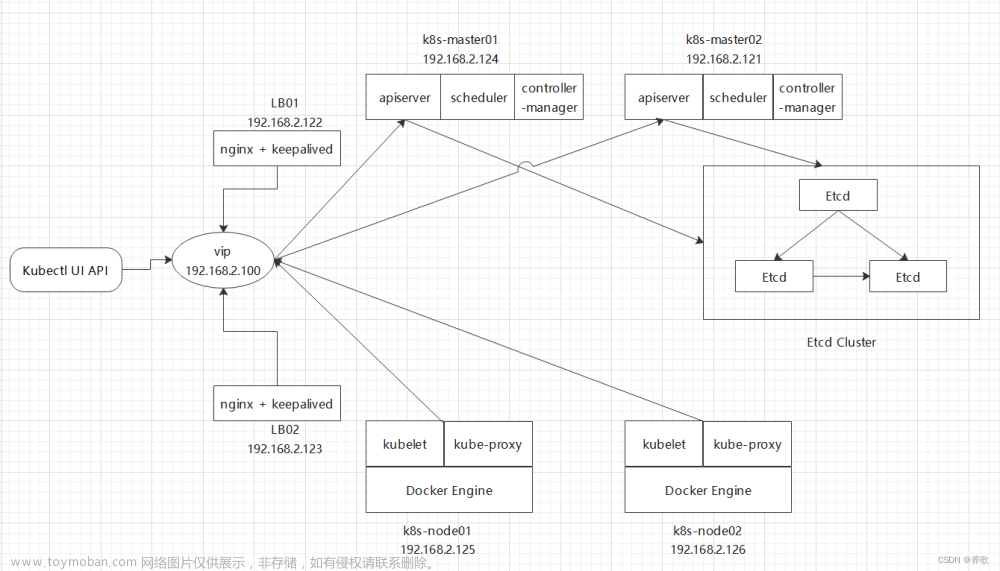
| 192.168.2.250 | vip | |||
| 192.168.2.140 | k8s-m1 | master | 16 | 8G |
| 192.168.2.141 | k8s-m2 | master | 16 | 8G |
| 192.168.2.142 | k8s-m3 | master | 16 | 8G |
说明:
- 所有操作都用root用户进行,系统盘尽量大,要不然就单独修改docker的数据盘,不然到时候镜像多了例如超过85%会被gc回收镜像
- 高可用一般建议大于等于3台的奇数台,本环境我使用的是3台master来做高可用
事前准备(每台机器)
系统层面设置:全新干净系统,只做了网络和dns的相关配置。
- 关闭 所有防火墙和SELinux,否则后续 K8S 挂载目录时可能报错 Permission denied。
systemctl disable --now firewalld NetworkManager
setenforce 0
sed -ri '/^[^#]*SELINUX=/s#=.+$#=disabled#' /etc/selinux/config
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
- 关闭 dnsmasq (可选)
linux 系统开启了 dnsmasq 后(如 GUI 环境),将系统 DNS Server 设置为 127.0.0.1,这会导致 docker 容器无法解析域名,需要关闭它
systemctl disable --now dnsmasq
- Kubernetes 建议关闭系统Swap,在所有机器使用以下指令关闭swap并注释掉/etc/fstab中swap的行,不想关闭可以不执行,后面会有应对的配置选项:
swapoff -a && sysctl -w vm.swappiness=0
sed -ri '/^[^#]*swap/s&^&#&' /etc/fstab
- 安装一些基础依赖包和工具
yum install epel-release -y
yum install -y \
curl \
wget \
git \
conntrack-tools \
psmisc \
nfs-utils \
jq \
socat \
bash-completion \
ipset \
ipvsadm \
conntrack \
libseccomp \
net-tools \
crontabs \
sysstat \
unzip \
bind-utils \
tcpdump \
telnet \
lsof \
htop
如果集群kube-proxy想使用ipvs模式的话(ipvs效率更高)需要加载以下模块,按照规范使用systemd-modules-load来加载而不是在/etc/rc.local里写modprobe
> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
systemctl restart systemd-modules-load.service
上面如果systemctl restart 命令报错可以使用systemctl status -l systemd-modules-load.service看看哪个内核模块不能正常加载,然后在/etc/modules-load.d/ipvs.conf里注释掉它再restart试试
- 所有机器需要设定/etc/sysctl.d/k8s.conf的系统参数,目前对ipv6支持不怎么好,所以这里将ipv6也关闭了。
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
# 要求iptables不对bridge的数据进行处理
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
net.netfilter.nf_conntrack_max = 2310720
fs.inotify.max_user_watches=89100
fs.may_detach_mounts = 1
fs.file-max = 52706963
fs.nr_open = 52706963
vm.overcommit_memory=1
vm.panic_on_oom=0
EOF
sysctl --system
- 如果选择关闭swap也要在内核里关闭,不关闭可以不执行
echo 'vm.swappiness = 0' >> /etc/sysctl.d/k8s.conf
- 如果kube-proxy使用ipvs的话为了防止timeout需要设置下tcp参数
cat <<EOF >> /etc/sysctl.d/k8s.conf
# https://github.com/moby/moby/issues/31208
# ipvsadm -l --timout
# 修复ipvs模式下长连接timeout问题 小于900即可
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
EOF
sysctl --system
- 修改systemctl启动的最小文件打开数量。关闭ssh方向dns解析
sed -ri 's/^#(DefaultLimitCORE)=/\1=100000/' /etc/systemd/system.conf
sed -ri 's/^#(DefaultLimitNOFILE)=/\1=100000/' /etc/systemd/system.conf
sed -ri 's/^#(UseDNS )yes/\1no/' /etc/ssh/sshd_config
- 文件最大打开数,按照规范,在子配置文件添加
cat>/etc/security/limits.d/kubernetes.conf<<EOF
* soft nproc 131072
* hard nproc 131072
* soft nofile 131072
* hard nofile 131072
root soft nproc 131072
root hard nproc 131072
root soft nofile 131072
root hard nofile 131072
EOF
- 集群的HA依赖于时间一致性,安装并配置chrony
yum install -y chrony
cat>/etc/chrony.conf<<EOF
server cn.pool.ntp.org iburst minpoll 4 maxpoll 10
server s1b.time.edu.cn iburst minpoll 4 maxpoll 10
# Ignor source level
stratumweight 0
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/chrony.drift
