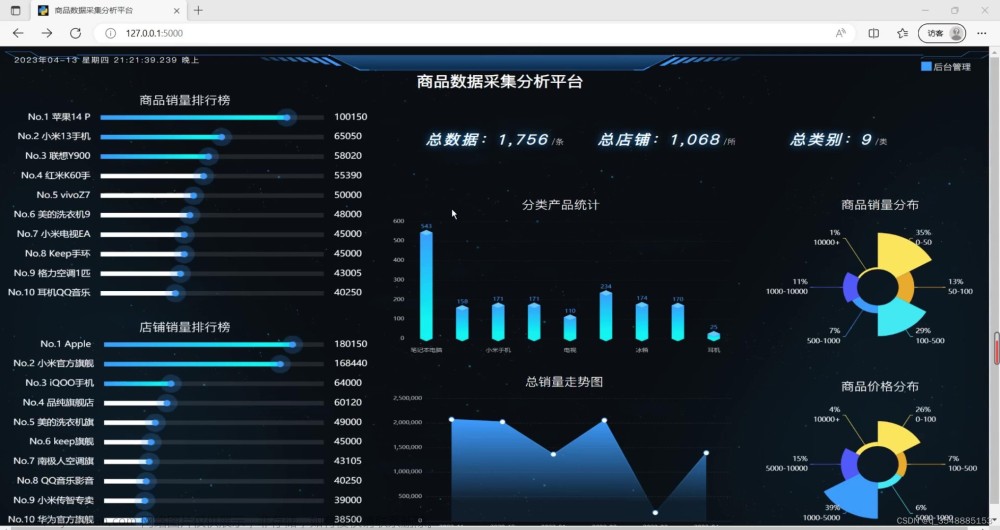
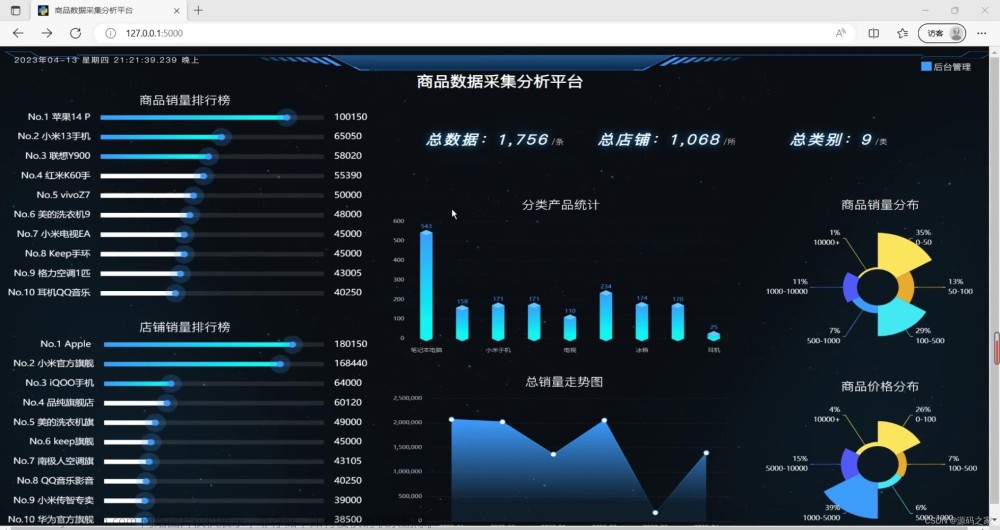
数据采集模块:
1.手机评论采集,数据信息(评论,评分,用户,评论发布时间)
爬取不同的手机评论,需要设置不同的id

如上图红圈处即为手机vivo S12的id
import requests
import csv
import re
import time
import json
comment_url = 'https://club.jd.com/comment/productPageComments.action'
csv_file = 'vivo S12 .csv'
f = open(csv_file, 'w', newline='', encoding='utf-8-sig')#文件名可以根据不同的手机更改
fieldnames = ['评论', '评分', '用户', '评论发布时间']
csvwriter = csv.DictWriter(f, fieldnames=fieldnames)
csvwriter.writeheader()
for i in range(100):
print('正在获取第', i + 1, '页评论')
page = i
params = {
'productId': 100017262415, #此处为不同手机的id,每个手机不同
'score': 3,
'sortType': 6,
'page': page,
'pageSize': 10,
'callback': 'fetchJSON_comment98',
'isShadowSku': 0,
'fold': 1
}
headers = {
'cookie': 'shshshfpa=980322f4-0d72-08ea-9cb2-4fcadde80a00-1562576627; shshshfpb=ymAFpsvPn5OjLe2TxXJVyZQ==; __jdu=16150341377512100580391; mt_xid=V2_52007VwMVUllZUF8fSx9aAWcAElNcXFtbHUEZbAYwVhdbDVkCRh9AEFsZYgdBBkEIVw1IVUlbA24KQVEPXFcIGnkaXQZnHxNaQVhbSx5AElgAbAITYl9oUWocSB9UAGIzEVVdXg==; unpl=V2_ZzNtbUBVREUmC0QBfkkMDGJRQlwSV0ATIQFGUnIZCwBnABRYclRCFnUUR1xnGl4UZwYZXEtcQRBFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHseXAFmARddQFFFEXULRlV6HVUEZQsSbXJQcyVFDENceRhbNWYzE20AAx8TcwpBVX9UXAJnBxNfR1dBE3MMRld7GF0BbgIQVUJnQiV2; PCSYCityID=CN_110000_110100_110108; user-key=0245721f-bdeb-4f17-9fd2-b5e647ad7f3e; jwotest_product=99; __jdc=122270672; mba_muid=16150341377512100580391; wlfstk_smdl=ey5hfakeb6smwvr1ld305bkzf79ajgrx; areaId=1; ipLoc-djd=1-2800-55811-0; __jdv=122270672|baidu|-|organic|not set|1632740808675; token=48ce2d01d299337c932ec85a1154c65f,2,907080; __tk=vS2xv3k1ush1u3kxvSloXsa0YznovSTFXUawXSawushwXpJyupq0vG,2,907080; shshshfp=3da682e079013c4b17a9db085fb01ea3; shshshsID=2ee3081dbf26e0d2b12dfe9ebf1ac9a8_1_1632744359396; __jda=122270672.16150341377512100580391.1615034138.1632740809.1632744359.28; __jdb=122270672.1.16150341377512100580391|28.1632744359; 3AB9D23F7A4B3C9B=OOGFR7VEBOKC3KPZ6KF3FKUOPTYV2UTP6I26CTJWT6CBR7KDFT6DA7AKGYBOIC5VE3AGWVCO44IPRLJZQM5VPBDKRE; JSESSIONID=82C0F348483686AC9A673E31126675D3.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'accept-charset': 'UTF-8'
}
resp = requests.get(comment_url, params=params, headers=headers)
if resp.status_code == requests.codes.ok:
regex = re.compile(r'fetchJSON_comment98\((.*?)\);')
