Kube Proxy
Kubernetes 在设计之初就充分考虑了针对容器的服务发现与负载均衡机制。 Service 资源,可以通过 kube-proxy 配合 cloud provider 来适应不同的应用场景。
Service相关的事情都由Node节点上的 kube-proxy处理。在Service创建时Kubernetes会分配IP给Service,同时通过API Server通知所有kube-proxy有新Service创建了,kube-proxy收到通知后通过 Iptables/IPVS 记录 Service和IP/端口 对应的关系,从而让Service在节点上可以被查询到。
kube-proxy还会监控Service和 Endpoint的变化,从而保证Pod重建后仍然能通过Service访问到Pod。
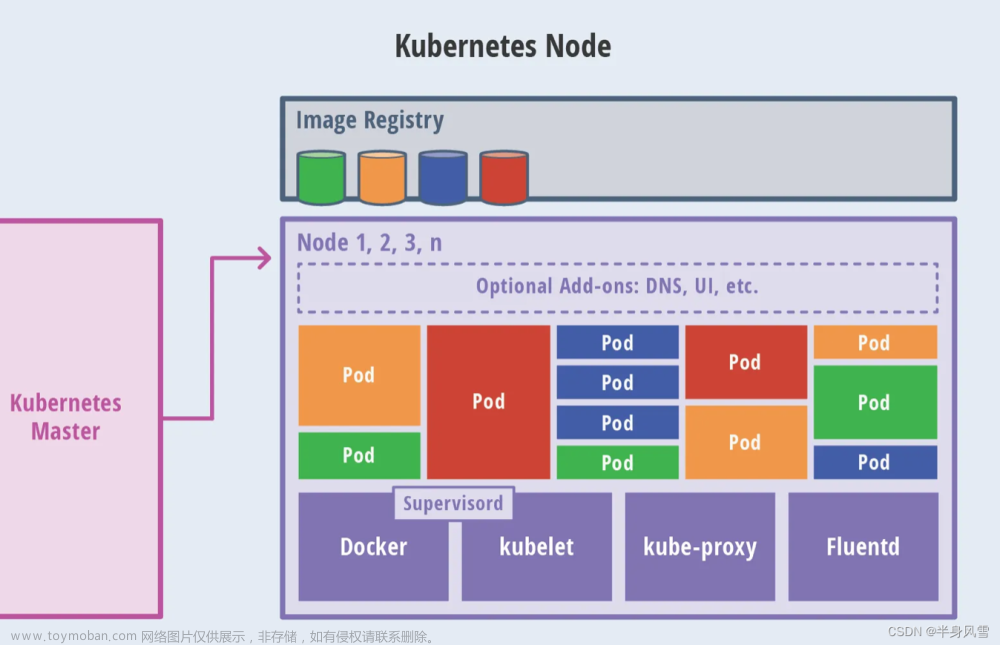
kube-proxy存在于各个node节点上
kube-proxy老版本默认使用的是 iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
目前,kubernetes 中的负载均衡大致可以分为以下几种机制,每种机制都有其特定的应用场景:
Service:直接用 Service 提供 cluster 内部的负载均衡,并借助 cloud provider 提供的 LB 提供外部访问
Ingress Controller:还是用 Service 提供 cluster 内部的负载均衡,但是通过自定义 Ingress Controller 提供外部访问
Service Load Balancer:把 load balancer 直接跑在容器中,实现 Bare Metal 的 Service Load Balancer
Custom Load Balancer:自定义负载均衡,并替代 kube-proxy,一般在物理部署 Kubernetes 时使用,方便接入公司已有的外部服务
Service 与 Endpoints和 Pod的关系

调度模式
基于Linux下的kube-proxy支持的3种调度模式
-
用户空间(Userspace) k8s 1.1版本前
-
iptables k8s 1.10版本以前
-
IPVS k8s 1.11版本之后,如果没有开启ipvs,则自动降级为iptables
Windows 上的 kube-proxy 只有一种模式可用:
kernelspace
kube-proxy 在 Windows 内核中配置数据包转发规则的一种模式
ipvs和iptables都是基于netfilter的,两者差别如下:
-
ipvs 为大型集群提供了更好的可扩展性和性能
-
ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
-
ipvs 支持服务器健康检查和连接重试等功能

Kube-proxy Iptables
kube-proxy监听Kubernetes API Server,一旦Service 和 EndpointSlice 对象有变化(service创建删除和修改, pod的扩张与缩小),就将需要新增的规则添加到 iptables中。
kube-proxy只是作为controller,而不是server,真正服务的是内核的netfilter,体现在用户态则是iptables。
kube-proxy的 iptables方式支持的负载分发策略:
-
RoundRobin(默认模式)
-
SessionAffinity
kubernetes只操作了filter和nat表
Filter表中:一个基本原则是只过滤数据包而不修改他们。
filter table的优势是小而快,可以hook到input,output和forward。这意味着针对任何给定的数据包,只有可能有一个地方可以过滤它。
