一、基础环境准备
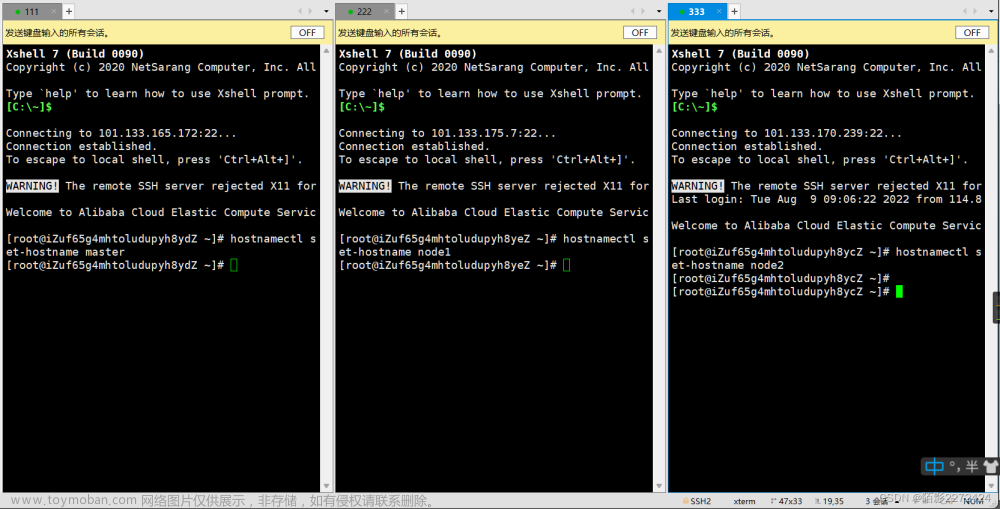
你好! 本文实验在Windows11安装的VMware Workstation Pro 17.0上,建立3台带Ubuntu22.04操作系统的虚拟机(master-100, k8s_worker1, k8s_worker2)为环境。
1.1 VMware Workstation Pro 17.0
官网下载:
https://www.vmware.com/cn/products/workstation-pro.html
有30天免费试用、度娘或者一键三连+评论我给你发许可证
1.2 Ubuntu22.04
https://ubuntu.com/download/desktop
虚拟机配置:2核CPU,4G内存,40G系统盘
安装步骤可以看我的另一篇文章
二、系统环境配置
2.1 设置Master与工作节点的机器名称及配置
##查ubuntu版本
lsb_release -a
#IP地址和主机名称修改
hostname $hostname
sudo hostnamectl set-hostname master-100
如果在VMware新建虚拟机时设置好了,不设也没什么关系。名字也是由你自己改,改个不一样的就知道自己在干嘛了。
2.2 解析主机
sudo gedit /etc/hosts
#写入以下内容
192.168.159.129 master-100
192.168.159.130 k8s-worker1
192.168.159.131 k8s-worker2
#或者,使用这种方式追加
cat >> /etc/hosts << EOF
192.168.159.129 master-100
192.168.159.130 k8s-worker1
192.168.159.131 k8s-worker2
EOF
记得换成自己机子IP地址和主机名
2.3 虚拟内存swap分区关闭
# 临时/永久关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#检查
free -m
#这一步可能会影响kubeadm init,如果后面初始化失败了,可以再检查一下分区是否关闭。Swap total是0才对。
2.4 开启IPv4转发
sudo cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
modprobe overlay
modprobe br_netfilter
sudo cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
有什么作用?
