spring:
datasource:
druid:
# 指定数据源类型为DruidDataSource
type: com.alibaba.druid.pool.DruidDataSource
# 数据库连接URL
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false
# 数据库用户名
username: root
# 数据库密码
password: "xx123!@#"
# 连接池初始化时创建的连接数
initialSize: 5
# 连接池中最大连接数
maxActive: 50
# 连接池中最小空闲连接数
minIdle: 5
# 连接池中最大空闲连接数
maxIdle: 10
# 获取连接时的最大等待时间(毫秒)
maxWait: 60000
# 间隔多久检测一次空闲连接(毫秒)
timeBetweenEvictionRunsMillis: 60000
# 连接池中连接最小空闲时间(毫秒)
minEvictableIdleTimeMillis: 300000
# 用于检测连接是否有效的SQL语句
validationQuery: SELECT 1
# 是否开启空闲连接的检测
testWhileIdle: true
# 是否开启连接的检测功能,在获取连接时检测连接是否有效
testOnBorrow: false
# 是否开启连接的检测功能,在归还连接时检测连接是否有效
testOnReturn: false
# 是否缓存PreparedStatement对象
poolPreparedStatements: true
# 缓存PreparedStatement对象的最大数量
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计用的filter,允许监控统计
filters: stat
# 配置扩展属性,用于监控统计分析SQL性能等
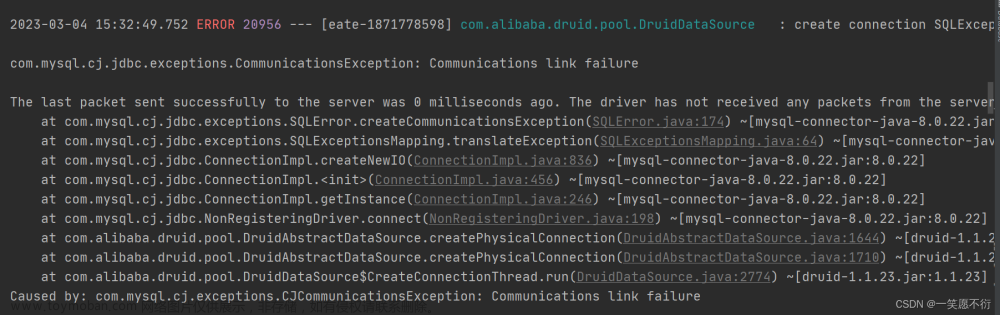
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=50001、type: 数据源类型,这里使用了Druid连接池的类型。
注意事项:使用Druid连接池的时候需要添加Druid连接池的依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency> 2、url: 数据库连接的URL。
注意事项:需要根据实际情况修改URL。
3、username: 数据库用户名。
4、password: 数据库密码
包含一些特殊字符的时候需要加引号。
5、initialSize: 连接池初始化时创建的连接数。
需要根据实际情况设置连接数。连接池创建连接时,会创建initialSize个连接,以确保应用程序在启动时可以立即获取到数据库连接。
6. maxActive: 连接池中最大连接数。需要根据实际情况设置最大连接数。如果连接池中连接数达到maxActive,则应用程序获取连接的请求将被阻塞,直到有连接被释放。
7. minIdle: 连接池中最小空闲连接数。 需要根据实际情况设置最小空闲连接数。如果连接池中空闲连接数少于minIdle,连接池会创建新的连接以达到minIdle。
8. maxIdle: 连接池中最大空闲连接数。 需要根据实际情况设置最大空闲连接数。如果连接池中空闲连接数超过maxIdle,连接池会关闭多余的连接以避免占用过多的资源。
9. maxWait: 获取连接时的最大等待时间。需要根据实际情况设置最大等待时间。如果连接池中没有可用连接且已经达到最大连接数,则应用程序获取连接的请求将被阻塞,最多等待maxWait毫秒。
10. timeBetweenEvictionRunsMillis: 间隔多久检测一次空闲连接(毫秒)。 需要根据实际情况设置检测间隔时间。连接池会定期检查空闲连接的状态,如果空闲时间超过minEvictableIdleTimeMillis,则将连接关闭。
11. minEvictableIdleTimeMillis: 连接池中连接最小空闲时间(毫秒)。 需要根据实际情况设置最小空闲时间。连接池会定期检查空闲连接的状态,如果空闲时间超过minEvictableIdleTimeMillis,则将连接关闭。