# This directive enables kernel synchronisation (every 11 minutes) of the
# real-time clock. Note that it can’t be used along with the 'rtcfile' directive.
rtcsync
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust
# the system clock.
#minsources 2
bindcmdaddress 127.0.0.1
#bindcmdaddress ::1
# Specify file containing keys for NTP authentication.
keyfile /etc/chrony/chrony.keys
logdir /var/log/chrony
# adjust time big than 1 sec will log to file
logchange 1
EOF
systemctl enable --now chronyd
- 修改hostname
kubelet和kube-proxy上报node信息默认是取hostname的,除非通过--hostname-override指定,这里自行设置hostname,并修改hosts文件。
#按规划进行修改
hostnamectl set-hostname xxx
##所有主机都修改hosts文件
cat >>/etc/hosts << EOF
192.168.2.140 k8s-m1
192.168.2.141 k8s-m2
192.168.2.142 k8s-m3
EOF
- docker官方的内核检查脚本建议(RHEL7/CentOS7: User namespaces disabled; add ‘user_namespace.enable=1’ to boot command line),使用下面命令开启
grubby --args="user_namespace.enable=1" --update-kernel="$(grubby --default-kernel)"
最后重启系统
reboot
安装docker
选择官方建议的对应版本,可以通过对应版本地址进行查看https://github.com/kubernetes/kubernetes/blob/v1.19.16/build/dependencies.yaml,这里我们选择docker 19.03版本,并使用docker官方的安装脚本进行安装(该脚本支持centos和ubuntu)。
export VERSION=19.03
curl -fsSL "https://get.docker.com/" | bash -s -- --mirror Aliyun
所有机器配置加速源并配置docker的启动参数使用systemd,使用systemd是官方的建议,详见 https://kubernetes.io/docs/setup/cri/
mkdir -p /etc/docker/
cat>/etc/docker/daemon.json<<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://5sssm2l6.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn/",
],
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
EOF
Live Restore Enabled这个注意别开,某些极端情况下容器Dead状态之类的必须重启docker daemon才能解决。
- 设置docker开机启动-CentOS安装完成后docker需要手动设置docker命令补全:
yum install -y epel-release bash-completion && \
cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/
- docker自1.13版起会自动设置iptables的FORWARD默认策略为DROP,这可能会影响Kubernetes集群依赖的报文转发功能,防止FORWARD的DROP策略影响转发,给docker daemon添加下列参数修正,当然暴力点也可以iptables -P FORWARD ACCEPT
mkdir -p /etc/systemd/system/docker.service.d/
cat>/etc/systemd/system/docker.service.d/10-docker.conf<<EOF
[Service]
ExecStartPost=/sbin/iptables -I FORWARD -s 0.0.0.0/0 -j ACCEPT
ExecStopPost=/bin/bash -c '/sbin/iptables -D FORWARD -s 0.0.0.0/0 -j ACCEPT &> /dev/null || :'
EOF
- 启动docker并看下信息是否正常
systemctl enable --now docker
docker info
如果enable docker的时候报错开启debug,如何开见
kubeadm部署
镜像源准备
默认源在国外会无法安装,我们使用国内的镜像源,所有机器都要操作
cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
EOF
master部分安装相关软件
k8s的node就是kubelet+cri(一般是docker),kubectl是一个agent读取kubeconfig去访问kube-apiserver来操作集群,kubeadm是部署,所以master节点需要安装三个,node一般不需要kubectl但是yum安装的时候还是会给你安装最新版所以我这里node还是安装了kubectl,不用就行。
yum install -y \
kubeadm-1.19.16 \
kubectl-1.19.16 \
kubelet-1.19.16 \
--disableexcludes=kubernetes && \
systemctl enable kubelet
node部分安装相关软件
yum install -y \
kubeadm-1.19.16 \
kubectl-1.19.16 \
kubelet-1.19.16 \
--disableexcludes=kubernetes && \
systemctl enable kubelet
配置kubelet的参数方法(有需要的话)
查看kubelet的systemd文件
$ systemctl cat kubelet