开启这些设置使通过网桥的数据包由主机系统上的iptables规则处理,默认关闭,设置为1则开启
2.5 设置时间同步
sudo apt install -y chrony
sudo systemctl restart chrony
sudo systemctl status chrony
chronyc sources
chrony是一个开源自由的网络时间协议 NTP 的客户端和服务器软软件。它能让计算机保持系统时钟与时钟服务器(NTP)同步,因此让你的计算机保持精确的时间,chrony也可以作为服务端软件为其他计算机提供时间同步服务。
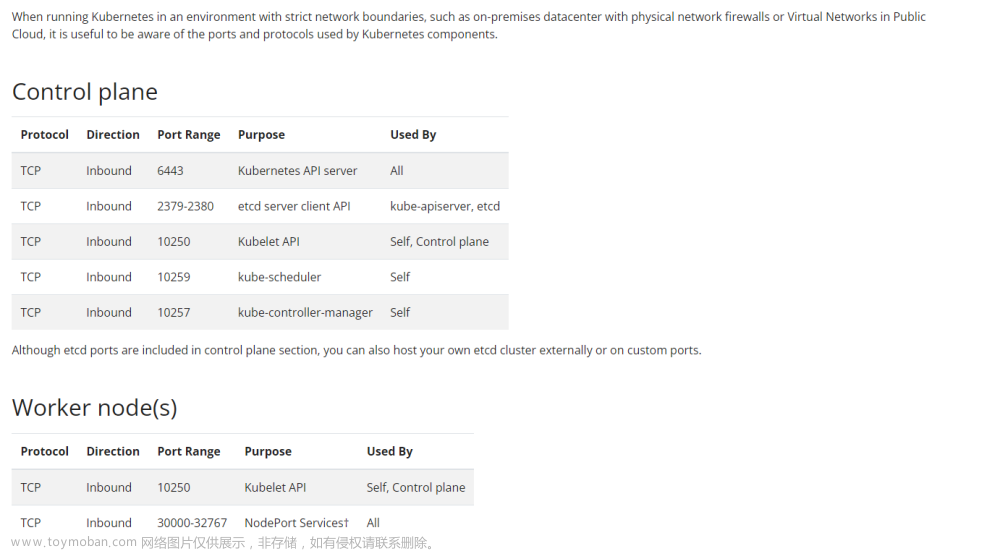
2.6 开启防火墙的端口(可选)
# kube-apiserver的安全端口6443
# 用于接收认证授权的HTTPS请求,对外服务
sudo ufw enable
sudo ufw allow 6443
sudo ufw status
enable做完需要重启ubuntu,建议先不做。
ubuntu的ufw默认是disable的,网上有教程直接关闭整个防火墙
我看到有教程说:关闭防火墙会在kubeadm过程中出现超时现象(但我没遇到)
如果enable了想要远程连接ssh,记得把22端口也allow一下
三、安装集群所需软件
上面初始化配置完成后,下面开始安装docker
3.1 安装 docker
#1.卸载旧版本(if need)
sudo apt-get remove docker docker-engine docker.io containerd runc
#2.更新apt包索引并安装包以允许apt在HTTPS上使用存储库
sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
#3.添加Docker官方GPG密钥 # -fsSL(apt-key list可以查看已安装的密钥)
curl https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
#4.设置稳定存储库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
#5.安装特定版本的Docker引擎,请在repo中列出可用的版本
apt-cache madison docker-ce
#6.如果想要跟我的版本就在这一步装对应的,一般来说直接装最新的问题不大,遇到问题再解决
sudo apt-get update && sudo apt-get install -y docker-ce docker-ce-cli containerd.io
#7.修改仓库镜像以及docker启动项---docker的cgroup在这里设置成了systemd
mkdir -vp /etc/docker/
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://reg-mirror.qiniu.com",
"https://registry.docker-cn.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
#8.保存退出,更新设置
sudo systemctl daemon-reload
sudo systemctl start docker
sudo systemctl enable docker
#9.查看docker版本和状态
sudo docker version
sudo systemctl status docker
3.2 安装 cri-dockerd 组件
Docker 本身是一个容器运行时(Container Runtime),它负责管理容器的生命周期,包括创建、启动、停止和销毁等操作。然而,Docker 运行时在设计上并不符合 K8s 等容器编排工具的要求,因此需要使用 CRI (Container Runtime Interface) 来与容器编排工具进行交互。
组件地址:https://github.com/Mirantis/cri-dockerd/releases,下载本文对应的版本或者最新版本,虚拟机网络好的可以直接在系统里面下。或者主机下载好用winSCP传进去。
注意:Ubuntu应该下载deb包,CentOS是rpm包。
#1. 安装cri-dockerd
sudo dpkg -i cri-dockerd_0.3.4.3-0.ubuntu-jammy_amd64.deb
#2. 调整启动参数
sudo sed -i -e 's#ExecStart=.*#ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7#g' /lib/systemd/system/cri-docker.service
实验时两个worker从节点的cri-docker启动后日志一直都有输出报错,所以这个参数我查了很久很多资料,也有建议–network-plugin=可以先不写cni的,也没说原因…
#3. 设置开机自启动和查看cri-docker状态
sudo systemctl daemon-reload
sudo systemctl enable cri-docker
sudo systemctl status cri-docker
报错提示:
使用sudo systemctl status cri-docker 查看状态的时候,不止要留意是否running,还要下面最新的输出日志有没有报错。
