LLaMA包含从7B到65B参数的基础语言模型集合。Meta在数万亿个tokens上训练了模型,LLaMA-13B在大多数基准测试中优于GPT-3(175B)。
来自:LLaMA: Open and Efficient Foundation Language Models
背景概述
在大量文本语料库上训练的大型语言模型已经显示出它们能够从文本指令或几个示例中执行新任务。当将模型scaling到足够的大小时,few-shot属性首次出现,导致一系列工作的重点是进一步scaling这些模型。这些工作是基于这样的假设:更多的参数将带来更好的性能。然而,大多数研究表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由经过更多数据训练的较小模型实现的(Training Compute-Optimal Large Language Models,Hoffmann)。
Hoffmann提出的目标是确定如何最佳地缩放特定训练计算预算的数据集和模型大小。然而,这个目标忽略了推理预算。在这种情况下,给定一个目标性能水平,首选模型不是训练速度最快的,而是推理速度最快的,尽管训练一个大模型以达到某个水平可能更容易,一个更小、训练时间更长的模型在推理上最终会更容易做到。例如,Hoffmann建议在200B tokens上训练10B的模型,但Meta发现即使在1T tokens之后,7B模型的性能仍在继续提高。
LLaMA的重点是训练一系列语言模型,通过训练比平时使用更多的tokens,在各种推理预算下实现最佳性能。其参数范围从7B到65B,与现有最佳LLM相比具有竞争力。例如,LLaMA-13B在大多数基准测试中优于GPT-3,尽管体积小了10倍。在更大的规模上,65B参数模型也可以与最好的大语言模型(如Chinchilla或PaLM-540B)竞争。
与Chinchilla,PaLM或GPT-3不同,Meta只使用公开可用的数据,从而与开源兼容,而大多数现有模型依赖于非公开可用的数据(例如"Books-2TB"或"Social media conversations")。也有一些例外,比如OPT、GPT-NeoX、BLOOM和GLM(GLM-130B: An Open Bilingual Pre-trained Model),但它们都不能与PaLM-62B或Chinchilla竞争。
方法
预训练数据

- 图1:7B,13B,33B和65B模型的训练tokens的训练损失。LLaMA-33B和LLaMA-65B在1.4T tokens上进行训练。较小的模型在1.0T tokens上进行训练。所有模型都以4M tokens的批处理大小进行训练。

- 表1:用于预训练的数据集混合。
LLaMA的训练数据集是几个来源的混合,如表1所示,涵盖了不同的领域。在大多数情况下,Meta重用了用于训练其他LLM的数据源,但限制是只使用公开可用的数据。这将带来以下混合数据及其在训练集中所代表的百分比:
-
English CommonCrawl:使用CCNet管道预处理了五个CommonCrawl dumps,范围从2017年到2020年。该过程在line级别上处理数据,使用fastText线性分类器执行语言识别以删除非英语页面,并使用n-gram语言模型过滤低质量内容。此外,Meta训练了一个线性模型,将维基百科中用作参考文献的页面与随机抽样页面进行分类,并丢弃被分类为参考文献的页面。
-
C4:在探索性实验中,发现使用不同预处理CommonCrawl数据集可以提高性能。因此,Meta在数据中包含了公开可用的C4数据集。C4的预处理还包含重复数据删除和语言识别步骤:与CCNet的主要区别在于质量过滤,主要依赖于启发式方法,如标点符号的存在或网页中单词和句子的数量。
-
Github:使用Google BigQuery上的公共GitHub数据集。只保留在Apache、BSD和MIT许可证下发布的项目。此外,使用基于行长度或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式删除样板文件,例如头文件。最后,在文件级别对结果数据集进行重复数据删除,并进行精确匹配。
-
Wikipedia:添加了2022年6月至8月期间的维基百科dumps,覆盖20种语言。已经删除超链接,注释和其他格式化样板。
-
Gutenberg and Books3:在训练数据集中包含了两个图书语料库:古登堡项目(Gutenberg Project),其中包含公共领域的图书;ThePile的Books3,这是一个用于训练大型语言模型的公开数据集。Meta在book级别执行重复数据删除,删除内容重叠超过90%的books。
-
ArXiv:Meta处理了arXiv Latex文件,添加到数据集中。删除了第一节之前的所有内容,以及参考文献,还删除了.tex文件中的注释,以及由用户编写的内联扩展的定义和宏,以增加论文之间的一致性。
-