json_str = regex.search(resp.text).group(1)
json_dict = json.loads(json_str)
for item in json_dict['comments']:
comment = item.get('content', '')
score = item.get('score', '')
user = item.get('nickname', '')
date_str = item.get('creationTime', '')
# 处理评论发布时间
date = time.strptime(date_str, '%Y-%m-%d %H:%M:%S')
date_str = time.strftime('%Y-%m-%d %H:%M:%S', date)
location_html = item.get('userClient', '')
print(location_html)
csvwriter.writerow({'评论': comment, '评分': score, '用户': user, '评论发布时间': date_str,})
print('添加评论:', comment)
time.sleep(1)
f.close()
print('评论抓取完成,共', i + 1, '页评论')结果展示:

数据预处理模块:
2.去除停用词以及词云图展示:
本节代码对多款手机的评论进行循环处理
此代码需要使用的stopwords.txt文件以上传至资源
import os.path
import jieba
import jieba.analyse
import jieba.posseg as pseg
import csv
from wordcloud import WordCloud
import pandas as pd
#定义需要遍历的文件名列表
file_list = ["vivo X90.csv", "vivo X80.csv", "vivo S16.csv", "vivo S15.csv", "vivo S12 .csv", "vivo IQOO 10.csv", "vivo iQOO Neo6 SE.csv", "vivo iQOO 11.csv", "vivo iQOO Neo8.csv"]
#加载停用词表
stopwords = []
with open("stopwords.txt", "r", encoding="utf-8") as f:
for line in f.readlines():
stopwords.append(line.strip())
#将评论数据进行分词和去除停用词处理
#循环遍历所有文件并读取处理
for file_name in file_list:
data = pd.read_csv(file_name, encoding="utf-8")
comments = []
for comment in data.iloc[:, 0]:
#去除停用词,分词
comment = [word for word in jieba.cut(comment) if word not in stopwords]
comment = " ".join(comment)
comments.append(comment)
print(comments)
#将分词处理后的数据组合成一个字符串
text = " ".join(comments)
# 生成词云
wordcloud = WordCloud(font_path="simhei.ttf", prefer_horizontal=1, min_font_size=10,
max_font_size=120, width=800, height=800, background_color='white',
collocations=False).generate(text)
#保存词云图像
filename = os.path.splitext(file_name)[0] + ".png"
wordcloud.to_file(filename)
#词云图展示(一部手机)

数据分析及可视化模块:
3.情感分析:
#导入包
#导入模块
import pandas as pd
import numpy as np
from collections import defaultdict
import os
import re
import jieba
import codecs#读取数据
#此处数据以经将多部手机的数据合并至同一csv文件,且增加了手机名称字段
data=pd.read_csv("vivo.csv",encoding='utf-8')
data.head()
#计算情感得分:
from snownlp import SnowNLP
# 评论情感分析
# f = open('earphone_sentiment.csv',encoding='gbk')
# line = f.readline()
with open('stopwords.txt','r',encoding='utf-8') as f:
stopwords=set([line.replace('\n','')for line in f])
f.close()
sum=0
count=0
for i in range(len(data['评论'])):
line=jieba.cut(data.loc[i,'评论']) #分词