# /usr/lib/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
# /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/sysconfig/kubelet
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
我们可以看到/etc/sysconfig/kubelet和/var/lib/kubelet/kubeadm-flags.env都是EnvironmentFile,通过可以通过注释查看每个文件中如何设置运行参数。如/var/lib/kubelet/kubeadm-flags.env 中应该通过KUBELET_EXTRA_ARGS来给kubelet配置运行参数,如下。具体参数可以通过kubelet --help查看,参数很多,很多不了解的最好保持默认。
cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--aa=bb --xx=yy"
EOF
第二个EnvironmentFile 文件/var/lib/kubelet/kubeadm-flags.env也一样
haproxy和keepalived的安装
三台master都需要安装
haproxy配置文件
注意,三个节点上haproxy.conf的配置文件内容其实是一样的
cat <<EOF > /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
listen stats
bind *:8006
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth admin:admin
frontend k8s-api
bind 0.0.0.0:8443
bind 127.0.0.1:8443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-api
backend k8s-api
mode tcp
option tcplog
option httpchk GET /healthz
http-check expect string ok
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server api1 192.168.2.140:6443 check check-ssl verify none
server api2 192.168.2.141:6443 check check-ssl verify none
server api3 192.168.2.142:6443 check check-ssl verify none
EOF
keepalived配置文件
注意,keepalived.conf的配置文件内容是有区别的。
cat <<EOF > /etc/keepalived/keepalived.conf
global_defs {
enable_script_security
}
vrrp_script haproxy-check {
user root
script "/bin/bash /etc/keepalived/check_haproxy.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance haproxy-vip {
state MASTER ##注意修改,其中主为MASTER,从为BACKUP
priority 100 ##注意修改,数字越大,优先级越高,主>从
interface eth0 #注意实际环境中网卡名字,有的是ens*啥的
virtual_router_id 48 #所有节点的id要一致
advert_int 3
unicast_src_ip 192.168.2.140 # 本机IP
unicast_peer {
192.168.2.141 # 对端IP
192.168.2.142 # 对端IP
}
virtual_ipaddress {
192.168.2.250/24 # VIP地址
}
track_script {
haproxy-check
}
}
EOF
说明:keeaplived这里需要注意,默认keepalived是采用的组播方式,加上unicast_peer参数后是单播方式,三台keepalived配置文件不一样unicast_src_ipc参数写当前节点IP,unicast_peer参数写另外两个节点IP地址。其他按说明修改
keepalived 健康检查脚本
cat <<'EOF'> /etc/keepalived/check_haproxy.sh
#!/bin/bash
VIRTUAL_IP=192.168.2.250.250
errorExit() {
echo "*** $*" 1>&2
exit 1
}
if ip addr | grep -q $VIRTUAL_IP ; then
curl -s --max-time 2 --insecure https://${VIRTUAL_IP}:8443/healthz -o /dev/null || errorExit "Error GET https://${VIRTUAL_IP}:8443/healthz"
fi
EOF
部署外部Etcd服务
openssl 证书配置文件,注意IP地址书写正确
mkdir -p /etc/kubernetes/pki/etcd
cd /etc/kubernetes/pki
cat <<EOF> /etc/kubernetes/pki/openssl.cnf
[ req ]
default_bits = 2048
default_md = sha256
distinguished_name = req_distinguished_name
[req_distinguished_name]
[ v3_ca ]
basicConstraints = critical, CA:TRUE
keyUsage = critical, digitalSignature, keyEncipherment, keyCertSign
[ v3_req_server ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
[ v3_req_client ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = clientAuth
[ v3_req_apiserver ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names_cluster
[ v3_req_etcd ]
basicConstraints = CA:FALSE
keyUsage = critical, digitalSignature, keyEncipherment
extendedKeyUsage = serverAuth, clientAuth
subjectAltName = @alt_names_etcd
