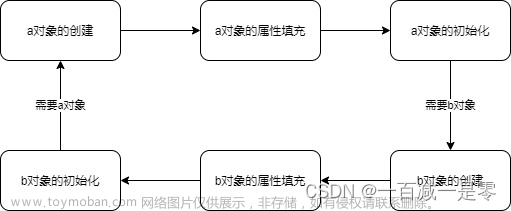
什么是循环依赖
注册一个bean对象的过程:
Spring扫描class得到BeanDefinition – 根据得到的BeanDefinition去生成bean – 现根据class推断构造方法 – 根据推断出来的构造方法,反射,得到一个对象 – 填充初始对象中的属性(依赖注入) – 如果原始对象种的某个方法被AOP了,那么要根据原始对象生成一个代理对象 – 把最终生成的代理对象放入单例池(singletonObjects,也叫一级缓存)中,下次getBea你就直接从单例池拿
循环依赖就是在依赖注入的时候相互注入,如
public class AService{
@Autowired
private BService bService;
}
public class BService{
@Autowired
private AService aService;
}
三级缓存过程
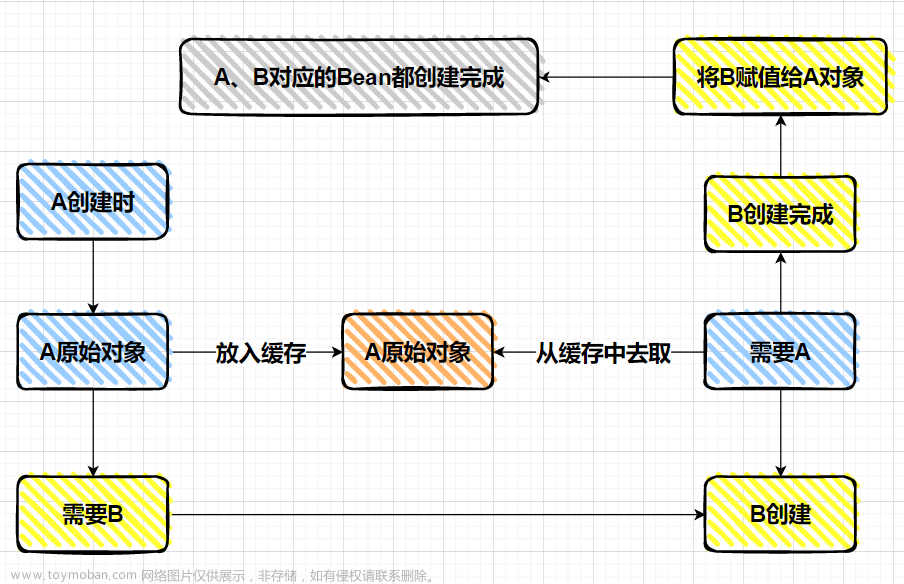
Spring使用了三级缓存的策略来解决循环依赖问题,过程大致如下
创建AService的bean:![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-1.png)
因为暂时还没有BService,所以创建个BService![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-2.png)
创建过程中,因为AService已经在三级缓存中出现过,所以会进行以下操作![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-3.png)
因为BService的属性都已经赋值了,所以BService的初始化就结束了,可以直接放到一级缓存中,完整过程为:![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-4.png)
此时BService已经实例化完成,那么AService中的依赖就可以进行注入了:![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-5.png)
完整流程图如下:![[Spring] 三级缓存解决循环依赖详解,spring,缓存,java](https://imgs.yssmx.com/Uploads/2023/07/609256-6.png)
简单的源码解析
首先在AbstractAutowireCapabaleBeanFactory类里(我是用ctrl+shift+alt+n找到的)的doCreateBean
先创造了一个bean原始对象,此时还没有依赖注入
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = (BeanWrapper)this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = this.createBeanInstance(beanName, mbd, args);
}
Object bean = instanceWrapper.getWrappedInstance();
然后将lambda表达式放入三级缓存中
if (earlySingletonExposure) {
if (this.logger.isTraceEnabled()) {
this.logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references");
}
//放入三级缓存,这个lambda表达式是为了执行aop生成代理对象用的,如果有aop操作,就会拿到代理对象出来
this.addSingletonFactory(beanName, () -> {
return this.getEarlyBeanReference(beanName, mbd, bean);
});
}
紧接着就是A的依赖填充
this.populateBean(beanName, mbd, instanceWrapper);
在这个里面会走到一个getSingleton方法,也就是在缓存中找BService
//allowEarlyReference是是否允许循环依赖
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && this.isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized(this.singletonObjects) {
//一级缓存中找
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
//二级缓存中找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
//三级缓存中找
ObjectFactory<?> singletonFactory = (ObjectFactory)this.singletonFactories.get(beanName);
if (singletonFactory != null) { //找到了
//这里相当于上面图文分析中BService在三级缓存中找到AService
//直接用lambda表达式注册,然后把他移动到二级缓存中
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
但是显然AService肯定不会找到,然后就会重新走到createBean,创建一个BService,与A一样走到上述的getSingleton,这时会在三级缓存中找到A,然后注入
填充完成之后就会把BService放到一级缓存中,移除三级缓存中的B,然后结束
exposedObject = this.initializeBean(beanName, exposedObject, mbd);
执行完整个BService的创建,上面的A的依赖填充才会结束,然后A也执行一遍exposedObject = this.initializeBean(beanName, exposedObject, mbd);这行代码,A也结束。文章来源:https://www.toymoban.com/news/detail-609256.html
结合图文演示看代码更容易理解捏文章来源地址https://www.toymoban.com/news/detail-609256.html
到了这里,关于[Spring] 三级缓存解决循环依赖详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!