12. validationQuery: 用于检测连接是否有效的SQL语句。 需要根据实际情况设置SQL语句。连接池会使用这个SQL语句来检测连接是否有效。
13. testWhileIdle: 是否开启空闲连接的检测。 需要根据实际情况设置是否开启空闲连接的检测。如果开启,连接池会定期检查空闲连接的状态。
14. testOnBorrow: 是否开启连接的检测功能,在获取连接时检测连接是否有效。
需要根据实际情况设置是否开启连接的检测功能。如果开启,连接池在获取连接时会检查连接是否有效。
15. testOnReturn: 是否开启连接的检测功能,在归还连接时检测连接是否有效。 需要根据实际情况设置是否开启连接的检测功能。如果开启,连接池在归还连接时会检查连接是否有效。
16. poolPreparedStatements: 是否缓存PreparedStatement对象。需要根据实际情况设置是否缓存PreparedStatement对象。如果开启,连接池会缓存PreparedStatement对象以提高性能。
17. maxPoolPreparedStatementPerConnectionSize: 缓存PreparedStatement对象的最大数量。 需要根据实际情况设置缓存的最大数量。如果开启了缓存PreparedStatement对象,连接池会限制每个连接缓存的最大数量。文章来源:https://www.toymoban.com/news/detail-608733.html
maxPoolPreparedStatementPerConnectionSize是Druid连接池的一个配置项,用于配置连接池中缓存的PreparedStatement的最大数量。PreparedStatement是预编译的SQL语句,可以提高SQL执行的效率和安全性,避免SQL注入等安全问题。在使用Druid连接池时,当开启了缓存PreparedStatement功能时,每个连接都会缓存一定数量的PreparedStatement对象,以便在需要执行SQL语句时能够快速获取。而maxPoolPreparedStatementPerConnectionSize就是用于配置每个连接中缓存的PreparedStatement的最大数量。需要注意的是,缓存PreparedStatement虽然可以提高SQL执行的效率,但同时也会占用一定的内存资源。因此,需要根据实际情况进行合理配置。默认情况下,该属性的值为10。在上面的配置中,maxPoolPreparedStatementPerConnectionSize: 20表示将每个连接中缓存的PreparedStatement的最大数量设置为20个。
18. filters: 配置监控统计用的filter,允许监控统计。 如果要使用Druid的监控功能,需要配置此项。stat表示使用Druid的监控功能。
19. connectionProperties: 配置扩展属性,用于监控统计分析SQL性能等。 druid.stat.mergeSql和druid.stat.slowSqlMillis是两个与SQL监控有关的属性。
druid.stat.mergeSql用于配置是否合并SQL。当该属性设置为true时,Druid会将相同的SQL语句合并为一条,以节省SQL统计的开销和提高统计精度。默认情况下,该属性的值为false。
druid.stat.slowSqlMillis用于配置SQL执行的时间阈值,单位为毫秒。当一条SQL执行的时间超过该阈值时,Druid会将该SQL记录到慢SQL列表中,以便进行分析和优化。默认情况下,该属性的值为3000毫秒。
在上面的配置中,druid.stat.mergeSql=true表示启用SQL合并功能,druid.stat.slowSqlMillis=5000表示将SQL执行的时间阈值设置为5000毫秒。这些属性的具体含义和配置方法,可以参考Druid的官方文档。文章来源地址https://www.toymoban.com/news/detail-608733.html
到了这里,关于数据库连接池druid参数详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!