垃圾回收算法
- 标记-清除
- 复制算法
- 标记-整理
现在垃圾收集器均采用分代收集策略,新生代由于98%的对象都是朝生夕死,复制算法更合适,只复制还存活的对象,工作量小,所以效率高。显然复制算法不适合老年代,因为老年代中的对象大部分是大对象,且长时间存活,复制算法效率太低。老年代使用标记-清除,标记-整理算法更合适。文章来源:https://www.toymoban.com/news/detail-607242.html
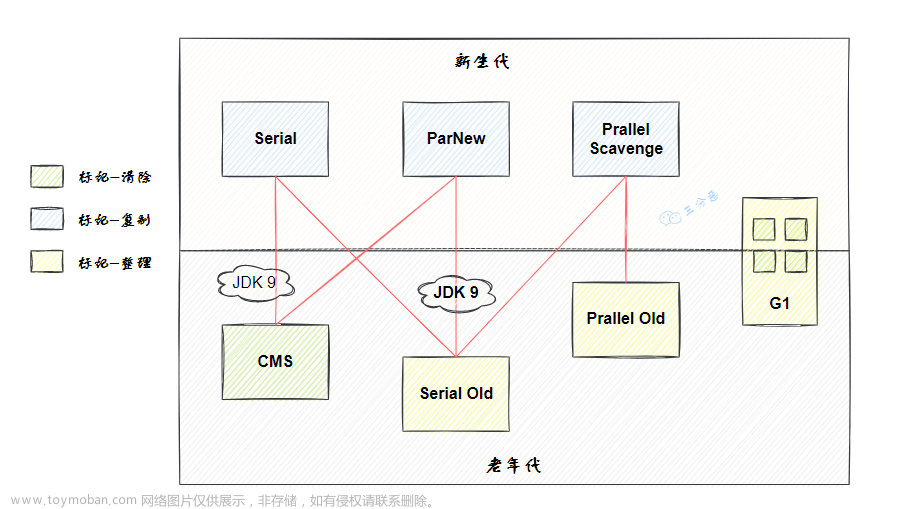
垃圾收集器
- serial/serial-old
单线程垃圾收集器,前者使用复制算法,适用新生代,后者使用标记-整理算法,用于老年代 - Parnew
多线程版本的serial,只是使用了多线程,但不是真正的并发,系统gc时用户线程还是要暂停(stop-the-world),使用复制算法,适用于新生代的垃圾回收 - Parallel Scavenge 收集器
复制算法,多线程,适用于新生代垃圾回收,和Parnew类似,但是不追求gc停顿时间,更关注吞吐量 - Parallel old
标记-整理算法,多线程、适用于老年代 - CMS
真正的并发垃圾收集器,标记-清除算法,适用于老年代。
执行步骤:
a. 初始标记 标记gc-root
b. 并发标记 gc-root tracing
c. 重新标记 标记并发期间增量改动的标记
d. 并发清除 并发执行内存回收
CMS缺点:
a. 标记-清除导致内存碎片太多,容易引起full-gc
b. 无法收集浮动垃圾(浮动:并发清除过程中新产生待标记的对象)
c. 对CPU资源敏感。默认启动的线程 (CPU+3)/4,在CPU较少时,占用较多资源,影响用户线程资源文章来源地址https://www.toymoban.com/news/detail-607242.html
- G1
a.基于标记-整理算法,不会引起内存碎片
b.可以准确的计算停顿时间,保证高吞吐的同时,降低gc停顿时间
G1将内存划分为相同大小的区域region,优先回收垃圾最多的区域,可以在有限时间内获得最大的垃圾收集效率。为什么gc时可达性分析不需要扫全内存区域,因为G1维护了一个remeberset,用来存储对象之间的依赖,只需要读取每个region的remeberset即可。
到了这里,关于温故而知新-JVM垃圾收集器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!