NAT表:主要作用是在 PREROUTING 和 POSTROUNTING的钩子中,修改目标地址和 源地址。
与filter表稍有不同的是,该表中只有新连接的第一个包会被修改,修改的结果会自动apply到同一连接的后续包中。
kube-proxy 对 iptables 的链 进行了扩充:自定义了 KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP 五个链,并主要通过为KUBE-SERVICES chain 增加 规则(rule) 来配制traffic routing 规则。
查看nat表的OUTPUT链,存在kube-proxy创建的KUBE-SERVICE链
iptables -nvL OUTPUT -t nat
iptables -nvL KUBE-SERVICES -t nat |grep service-demo
接着是查看这条链,以1/3的概率跳转到其中一条
iptables -nvL KUBE-SVC-EJUV4ZBKPDWOZNF4 -t nat
最后KUBE-SEP-BTFJGISFGMEBGVUF链终于找到了DNAT规则
iptables -nvL KUBE-SEP-BTFJGISFGMEBGVUF -t nat
Kube-proxy IPVS
IPVS 模式在工作时,当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡kube-ipvs0,并为它分配 Service VIP 作为 IP 地址。
接着kube-proxy通过Linux的IPVS模块为这个 IP 地址添加三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 来作为负载均衡策略。
kube-proxy监听API Server中service和endpoint的变化情况,调用netlink 接口创建相应的ipvs 规则,并定期将ipvs规则与 Services和 Endpoints同步。
IPVS代理模式基于netfilter hook函数,该函数类似于iptables模式,但使用hash表作为底层数据结构,在内核空间中工作。这意味着IPVS模式下的kube-proxy使用更低的重定向流量。其同步规则的效率和网络吞吐量也更高。
IPVS 模式支持更多的负载均衡策略
- 轮询(Round Robin,RR):依次将请求分配到后端服务器,循环往复。
- 加权轮询(Weighted Round Robin,WRR):根据服务器的权重分配请求,权重越高的服务器被分配到的请求越多。
- 最少连接(Least Connections,LC):将请求分配到当前连接数最少的服务器。
- 源地址哈希(Source Hashing,SH):根据请求来源的 IP 地址进行散列,将相同 IP 地址的请求分配到同一台后端服务器上。
- 永不排队(never queue)
Service Selector
Service 通过标签来选取服务后端,一般配合 Replication Controller 或者 Deployment 来保证后端容器的正常运行。这些匹配标签的 Pod IP 和端口列表组成 endpoints,由 kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上。
在Kubernetes中,Selector是用于标识一组资源的标签选择器。这些资源可以是Pod、Service或者其他Kubernetes对象,通过在资源上定义标签,可以将它们组织成为相互关联的逻辑单元。Selector是访问这些逻辑单元的关键方式。 Selector的语法形式类似于CSS选择器,在Kubernetes中,我们可以通过使用逗号运算符和括号运算符对多个Selector进行组合,以实现更加复杂的选择方式。
如何使用Selector?
