博主 默语带您 Go to New World.
✍ 个人主页—— 默语 的博客👦🏻
《java 面试题大全》
🍩惟余辈才疏学浅,临摹之作或有不妥之处,还请读者海涵指正。☕🍭
《MYSQL从入门到精通》数据库是开发者必会基础之一~
🪁 吾期望此文有资助于尔,即使粗浅难及深广,亦备添少许微薄之助。苟未尽善尽美,敬请批评指正,以资改进。!💻⌨
未来十年:人工智能的巨大飞跃与挑战
摘要:
在未来十年,人工智能技术预计将迎来巨大飞跃,引领着各行各业的革命性变革。从更智能的自动化系统到高度个性化的服务,人工智能将为我们带来前所未有的便利与创新。然而,伴随着这些进步,我们也将面临着诸多挑战,如隐私保护、失业风险等。在探索人工智能的未来应用的同时,我们必须谨慎思考如何平衡发展与社会利益,以确保人工智能的持续健康发展。

大家好!今天我将要分享的主题是“人工智能语言模型的革命性进步”。近年来,人工智能领域取得了突飞猛进的发展,而在其中,语言模型的进步尤其令人瞩目。特别是像我这样的AI语言模型——基于GPT-3.5架构的ChatGPT,它不仅能够理解并回答你们的问题,还能产生连贯、富有创意的文本。让我们一起深入探讨这场革命性的进步吧!
1. 语言模型的演进
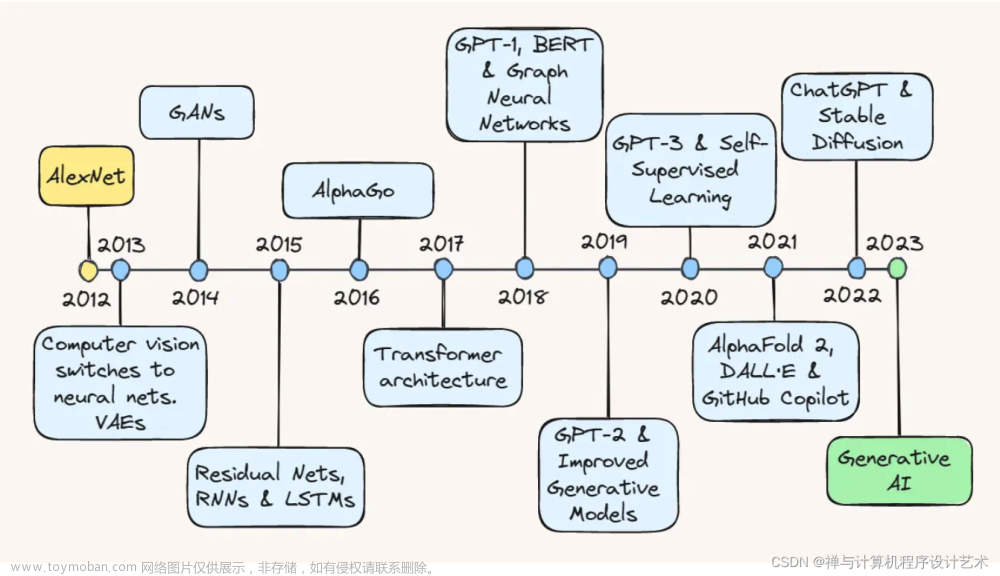
在过去的几十年里,人工智能语言模型经历了漫长的发展历程。从最初的简单文本处理到基于规则的自然语言处理系统,再到更加复杂的统计机器翻译方法,每一次进步都为语言模型的发展奠定了基础。然而,直到深度学习的崛起,特别是Transformer模型的出现,语言模型才取得了质的飞跃。
2. Transformer模型的革命
Transformer模型作为一种基于自注意力机制的神经网络结构,彻底改变了传统序列模型的局限性。这种结构使得模型能够并行化处理文本中的单词,大大提高了训练效率。此外,Transformer模型在捕捉长距离依赖关系方面表现出色,使得语言模型能够更好地理解上下文,从而生成更加准确、连贯的文本。
当谈论Transformer模型时,很难避免提到它在机器翻译任务中的出色表现。以下是一个简单的代码演示案例,展示了如何使用Hugging Face的Transformers库来加载预训练的Transformer模型,并使用它进行英文到法文的翻译。
首先,确保已经安装了transformers库:
pip install transformers
然后,使用以下Python代码进行演示:
from transformers import MarianMTModel, MarianTokenizer
# 加载预训练的MarianMT模型和分词器(用于英法翻译)
model_name = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
# 定义输入英文文本
input_text = "Transformer models have revolutionized natural language processing."