Stack Exchange:包括了Stack Exchange的dumps,这是一个高质量的具有问题和答案的网站,涵盖了从计算机科学到化学的各种领域。Meta保留了来自28个最大网站的数据,从文本中删除了HTML标签,并按分数(从最高到最低)对答案进行了排序。
Tokenizer:Meta使用字节对编码算法对数据进行标记,使用来自sentence-piece的实现。值得注意的是,将所有数字拆分为单个数字,并退回到字节来分解未知的UTF-8字符。
总的来说,LLaMA的整个训练数据集在标记化(tokenization)后大约包含1.4T个tokens。对于大多数训练数据,每个token在训练期间只使用一次,除了Wikipedia和Books,Meta在其上执行大约两个epochs。
架构
网络基于transformer架构。并且Meta利用了后来方法提出的各种改进(如PaLM)。以下是与原始架构的主要区别,以及找到这种变化的灵感的地方:
- Pre-normalization[GPT3]:为了提高训练的稳定性,Meta对每个transformer子层的输入进行归一化,而不是对输出进行归一化,使用了由Zhang和Sennrich引入的RMSNorm归一化函数。
- SwiGLU activation function[PaLM]:为了提高性能,我们用Shazeer引入的SwiGLU激活函数取代了ReLU非线性。使用的维度是 2 3 4 d \frac{2}{3}4d 324d,而不是PaLM中的 4 d 4d 4d。
- Rotary Embeddings[GPTNeo]:删除了绝对位置嵌入(absolute positional embeddings),取而代之的是在网络的每一层添加由Su等人引入的旋转位置嵌入(rotary positional embedding)。
- 更多细节见表2。

- 表2:模型大小、架构和优化超参数。
Optimizer
模型使用AdamW优化器进行训练,具有以下超参数: β 1 = 0.9 \beta_1 = 0.9 β1=0.9, β 2 = 0.95 \beta_2 = 0.95 β2=0.95。使用余弦学习率调度,使得最终学习率等于最大学习率的10%。使用0.1的权重衰减和1.0的梯度裁剪。使用2000个warmup steps,并且根据模型的大小来改变学习率和批处理大小(见表2)。
有效的实现
Meta做了一些优化来提高模型的训练速度。首先,使用causal multi-head attention的有效实现来减少内存使用和运行时间。该实现可在xformers库中获得(https://github.com/facebookresearch/xformers)。这是通过不存储注意力权重和不计算由于语言建模任务的因果性质而被掩盖的key和query分数来实现的。
因果注意力(Causal Attention)是一种注意力机制,用于处理序列数据或图像数据中的因果关系。在传统的注意力机制中,每个位置或节点都可以关注其他位置或节点的信息,但在因果注意力中,只有当前位置或节点能够关注过去的位置或节点,而不能关注未来的位置或节点。
因果注意力主要应用于需要考虑时间顺序或图像中的空间关系的任务。
- 例如,在序列数据中,如语言模型或机器翻译任务中,因果注意力可以确保模型在生成当前位置的预测时只使用过去的信息,避免了信息泄漏或未来信息的依赖。
- 在图像数据中,因果注意力可以用于处理具有层次结构的图像数据,确保每个位置只关注其上一层次的位置。
一种常见的因果注意力机制是自回归性质的注意力机制。在自注意力机制中,通过引入遮蔽掩码(Masking)来限制注意力的范围,使得当前位置只能关注之前的位置,从而实现因果性。总之,因果注意力是一种限制了关注范围,使得模型只能关注过去信息的注意力机制,用于处理需要考虑因果关系的任务。
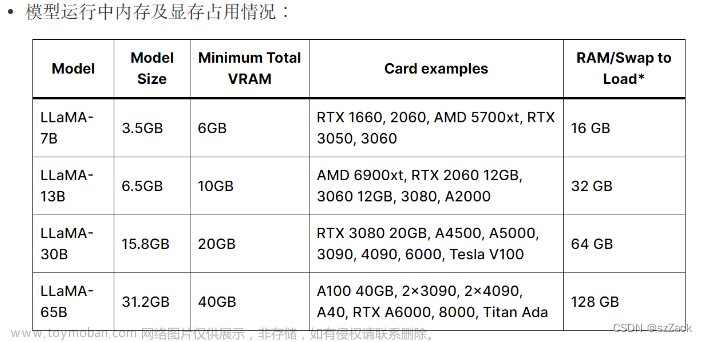
当训练65B模型时,Meta在 2048 A100 GPU 和 80GB RAM 上处理大约380个tokens/秒/GPU。这意味着在包含1.4T tokens的数据集上进行训练大约需要21天。
主要结果
主要测试了两类任务,Few-shot和zero-shot,并在20个基准上测试:
- Zero-shot:提供了任务的文本描述和测试示例。该模型要么使用开放式生成(open-ended generation)提供答案,要么对建议的答案(proposed answers)进行排序。
- Few-shot:提供了该任务的几个示例(在1到64之间)和一个测试示例。模型将此文本作为输入,并生成答案或对不同选项进行排序。
Meta将LLaMA与其他基础模型进行比较,包括非公开语言模型GPT-3、Gopher、Chinchilla和PaLM,以及开源的OPT模型、GPT-J 和GPTNeo。还简要地比较了LLaMA与指令微调(instruction-tuned)模型,如OPT-IML和Flan-PaLM。
Meta在自由格式生成任务(free-form generation tasks)和多项选择任务(multiple choice tasks)上评估了LLaMA。在多项选择中,目标是根据给定的上下文,从一组给定的选项中选择最合适的completion。在给定上下文的情况下,选择可能性最大的completion。