words=''
for seg in line:
if seg not in stopwords and seg!=" ": #文本清洗
words=words+seg+' '
if len(words)!=0:
print(words) #输出每一段评论的情感得分
d=SnowNLP(words)
print('{}'.format(d.sentiments))
data.loc[i,'sentiment_score']=float(d.sentiments) #原数据框中增加情感得分列
sum+=d.sentiments
count+=1
score=sum/count
print('finalscore={}'.format(score)) #输出最终情感得分 
#在不同手机下的情感得分
#情感值以方法一计算的作为值
#获取同一列中不重复的值
a=list(data['手机名称'].unique())
sum_scores=dict()
#求对应主题的情感均值
for r in range(len(a)):
de=data.loc[data['手机名称']==a[r]]
sum_scores[a[r]]=round(de['sentiment_score'].mean(),2)
#不同手机情感得分可视化(柱状图)
import seaborn as sns
import matplotlib.pyplot as plt
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#数据可视化
sns.barplot(x=list(sum_scores.values()),y=list(sum_scores.keys()))
plt.xlabel('情感值')
plt.ylabel('手机型号')
plt.title('不同手机型号下的情感得分柱形图')
for x,y in enumerate(list(sum_scores.values())):
plt.text(y,x,'%s'%y,va='center')
plt.show() 
4.主题分析
这里仍采用合并后的数据集
import pandas as pd
import re
import jieba
from gensim import corpora, models
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
# 读取数据集
data = pd.read_csv('vivo.csv')
# 数据预处理,仅保留评论文本信息
stopwords = set()
with open("stopwords.txt", "r", encoding="utf-8") as f:
for line in f:
stopwords.add(line.strip())
text_data = []
for i in range(len(data)):
text = str(data.iloc[i]['评论'])
text = re.sub('[^\u4e00-\u9fff]', '', text) # 仅保留中文
text = " ".join([word for word in jieba.cut(text) if word not in stopwords]) # 分词
text_data.append(text)
# 构建词典并将文本转化为bag-of-words格式的文档集合
texts = [[word for word in document.split()] for document in text_data]
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
# 训练LDA主题模型
num_topics = 3
lda_model = models.LdaModel(corpus, num_topics=num_topics, id2word=dictionary)
# 生成关键词云
plt.figure(figsize=(10, 5))
for i in range(num_topics):
word_freq = Counter(dict(lda_model.show_topic(i, topn=20))) # 计算每个单词的出现频率
wc = WordCloud(background_color='white', font_path='msyh.ttc')
wc.generate_from_frequencies(word_freq) # 传入每个单词的出现频率生成词云
plt.subplot(1, num_topics, i+1)
plt.imshow(wc)
plt.axis('off')
plt.title(f'Topic #{i+1}')
plt.show()主题词云图:文章来源:https://www.toymoban.com/news/detail-609063.html
 文章来源地址https://www.toymoban.com/news/detail-609063.html
文章来源地址https://www.toymoban.com/news/detail-609063.html
到了这里,关于python数据采集课设-京东手机评论爬取与分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!