[ alt_names_cluster ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster.local
DNS.5 = k8s-m1
DNS.6 = k8s-m2
DNS.7 = k8s-m3
DNS.8 = localhost
IP.1 = 10.96.0.1
IP.2 = 127.0.0.1
IP.3 = 192.168.2.140
IP.4 = 192.168.2.141
IP.5 = 192.168.2.142
IP.6 = 192.168.2.250
[ alt_names_etcd ]
DNS.1 = localhost
DNS.2 = k8s-m1
DNS.3 = k8s-m2
DNS.4 = k8s-m3
IP.1 = 192.168.2.140
IP.2 = 192.168.2.141
IP.3 = 192.168.2.142
IP.4 = 127.0.0.1
EOF
根据上面的配置文件,生成各服务所需证书,并下发到其他节点。其他节点就不需要在进行证书生成
#生成证书,有效期10000d
openssl genrsa -out etcd/ca.key 2048
openssl req -x509 -new -nodes -key etcd/ca.key -config openssl.cnf -subj "/CN=etcd-ca" -extensions v3_ca -out etcd/ca.crt -days 10000
openssl genrsa -out apiserver-etcd-client.key 2048
openssl req -new -key apiserver-etcd-client.key -subj "/CN=apiserver-etcd-client/O=system:masters" -out apiserver-etcd-client.csr
openssl x509 -in apiserver-etcd-client.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out apiserver-etcd-client.crt -days 10000
openssl genrsa -out etcd/server.key 2048
openssl req -new -key etcd/server.key -subj "/CN=etcd-server" -out etcd/server.csr
openssl x509 -in etcd/server.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/server.crt -days 10000
openssl genrsa -out etcd/peer.key 2048
openssl req -new -key etcd/peer.key -subj "/CN=etcd-peer" -out etcd/peer.csr
openssl x509 -in etcd/peer.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/peer.crt -days 10000
openssl genrsa -out etcd/healthcheck-client.key 2048
openssl req -new -key etcd/healthcheck-client.key -subj "/CN=etcd-client" -out etcd/healthcheck-client.csr
openssl x509 -in etcd/healthcheck-client.csr -req -CA etcd/ca.crt -CAkey etcd/ca.key -CAcreateserial -extensions v3_req_etcd -extfile openssl.cnf -out etcd/healthcheck-client.crt -days 10000
scp -r /etc/kubernetes root@k8s-m2:/etc
scp -r /etc/kubernetes root@k8s-m3:/etc
下载部署,其他节点类似:
所需etcd对应版本可以通过https://github.com/kubernetes/kubernetes/blob/v1.19.16/build/dependencies.yaml查看
mkdir -p /var/lib/etcd
ETCD_VER=v3.4.13
wget https://storage.googleapis.com/etcd/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -O etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xf etcd-${ETCD_VER}-linux-amd64.tar.gz --strip-components=1 -C /usr/local/bin etcd-${ETCD_VER}-linux-amd64/{etcd,etcdctl}
设置 unit file 并启动 etcd,其他节点修改对应 ETCD_NAME 为 etcd1 和 etcd2,ip 改为节点 IP。
ETCD_NAME=etcd0
ETCD_IP="192.168.2.140"
ETCD_IPS=(192.168.2.140 192.168.2.141 192.168.2.142)
cat<<EOF> /usr/lib/systemd/system/etcd.service
[Unit]
Description=etcd
Documentation=https://coreos.com/etcd/docs/latest/
After=network.target
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd
ExecStart=/usr/bin/etcd \\
--name=${ETCD_NAME} \\
--data-dir=/var/lib/etcd \\
--listen-client-urls=https://127.0.0.1:2379,https://${ETCD_IP}:2379 \\
--advertise-client-urls=https://${ETCD_IP}:2379 \\
--listen-peer-urls=https://${ETCD_IP}:2380 \\
--initial-advertise-peer-urls=https://${ETCD_IP}:2380 \\
--cert-file=/etc/kubernetes/pki/etcd/server.crt \\
--key-file=/etc/kubernetes/pki/etcd/server.key \\
