[论文地址] [代码] [CVPR 23]
Abstract
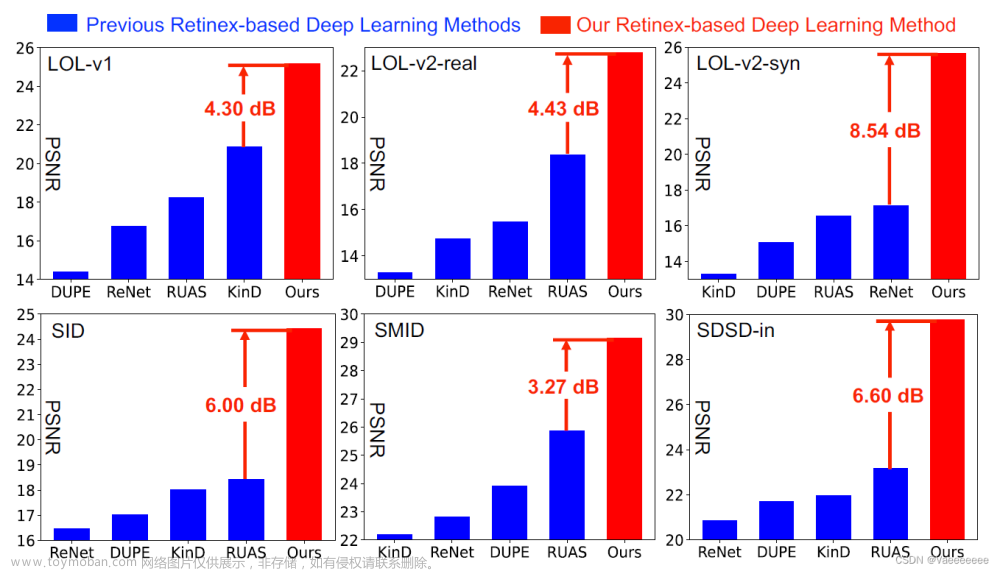
我们考虑了检测图像中低层次结构的通用问题,其中包括分割被操纵的部分,识别失焦像素,分离阴影区域,以及检测隐藏的物体。每个问题通常都有一个特定领域的解决方案,我们表明,一个统一的方法在所有这些问题上都表现良好。我们从NLP中广泛使用的预训练和提示调整协议中得到启发,并提出了一个新的视觉提示模型,即显式视觉提示(EVP)。与以往的视觉提示不同的是,我们的视觉提示是典型的数据集级别的隐性嵌入,我们的关键见解是强制执行可调整的参数,专注于每个单独图像的显性视觉内容,即来自冻结补丁嵌入和输入的高频成分的特征。在相同数量的可调整参数(每个任务5.7%的额外可调谐参数)下,提议的EVP明显优于其他参数高效的微调协议。与特定任务的解决方案相比,EVP在不同的低层次结构分割任务上实现了最先进的性能。
Overview
本文是做什么的: 做的是参数高效微调(Parameter-Efficient Tuning)。例如对一个参数量巨大的模型,调整其所有参数是十分低效的,可以设计算法以只调整网络的一小部分(额外的)参数来取得与完全调整相当的性能。
何为显式(Explicit) 现有的方法(例如Visual Prompt Tuning)其所利用的提示(Prompt)是隐式的,也就是直接加网络层进去让模型自己学,具体学的东西是什么不知道,但最后模型性能有提升;本文的Prompt则是强制学习了模型的一些底层的结构信息(FFT+IFFT取得的模型高频成分),这些底层结构信息所构成的"手工特征"能够大大提升Prompt的效果。
本文的核心思想其实比较类似于传统分割网络里面的boundary aware之类的方法,加额外的与图片相关的信息进去给网络学。
Method
本文的网络结构如下所示:![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations,划水](https://imgs.yssmx.com/Uploads/2023/07/608289-1.png)
虚线左边为Adapter的结构,虚线右边为整体结构。以SegFormer的Transformer backbone为例,本文主要加了以下几个东西,一个个来看:
-
Embedding Tune: 本文将Patch Embedding所得到的特征送入了一个Embedding Tune层。这么做的目的是辅助原始训练数据分布迁移到现在finetune的新数据上,思想类似于现有的VPT-Shallow。具体的网络实现则是一个线性层就可以搞定。需要注意的是,这个线性层对输入的Patch Embedding Feature进行了降维,具体降多少算是本文的一个超参。
-
HTC Tune 直接从原始图像中提取高频分量,作为手工特征以辅助finetune。具体的网络实现同样是使用一个线性层将提取的frequency map转化为特征。
-
Adapter 负责整合Embedding与HTC Tune获得的信息,并将其送入到Transformer backbone的每一层中去。其网络实现由三部分组成,分别为 M L P t u n e MLP_tune MLPtune, G E L U GELU GELU, M L P u p MLP_up MLPup,也就是两个线性层以及中间的GELU。将第二个MLP共享可以认为单纯是为了节省参数量(见消融实验)。文章来源:https://www.toymoban.com/news/detail-608289.html
Ablation Study
![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations,划水](https://imgs.yssmx.com/Uploads/2023/07/608289-2.png)
本文主要所提出来的东西也就是这个高频分量Adapter
F
h
f
c
F_{hfc}
Fhfc。可以看到该组件在Shadow和Forgery上的贡献较大,而在Defocus以及Camouflaged上的贡献有限。事实上,对于Defocus以及Camouflaged这两个任务,修改单一的设计几乎都不会对最终结果有较大的影响。文章来源地址https://www.toymoban.com/news/detail-608289.html
到了这里,关于[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!