在Kubernetes中,Selector常被用于指定需要操作的对象,例如在创建Service时,需要通过Selector指定它所要代理的Pod。
以下是一个Service的例子,它通过Selector选择标签键为"app",值为"nginx"的Pod:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports: -
protocol: TCP
port: 80
targetPort: 80
在以上的配置文件中,selector字段用于指定Service所要代理的Pod。在这个例子中,Service将会代理所有标签键为"app",值为"nginx"的Pod,并将它们对外暴露在端口80上。
Pod DNS
种常见的 DNS 服务
- kube-dns 也是(Cluster DNS)
- CoreDNS
在 Kubernetes 1.11 及其以后版本中,推荐使用 CoreDNS
Kube-DNS
GitHub项目地址:https://github.com/kubernetes/dns

kube-dns 的 pod 中包含了 3 个容器
- kube-dns
- dns-dnsmasq
- dns-sidecar
各个容器功能:
kube-dns容器功能
- 提供service name域名的解析(用于k8s集群内部的域名解析),监视k8s Service资源并更新DNS记录
- 替换etcd,使用TreeCache数据结构保存DNS记录并实现SkyDNS的Backend接口
- 接入SkyDNS,对dnsmasq提供DNS查询服务
dnsmasq容器功能
- 对集群提供DNS查询服务
- 设置kubedns为upstream
- 提供DNS缓存,降低kubedns负载,提高性能
dns-sidecar容器功能
定期检查kubedns和dnsmasq的健康状态
为k8s活性检测提供HTTP API
CoreDNS
项目官网:https://coredns.io/
CoreDNS使用Go语言编写。What is CoreDNS?
CoreDNS实现非常灵活,几乎所有功能,都是以插件的方式实现,插件可以是独立使用,也可以协同完成 “DNS 功能”。
有一些插件与Kubernetes通信以提供服务发现,这些插件可以从文件或数据库中读取数据。
Miek Gieben 在 2016 年编写了 CoreDNS 的初始版本,在此之前他还写过一个叫作 SkyDNS 的 DNS 服务器,以及一个用 Go 语言写的 DNS 函数库 Go DNS。
可以通过维护 Corefile,即 CoreDNS 配置文件, 来配置 CoreDNS 服务器。与 BIND 的配置文件的语法相比,CoreDNS 的 Corefile 使用起来非常简单。作为一个集群管理员,你可以修改 CoreDNS Corefile 的 ConfigMap, 以更改 DNS 服务发现针对该集群的工作方式。
CoreDNS的限制
目前 CoreDNS 仍然有一些特别的限制,使得它并不适合所有的 DNS 服务器场景。其中最主要的是,CoreDNS 不支持完整的递归(recursion)功能;即,CoreDNS 不能从根 DNS 命名空间开始处理查询。查询根 DNS 服务器并跟踪引用直到从某个权威 DNS 服务器返回最终结果,需要依赖其他 DNS 服务器(通常称为转发器(forwarder))来实现。
Corefile 配置
在 Kubernetes 中,CoreDNS 安装时使用如下默认 Corefile 配置:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Corefile 配置包括以下 CoreDNS 插件:
errors:错误记录到标准输出。
health:在
http://localhost:8080/health处提供 CoreDNS 的健康报告。 在这个扩展语法中,lameduck会使此进程不健康,等待 5 秒后进程被关闭。ready:在端口 8181 上提供的一个 HTTP 端点, 当所有能够表达自身就绪的插件都已就绪时,在此端点返回 200 OK。
kubernetes:CoreDNS 将基于服务和 Pod 的 IP 来应答 DNS 查询。 你可以在 CoreDNS 网站找到有关此插件的更多细节。
你可以使用
ttl来定制响应的 TTL。默认值是 5 秒钟。TTL 的最小值可以是 0 秒钟, 最大值为 3600 秒。将 TTL 设置为 0 可以禁止对 DNS 记录进行缓存。
pods insecure选项是为了与 kube-dns 向后兼容。你可以使用
pods verified选项,该选项使得仅在相同名字空间中存在具有匹配 IP 的 Pod 时才返回 A 记录。如果你不使用 Pod 记录,则可以使用
pods disabled选项。prometheus:CoreDNS 的度量指标值以 Prometheus 格式(也称为 OpenMetrics)在
http://localhost:9153/metrics上提供。forward: 不在 Kubernetes 集群域内的任何查询都将转发到预定义的解析器 (/etc/resolv.conf)。
cache:启用前端缓存。
loop:检测简单的转发环,如果发现死循环,则中止 CoreDNS 进程。
reload:允许自动重新加载已更改的 Corefile。 编辑 ConfigMap 配置后,请等待两分钟,以使更改生效。
loadbalance:这是一个轮转式 DNS 负载均衡器, 它在应答中随机分配 A、AAAA 和 MX 记录的顺序。
DNS 记录
DNS 记录 Service
A/AAAA 记录