--client-cert-auth \\
--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt \\
--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt \\
--peer-key-file=/etc/kubernetes/pki/etcd/peer.key \\
--peer-client-cert-auth \\
--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt \\
--initial-cluster=etcd0=https://${ETCD_IPS[0]}:2380,etcd1=https://${ETCD_IPS[1]}:2380,etcd2=https://${ETCD_IPS[2]}:2380 \\
--initial-cluster-token=my-etcd-token \\
--initial-cluster-state=new \\
--heartbeat-interval 1000 \\
--election-timeout 5000
Restart=always
RestartSec=10s
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl restart etcd
systemctl enable etcd
cat <<EOF > /etc/profile.d/etcd.sh
alias etcd_v2='etcdctl --cert-file /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key-file /etc/kubernetes/pki/etcd/healthcheck-client.key \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://192.168.2.140:2379,https://192.168.2.141:2379,https://192.168.2.142:2379'
alias etcd_v3='ETCDCTL_API=3 \
etcdctl \
--cert /etc/kubernetes/pki/etcd/healthcheck-client.crt \
--key /etc/kubernetes/pki/etcd/healthcheck-client.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://192.168.2.140:2379,https://192.168.2.141:2379,https://192.168.2.142:2379'
EOF
source /etc/profile.d/etcd.sh
etcd_v3 version
etcdctl version: 3.4.13
API version: 3.4
etcd_v3 --write-out=table endpoint status
[root@k8s-m1 ~]# etcd_v3 --write-out=table endpoint status
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | RAFT TERM | RAFT INDEX |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+
| https://192.168.2.140:2379 | 19df3a9852e0345a | 3.4.13 | 24 MB | false | 267804 | 108091120 |
| https://192.168.2.141:2379 | 66d402f1ef2c996e | 3.4.13 | 24 MB | true | 267804 | 108091120 |
| https://192.168.2.142:2379 | 3bb3629d60bef3f6 | 3.4.13 | 24 MB | false | 267804 | 108091121 |
+----------------------------+------------------+---------+---------+-----------+-----------+------------+```
k8s集群安装(第一个master上配置)
打印默认init的配置信息
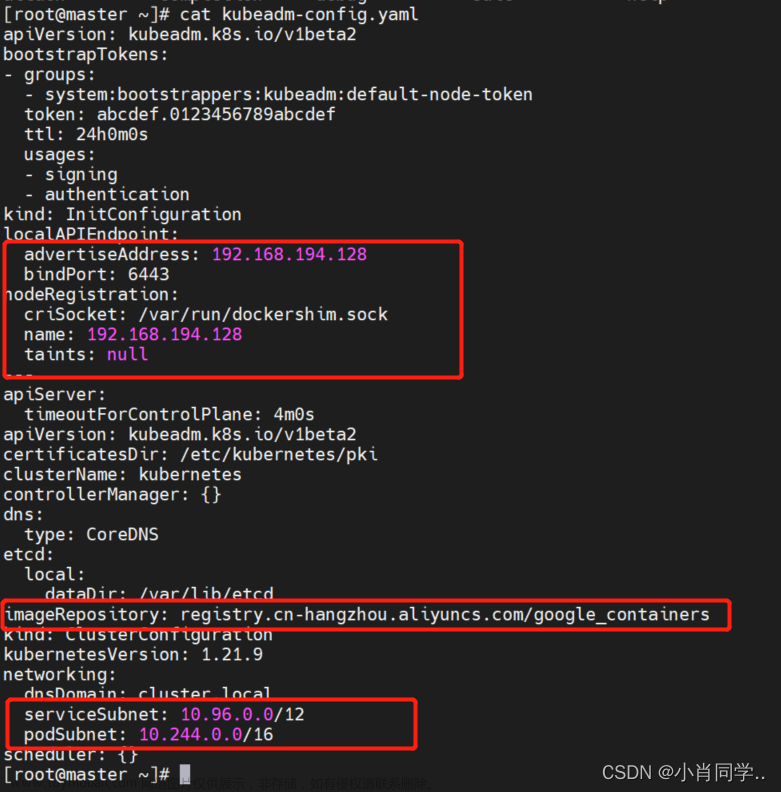
kubeadm config print init-defaults > initconfig.yaml
我们看下默认init的集群参数
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 1.2.3.4
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-m1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.19.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
我们主要关注和保留ClusterConfiguration的段,然后修改下,可以参考下列的v1beta2文档,如果是低版本可能是v1beta1,某些字段和新的是不一样的,自行查找godoc看
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2#hdr-Basics
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2#pkg-constants
https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta2#ClusterConfiguration
controlPlaneEndpoint是规划的vip地址,下面是最终的yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
imageRepository: registry.aliyuncs.com/google_containers
kubernetesVersion: v1.19.16
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
controlPlaneEndpoint: 192.168.2.250:8443 # 单个master的话写master的ip或者不写,端口是haproxy运行的端口