启动之后的此报错可能要把master的flanned复制过去,原因未知。
https://blog.csdn.net/qq_45323089/article/details/129626414

3.3 安装 Kubernetes
#1.安装依赖
sudo apt-get install -y apt-transport-https ca-certificates curl
#2.安装GPG密匙
#参考一
# 阿里云
# 下载 gpg 密钥 这个需要root用户否则会报错
sudo curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
# 添加 k8s 镜像源 这个需要root用户否则会报错
sudo cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
# 华为云(和阿里云二选一)
# 下载 gpg 密钥(华为云)
curl http://mirrors.huaweicloud.com/kubernetes/yum/doc/apt-key.gpg | apt-key add -
# 添加 k8s 镜像源(华为云)
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://mirrors.huaweicloud.com/kubernetes/apt/ kubernetes-xenial main
EOF
记录一下:参考二这个是官网给的命令换成aliyun的,也是我参考教程里提供的,但是在第3步执行更新的时候会报错,说我的the public key is not available: NO_PUBKEY XXXXXXXX,然后我参考网上各种解决这个问题的办法尝试了都还是不行。主要也是看到官网给的命令格式就是这样的,完全没怀疑过是写进去的配置文件的内容有问题。后面我改了发现可以之后也很惊讶,可能是这个sign by的问题,也可能是没有完全按照官网给的命令。
官网手册链接:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
#参考二
sudo curl -fsSLo /usr/share/keyrings/kubernetes-archive-keyring.gpg https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg
sudo echo "deb [signed-by=/usr/share/keyrings/kubernetes-archive-keyring.gpg] http://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
#3. 更新软件源
sudo apt-get update
#4. 查看Kubernetes可用版本
apt-cache madison kubeadm
#5. 安装三件套
sudo apt-get install -y kubelet=1.27.0-00 kubeadm=1.27.0-00 kubectl=1.27.0-00
# Ubuntu使用不同的软件源,对软件版本的命名会有所不同,aliyun的源在结尾会有 -00下载对应版本的kubernetes组件
#6. 标记软件包,防止自动更新
sudo apt-mark hold kubelet kubeadm kubectl
#7. 配置kubelet
mkdir /etc/sysconfig
sudo gedit /etc/sysconfig/kubelet
#复制以下内容,保存退出
KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=/run/cri-dockerd.sock“
#8. 启动kubelet
systemctl enable --now kubelet
#9. 如果这个时候手贱想看一下kubelet的状态
systemctl status kubelet
结果显示如下:
3月 25 14:32:19 westwell systemd[1]: kubelet.service: Main process exited, code=exited, status=255/n/a
3月 25 14:32:19 westwell systemd[1]: kubelet.service: Unit entered failed state.
3月 25 14:32:19 westwell systemd[1]: kubelet.service: Failed with result ‘exit-code’.
经网上查阅,重新安装(或第一次安装)k8s,未经过kubeadm init 或者 kubeadm join后,kubelet会不断重启,这个是正常现象……,执行init或join后问题会自动解决,对此官网有如下描述,也就是此时不用理会kubelet.service。
“The kubelet is now restarting every few seconds, as it waits in a crashloop for kubeadm to tell it what to do. This crashloop is expected and normal, please proceed with the next step and the kubelet will start running normally.”