普通Service 和 没有集群 IP 的Headless Service 都会被赋予一个形如 my-svc.my-namespace.svc.cluster-domain.example 的 DNS A 和/或 AAAA 记录
与普通 Service 不同,无头Service(Headless Service)的DNS记录会被解析成对应 Service 所选择的 Pod IP 的集合。 客户端要能够使用这组 IP,或者使用标准的轮转策略从这组 IP 中进行选择。
SRV 记录
Kubernetes 根据 Service(普通 Service 或无头 Service 均可) 中的命名端口创建 SRV 记录。每个命名端口, SRV 记录格式为 _port-name._port-protocol.my-svc.my-namespace.svc.cluster-domain.example。
普通 Service,该记录会被解析成端口号和域名:my-svc.my-namespace.svc.cluster-domain.example。
无头 Service,该记录会被解析成多个结果,及该服务的每个后端 Pod 各一个 SRV 记录, 其中包含 Pod 端口号和格式为 hostname.my-svc.my-namespace.svc.cluster-domain.example 的域名。
DNS 记录 Pod
A/AAAA 记录
一般而言,Pod 会对应如下 DNS 名字解析:
pod-ip-address.my-namespace.pod.cluster-domain.example
例如,对于一个位于 default 名字空间,IP 地址为 172.17.0.3 的 Pod, 如果集群的域名为 cluster.local,则 Pod 会对应 DNS 名称:
172-17-0-3.default.pod.cluster.local
通过 Service 暴露出来的所有 Pod 都会有如下 DNS 解析名称可用:
pod-ip-address.service-name.my-namespace.svc.cluster-domain.example
DNS 配置策略
参阅:Pod 的 DNS 策略
每个Pod所使用的DNS策略,是通过pod.spec.dnsPolicy字段设置的,共有4种DNS策略:
- ClusterFirst:默认策略,表示使用集群内部的CoreDNS来做域名解析,Pod内/etc/resolv.conf文件中配置的nameserver是集群的DNS服务器,即kube-dns的地址。
- Default:“Default” 不是默认的 DNS 策略。Pod直接继承集群node节点的域名解析配置,也就是,Pod会直接使用宿主机上的/etc/resolv.conf文件内容。
- None:忽略k8s集群环境中的DNS设置,Pod会使用其dnsConfig字段所提供的DNS配置,dnsConfig字段的内容要在创建Pod时手动设置好。
- ClusterFirstWithHostNet:宿主机与 Kubernetes 共存,这种情况下的POD,既能用宿主机的DNS服务,又能使用kube-dns的Dns服务,需要将hostNetwork打开。
ClusterFirst
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mynginx
image: mynginx:v1
dnsPolicy: ClusterFirst # 字段设置为ClusterFirst(该值为默认值,不设置也是该值)
# namserver指向kube-dns service地址
$ kubectl exec mypod -- cat /etc/resolv.conf
nameserver 241.254.0.10
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
Default
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mynginx
image: mynginx:v1
dnsPolicy: Default
# pod内的resolv.conf与宿主机的resolv.conf一致
$ kubectl exec mypod -- cat /etc/resolv.conf
nameserver 192.168.234.2
search localdomain
$ cat /etc/resolv.conf
search localdomain
nameserver 192.168.234.2
None
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mynginx
image: mynginx:v1
dnsPolicy: None
dnsConfig:
nameservers: ["192.168.234.1","192.168.234.2"] # 最多可指定3个IP,当Pod的dnsPolicy设置为None时,列表必须至少包含一个IP地址
searches: # Pod中主机名查找的DNS搜索域列表
- default.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
kubectl exec mypod -- cat /etc/resolv.conf
nameserver 192.168.234.1
nameserver 192.168.234.2
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
ClusterFirstWithHostNet
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mynginx