apiServer: # https://godoc.org/k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm/v1beta3#APIServer
timeoutForControlPlane: 4m0s
extraArgs:
authorization-mode: "Node,RBAC"
enable-admission-plugins: "NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeClaimResize,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,Priority"
runtime-config: api/all=true
storage-backend: etcd3
certSANs:
- 127.0.0.1 # 多个master的时候负载均衡出问题了能够快速使用localhost调试
- localhost
- 192.168.2.140
- 192.168.2.141
- 192.168.2.142
- k8s-m1
- k8s-m2
- k8s-m3
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
readOnly: true
controllerManager:
extraArgs:
bind-address: "0.0.0.0"
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
readOnly: true
scheduler:
extraArgs:
bind-address: "0.0.0.0"
extraVolumes:
- hostPath: /etc/localtime
mountPath: /etc/localtime
name: localtime
readOnly: true
dns: {}
etcd:
external:
endpoints:
- https://192.168.2.140:2379
- https://192.168.2.141:2379
- https://192.168.2.142:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs # or iptables
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: "rr" # 调度算法
strictARP: false
syncPeriod: 15s
iptables:
masqueradeAll: true
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
failSwapOn: true # 如果开启swap则设置为false
- swap的话看最后一行,单台master的话把controlPlaneEndpoint的值改为第一个master的ip
- kubectl get cs 查看组件状态发现controllerManager和scheduler 状态Unhealthy 删除
/etc/kubernetes/manifests/目录下对应文件中–port=0的配置即可,每个master节点都需要删除 - 检查文件是否错误,忽略warning,错误的话会抛出error,没有错误则会输出到包含字符串kubeadm join 等添加节点的信息
kubeadm init --config initconfig.yaml --dry-run
#检查镜像是否正确
kubeadm config images list --config initconfig.yaml
#预先拉取镜像
kubeadm config images pull --config initconfig.yaml # 下面是输出
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.19.16
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.19.16
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.19.16
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.19.16
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.2
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.7.0
kubeadm 初始化
下面init只在第一个master上面操作
kubeadm init --config initconfig.yaml
初始化的时候可以添加参数–upload-certs, 作用为将相关的证书直接上传到etcd中保存,这样省去我们手动分发证书的过程。
初始化完成后记住init后打印的token,复制kubectl的kubeconfig,kubectl的kubeconfig路径默认是~/.kube/config
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
init的yaml信息实际上会存在集群的configmap里,我们可以随时查看,该yaml在其他node和master join的时候会使用到
kubectl -n kube-system get cm kubeadm-config -o yaml
配置其他master的k8s管理组件(某些低版本不支持上传证书的时候操作需手动拷贝证书)
第一个master上拷贝ca证书到其他master节点上
scp -r /etc/kubernetes/pki root@k8s-m2:/etc/kubernetes/
scp -r /etc/kubernetes/pki root@k8s-m3:/etc/kubernetes/
其他master join进来
kubeadm join 192.168.2.250.250:8443 \
--token xxx.zzzzzzzzz \
--discovery-token-ca-cert-hash sha256:xxxxxxxxxxx --control-plane
通过下列命令可以获取sha256的值
openssl x509 -pubkey -in \
/etc/kubernetes/pki/ca.crt | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
- 如果集群在init时使用了 --upload-certs 参数将相关的证书直接上传到etcd中保存,则其他master在加入时需要使用 --certificate-key 参数(某些低版本可能不支持)。