备注:journalctl -xefu kubelet 可查看systemd 日志查看具体报错信息。
参考链接:https://blog.csdn.net/u010420283/article/details/105095811
以上内容是所有节点都要执行的,下面的操作步骤会分master节点和Node节点
四、单实例K8s集群部署
4.1 Master节点初始化
#1. 查看初始化需要的镜像
sudo kubeadm config images list --image-repository registry.aliyuncs.com/google_containers
#2. 拉取镜像
sudo kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers --cri-socket unix:///run/cri-dockerd.sock
#3.初始化节点,注意endpoint要写你自己的master机子的IP
sudo su
sudo kubeadm init --control-plane-endpoint=192.168.159.129 --kubernetes-version=v1.27.0 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --token-ttl=0 --cri-socket unix:///run/cri-dockerd.sock --upload-certs --image-repository registry.aliyuncs.com/google_containers
一般有问题都集中在这一步了体现的
如果你init失败后想再尝试,需要reset一下,或者你把它报错说already的文件都删了再重启一下
kubeadm reset --cri-socket unix:///run/cri-dockerd.sock
报错提示:
kubernetes failed to create kubelet: misconfiguration: kubelet cgroup driver: “cgroupfs” is differen…
看下docker和k8s用的是不是同一个。前面安装docker有设置cgroups是systemd
kubelet修改方法:
方法一:修改下面的文件(我用的)
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#添加新字符串
#Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
#将 $KUBELET_CGROUP_ARGS 变量添加到 ExecStart 部分
#无论哪个方法改完记得重启
systemctl daemon-reload
systemctl restart kubelet
改好之后长这样,可以参考一下:
参考资料:https://www.javaroad.cn/questions/33906
方法二,我没试过
在 /etc/sysconfig/kubelet 文件中,修改 --cgroup-driver= 参数。
例如修改为 --cgroup-driver=systemd
还有你们遇到报错网上找资料的时候,要认真看下别人用的是不是cri-docker,还是用的containerd 作为CRI,自己用containerd的可以参考一下
https://www.cnblogs.com/wod-Y/p/17043985.html
http://tihar-tech.cn/?p=2675#qi_yongcontainerd_zuo_weiCRI
当你成功后,记住最后kubeadm join那条指令,后续用于node节点加入集群。
#4.配置环境变量,在su环境下
export KUBECONFIG=/etc/kubernetes/admin.conf
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
还有一步是安装网络插件flannel或者一众你在网上搜到的,不过我经验之谈,最后再做,就是先把集群搭好。
#5.查看master节点状态,如果你没装flannel现在就是NotReady的状态
kubectl get nodes
4.2 Worker节点加入集群
#利用前面保存的命令加入集群
#末尾加上–cri-socket unix:///run/cri-dockerd.sock
kubeadm join 192.168.159.129:6443 --token 4pbkph.rlxyn0okw1x90k1v \
--discovery-token-ca-cert-hash sha256:b61fdd230becdda0ead34d861e857836c91494a68fee00a24c6eca993767896a
--cri-socket unix:///run/cri-dockerd.sock
如果你前面搞了那个admin.conf,不然就回master节点查,可以看到集群已经搭好,只是都是Not Ready的
kubectl get nodes
4.3 安装网络插件flannel
#这一步所有机子都要
wget https://github.com/flannel-io/flannel/releases/download/v0.20.1/flanneld-amd64
sudo mkdir /opt/bin
sudo cp flanneld-amd64 /opt/bin/flanneld
sudo chmod +x /opt/bin/flanneld
#这一步只需要主机执行
sudo kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
# 或者,建议分成几步做
# 下载flannel插件的yml
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 修改kube-flannel.yml中的镜像仓库地址为国内源
sed -i 's/quay.io/quay-mirror.qiniu.com/g' kube-flannel.yml
# 安装网络插件
kubectl apply -f kube-flannel.yml
如果发现执行的时候报错,可以配置一下hostname。
最后见证奇迹的时候,打完收工!可能要等几分钟,如果你等了5分钟以上都没好,恭喜你!可以到最下面找答案了
kubectl get nodes

常见错误:(网上整理的,有点旧了,可以参考一下,不保真)
https://blog.csdn.net/qq_34857250/article/details/82562514
-
“command failed” err=“failed to load kubelet config file, error: failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file “/var/lib/kubelet/config.yaml”, error: open /var/lib/kubelet/config.yaml: no such file or directory, path: /var/lib/kubelet/config.yaml”
解决办法:执行kubeadm init就会生成相应的配置文件 -
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the ‘criSocket’ field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
To see the stack trace of this error execute with --v=5 or higher
解决办法:加选项指定使用的CRI -
Error getting node" err=“node “k8s-master01” not found”
解决办法:这种情况是apiserver-advertise-address地址有误
kubeadm config print init-defaults > kubenetes-init-config
vim kubenetes-init-config文章来源:https://www.toymoban.com/news/detail-608371.html
参考文章:https://blog.csdn.net/qq_41422448/article/details/127801206文章来源地址https://www.toymoban.com/news/detail-608371.html
到了这里,关于Ubuntu22.04部署K8s集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!