image: mynginx:v1
hostNetwork: true # hostNetwork为true时,表示与宿主机共享网络空间
dnsPolicy: ClusterFirst # 即使dnsPolicy设置为集群优先,由于hostNetwork: true也会强制将dnsPolicy设置为Default
# 所以Pod内resolv.conf与宿主机相同
$ kubectl exec mypod -- cat /etc/resolv.conf
nameserver 192.168.234.2
search localdomain
对于以 hostNetwork 方式运行的 Pod,应将其 DNS 策略显式设置为 “ClusterFirstWithHostNet”。否则,以 hostNetwork 方式和 "ClusterFirst" 策略运行的 Pod 将会做出回退至 "Default" 策略的行为。
apiVersion: v1
kind: Pod
metadata:
name: mypod
labels:
app: mypod
spec:
containers:
- name: mynginx
image: mynginx:v1
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
#只有dnsPolicy: ClusterFirstWithHostNet,此时pod既可以使用宿主机网络也可以使用kube-dns网络
$ kubectl exec -it mypod -- cat /etc/resolv.conf
nameserver 241.254.0.10
search default.svc.cluster.local svc.cluster.local cluster.local localdomain
options ndots:5
Pod 的主机名设置优先级
Pod 规约中包含一个可选的 hostname 字段,可以用来指定一个不同的主机名。当这个字段被设置时,它将优先于 Pod 的名字成为该 Pod 的主机名(同样是从 Pod 内部观察)。
例如:给定一个 spec.hostname 设置为 “my-host” 的 Pod, 该 Pod 的主机名将被设置为 “my-host”。
Pod的子域名
Pod 规约还有一个可选的 subdomain 字段,可以用来表明该 Pod 是名字空间的子组的一部分。
例如:某 Pod 的 spec.hostname 设置为 “foo”,spec.subdomain 设置为 “bar”, 在名字空间 “my-namespace” 中,主机名称被设置成 “foo” 并且对应的完全限定域名(FQDN)为 “foo.bar.my-namespace.svc.cluster-domain.example”(还是从 Pod 内部观察)。
Ingress
Service是基于四层TCP和UDP协议转发的,而Ingress可以基于七层的HTTP和HTTPS协议转发,可以通过域名和路径做到更细粒度的划分,如下图所示。

https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/
Ingress 是对集群中服务的外部访问进行管理的 API 对象
Ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。

Ingress工作机制
要想使用Ingress功能,必须在Kubernetes集群上安装Ingress Controller。Ingress Controller有很多种实现,最常见的就是Kubernetes官方维护的NGINX Ingress Controller
对于所有 Kubernetes API,一旦它们被正式发布(GA),就有一个创建、维护和最终弃用它们的过程。Ingress-NGINX 将拥有独立的分支和发布版本来支持这个模型,与 Kubernetes 项目流程相一致。 Ingress-NGINX 项目的未来版本将跟踪和支持最新版本的 Kubernetes。
团队目前正在升级 Ingress-NGINX 以支持向 v1 的迁移, 你可以在此处跟踪进度。
同时,团队会确保没有兼容性问题:
-
更新到最新的 Ingress-NGINX 版本, 目前是 controller-v1.8.1。
-
Kubernetes 1.22 发布后,请确保使用的是支持 Ingress 和 IngressClass 稳定 API 的最新版本的 Ingress-NGINX。
-
使用集群版本 >= 1.19 测试 Ingress-NGINX 版本 v1.0.0-alpha.2,并将任何问题报告给项目 GitHub 页面。
外部请求首先到达Ingress Controller,Ingress Controller根据Ingress的路由规则,查找到对应的Service,进而通过Endpoint查询到Pod的IP地址,然后将请求转发给Pod。
参阅:
k8s中的endpoint
k8s 理解Service工作原理
K8s 核心组件讲解——kube-proxy
详解k8s 4种类型Service
kubernetes集群内部DNS解析原理、域名解析超时问题记录
CoreDNS简介
Kubernetes网络文章来源:https://www.toymoban.com/news/detail-607704.html
Service文章来源地址https://www.toymoban.com/news/detail-607704.html
到了这里,关于K8s Service网络详解(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!