- token忘记的话可以kubeadm token list查看,没有的话可以通过kubeadm token create创建。在高版本可以直接使用kubeadm token create --print-join-command来创建添加节点的命令,某些老版本可能不确定支持–print-join-command这个选项,不支持的话就不带–print-join-command选项创建token。
- 通过将参数 --upload-certs 添加到 kubeadm init,你可以将控制平面证书临时上传到集群中的 Secret 请注意此 Secret 将在 2小时后自动过期。证书使用 32 字节密钥加密,可以使用 --certificate-key 指定。
以下阶段命令可用于证书到期后重新上传证书:
kubeadm init phase upload-certs --upload-certs --certificate-key=SOME_VALUE
如果未将参数 --certificate-key 传递给 kubeadm init 和 kubeadm init phase upload-certs, 则会自动生成一个新密钥。
以下命令可用于按需生成新密钥:
kubeadm alpha certs certificate-key
设置kubectl的补全脚本
kubectl completion bash > /etc/bash_completion.d/kubectl
获取节点状态信息
[root@k8s-m1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-m1 Ready master 1d v1.19.16
k8s-m2 Ready master 1d v1.19.16
k8s-m3 Ready master 1d v1.19.16
[root@k8s-m1 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
addon(此章开始到结尾选取任意一个master上执行)
到此,集群还不能真正使用,因为集群的网络组件是以插件的方式部署,在这里我选用了常用的flannel,后面将分享使用其他网络组件,如calico。
#直接apply就行,或者先用wget先下载下来也可以,多尝试几次就能下载下来
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
验证集群可用性
等kube-system空间下的pod都处于running状态后再测试集群的可用性
[root@k8s-m1 k8s-total]# cat test-k8s.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
tier: frontend
replicas: 1
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
tier: frontend
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
##注意busybox的版本要1.28.4之前的版本,不然解析有问题
[root@k8s-m1 k8s-total]# kubectl get po,svc
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/busybox 1/1 Running 0 5m23s 10.244.0.4 k8s-m2 <none> <none>
pod/my-nginx-5b8555d6b8-vxcsj 1/1 Running 0 20m 10.244.2.3 k8s-m1 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 436d <none>service/nginx ClusterIP 10.107.34.204 <none> 80/TCP 16m
service/nginx ClusterIP 10.107.34.204 <none> 80/TCP 20m tier=frontend
验证集群dns,使用nslookup或者dig都可以
[root@k8s-m1 k8s-total]# kubectl exec -ti busybox -- nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
[root@k8s-m1 k8s-total]# dig -t A kubernetes.default.svc.cluster.local. @10.96.0.10
#日常检查其他服务能否正常解析时也可以使用此命令
在master上curl nginx的svc的ip出现nginx的index内容即集群正常,例如我的nginx svc ip是10.107.34.204
[root@k8s-m1 k8s-total]# curl 10.107.34.204 -s
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
日志管理
以kube-apiserver为例将日志挂载出来方便管理(kube-controller-manager、kube-scheduler组件服务类似)
修改以下三处
#启动参数
spec:
containers:
- command:
- --logtostderr=false
- --log-dir=/var/log/kubernetes/kube-apiserver
- --v=2
#mount地址
volumeMounts:
- mountPath: /var/log/kubernetes/kube-apiserver
name: k8s-logs
#被挂载券设置
volumes:
- hostPath:
path: /var/log/kubernetes/kube-apiserver
type: DirectoryOrCreate
name: k8s-logs
kubelet日志(kubelet服务是用systemctl进行管理的非容器管理所以不用挂载),可以通过设置文件存放目录直接进行修改。文章来源:https://www.toymoban.com/news/detail-606751.html
[root@k8s-m1 manifests]# vim /etc/sysconfig/kubelet
--v=2 --logtostderr=false --log-dir=/var/log/kubernetes/kubelet
更多关于kubernetes的知识分享,请前往博客主页。编写过程中,难免出现差错,敬请指出文章来源地址https://www.toymoban.com/news/detail-606751.html
到了这里,关于【kubernetes系列】kubernetes之使用kubeadm搭建高可用集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!