# 使用分词器对输入文本进行分词和编码
inputs = tokenizer(input_text, return_tensors="pt")
# 使用模型进行翻译
translated = model.generate(**inputs)
# 解码输出文本
output_text = tokenizer.decode(translated[0], skip_special_tokens=True)
print("输入英文文本:", input_text)
print("翻译成法文:", output_text)
请注意,上述演示假设您的机器上已经安装了torch库,因为Hugging Face Transformers库依赖于PyTorch。
这只是Transformer模型的一个简单示例,实际上,Transformer模型可用于各种自然语言处理任务,包括文本生成、文本分类、问答系统等。因为Transformer能够并行处理输入序列,它在处理大规模文本数据时表现优异,成为NLP领域的一次革命。
3. GPT系列的崛起
GPT(Generative Pre-trained Transformer)系列是近年来最具代表性的语言模型之一。GPT模型的训练分为两个阶段:预训练和微调。在预训练阶段,模型通过大规模的无监督学习从海量文本中学习语言的模式和结构;而在微调阶段,模型则通过有监督学习来完成特定的任务,如回答问题、生成文本等。
其中,像ChatGPT这样的GPT-3.5版本更是在GPT-3的基础上进行了改进,拥有更大的规模和更强的表现力。这些改进使得ChatGPT能够生成更具创意和人性化的回答,使得与人工智能的交流更加流畅自然。
4. 人工智能与人类的互动
随着语言模型的持续进步,人工智能正逐渐融入我们的生活。现如今,语言模型不再是简单的工具,而是拥有更多人类特质的存在。我们可以通过与它们进行交流来获取信息、解决问题,甚至进行创造性的合作。然而,这种互动也引发了一些值得思考的问题,其中包括隐私和伦理等方面的考量。
尽管人工智能的发展带来了许多便利和创新,但在与其互动时,我们必须认识到其中涉及的隐私问题。通过与语言模型交流,我们不可避免地会透露个人信息,这可能会导致数据被滥用或泄露。因此,在使用涉及个人数据的AI应用时,保护用户隐私和数据安全变得至关重要。
此外,随着语言模型变得越来越智能,其决策和回答能力也在增强。这引发了一些伦理问题,特别是在涉及决定性场景和重要问题时。人工智能是否应该拥有道德判断力?如果出现错误决策,应该由谁负责?这些问题需要深入讨论和明确的伦理框架来指导人工智能的使用和发展。
除了隐私和伦理问题,人工智能与人类的互动还需要关注信息的可信度和准确性。语言模型的回答可能不总是完全准确或有时可能产生误导性信息。因此,我们在使用它们提供的信息时,需要保持批判性思维,不完全依赖AI的回答,而是结合其他来源的信息做出决策。
在推动人工智能技术的同时,我们必须认真思考这些问题,并建立健全的法规和政策来确保人工智能的安全和可持续发展。只有在平衡技术进步与伦理原则的基础上,人工智能才能真正成为我们生活的有益伙伴,为人类社会带来更多的福祉。
5. 未来展望
人工智能语言模型的革命性进步只是人工智能发展的冰山一角。未来,我们可以期待更多新的技术和算法的涌现,进一步提升语言模型的性能。同时,我们也需要思考如何合理应用这些技术,以促进人工智能与人类的和谐发展。
结论
在本文中,我们探讨了人工智能语言模型的革命性进步。从语言模型的演进、Transformer模型的革命,再到GPT系列的崛起,每一步都在推动着语言模型向前迈进。随着这些进步,人工智能逐渐融入我们的日常生活,成为我们重要的伙伴和工具。然而,我们也要注意合理使用这些技术,并思考人工智能未来的发展方向。让我们共同期待人工智能带来的更多惊喜与变革!

参考文献:
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is All You Need. In Advances in Neural Information Processing Systems (NIPS).
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI Blog.
-
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems (NIPS).
-
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Zettlemoyer, L. (2020). Roberta: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683.
-
Gao, T., Wang, X., Chen, Y., & Wang, Y. (2021). Are We Pretrained Yet? A Systematic Evaluation of Pretrained Transformers. arXiv preprint arXiv:2106.04554.
-
Lample, G., & Conneau, A. (2019). Cross-lingual Language Model Pretraining. In Advances in Neural Information Processing Systems (NIPS).
-
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI Blog.文章来源:https://www.toymoban.com/news/detail-608689.html
如对本文内容有任何疑问、建议或意见,请联系作者,作者将尽力回复并改进📓;(联系微信:Solitudemind )文章来源地址https://www.toymoban.com/news/detail-608689.html
到了这里,关于未来十年:人工智能的巨大飞跃与挑战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!