前言
一个python刚到门槛水平的程序员是如何使用crawlab爬取网站,在这里做个图文教程记录下。文章来源:https://www.toymoban.com/news/detail-607662.html
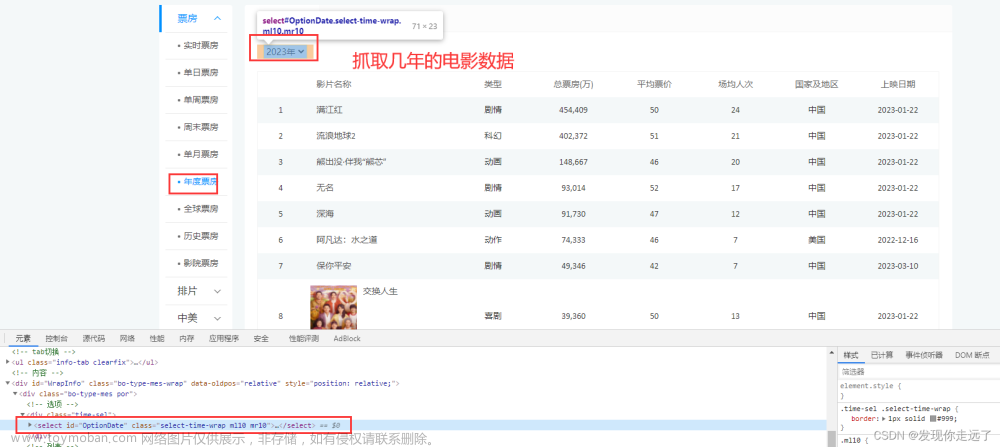
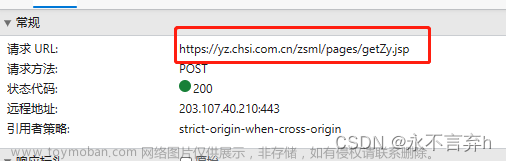
提示:这里做一个简单的网站爬取完整示例图文教程文章来源地址https://www.toymoban.com/news/detail-607662.html
一、创建项目
- 首先,我们将创建一个 Scrapy 项目,咱们从安装 Scrapy 开始。
pip install scrapy
- 然后,创建一个名叫 scrapy_quotes 的 Scrapy 项目。
到了这里,关于crawlab爬虫python篇(保姆级图文教程)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!