常识推理
Meta考虑了八个标准的常识推理基准:BoolQ,PIQA,SIQA,HellaSwag,WinoGrande ,ARC easy and challenge和OpenBookQA。这些数据集包括完形填空和Winograd风格的任务,以及选择题答案。Meta在Zero-shot设置中进行评估,就像在语言建模中一样。
在表3中,与现有不同规模的模型进行了比较。首先,LLaMA-65B在所有报告的基准测试中都优于Chinchilla-70B,但BoolQ除外。同样,除了在BoolQ和WinoGrande上,LLaMA-65B在所有方面都超过了PaLM540B。LLaMA-13B模型在大多数基准测试中也优于GPT-3,尽管体积小了10倍。

闭卷问答
Meta在两个闭卷问答基准上将LLaMA与现有的大型语言模型进行了比较:自然问题和TriviaQA。对于这两个基准,模型无法访问包含回答问题的证据的文档。在这两个基准上,LLaMA-65B在zero-shot和few-shot设置中实现了最先进的性能。更重要的是,LLaMA-13B在GPT-3和Chinchilla的这些基准测试中也具有竞争力,尽管它比GPT-3小5-10倍。该模型在推理过程中运行在单个V100 GPU上。
- Natural Questions和TriviaQA的格式化数据集示例。
阅读理解
根据RACE阅读理解基准评估模型。这个数据集是从为中国中学生和高中生设计的英语阅读理解考试中收集的。在基准测试中,LLaMA-65B与PaLM-540B具有竞争力,并且LLaMA-13B的性能优于GPT-3几个百分点。
数学推理
根据两个数学推理基准:MATH和GSM8k。MATH是一个用LaTeX编写的12K中学和高中数学问题的数据集。GSM8k是一组中学数学问题。Meta与PaLM和Minerva进行了比较。Minerva是一系列对从ArXiv和Math网页中提取的38.5B tokens进行微调的PaLM模型,而PaLM和LLaMA都没有对数学数据进行微调。maj1@k表示为每个问题生成k个样本并进行多数投票的评估。在GSM8k上,观察到LLaMA65B的性能优于Minerva-62B,尽管它尚未在数学数据上进行微调。
- MATH使用k=256个样本,GSM8k使用k=100个样本。
代码生成
Meta评估了模型在两个基准上根据自然语言描述编写代码的能力:HumanEval和MBPP。对于这两项任务,模型都会收到用几句话描述的程序,以及一些输入输出示例。在HumanEval中,它还接收一个函数签名,并且提示被格式化为自然代码,并在文档字符串中包含文本描述和测试用例。模型需要生成一个符合描述并满足测试用例的Python程序。另外,可以通过对特定于代码生成任务的tokens进行微调来提高代码生成的性能。
大规模多任务语言理解
Hendrycks等人引入大规模多任务语言理解基准(MMLU):由涵盖人文学科、STEM和社会科学等各个知识领域的多项选择题组成。Meta使用基准提供的示例,在5-shot设置中评估模型。在这个基准上,观察到LLaMA-65B在大多数领域中平均落后于Chinchilla70B和PaLM-540B几个百分点。一个潜在的解释是,在训练前的数据中使用了有限数量的书籍和学术论文,即ArXiv、Gutenberg和Books3,总计只有177GB,而其他模型是在高达2TB的书籍上训练的。Gopher、Chinchilla和PaLM使用的大量书籍也可以解释为什么Gopher在这个基准上优于GPT-3。
训练期间的性能变化
在训练过程中,Meta跟踪了模型在一些问答和常识基准上的性能,并在图2中进行了报告。在大多数基准测试中,性能稳步提高,并与模型的训练损失相关(见图1)。SIQA和WinoGrande是例外。最值得注意的是,在SIQA上,观察到性能有很多差异,这可能表明该基准不可靠。在WinoGrande上,表现与训练损失并不相关:LLaMA-33B和LLaMA-65B在训练中表现相似。
- 图2:训练期间问答和常识推理表现的变化。
关于指令微调:虽然未经微调的LLaMA-65B版本已经能够遵循基本指令,但观察到,非常少量的微调提高了MMLU上的性能,并进一步提高了模型遵循指令的能力。
LLM的预训练和微调
本节内容来自:https://zhuanlan.zhihu.com/p/643611622
预训练
基于Transformer自回归的LM的预训练方法是让模型做 Next Token Prediction 任务。基于GLM(General Language Model Pretraining with Autoregressive Blank Infilling)的LM的预训练方法是让模型做自回归空白填充任务(按照自编码的思路,从输入文本中随机地空白出连续的token,并按照自回归的思路,训练模型来依次重建这些token)。LLM由于规模大,权重维度高,参数量以及数据量多,因此会带来训练不稳定,难以收敛,耗时长,计算资源庞大等问题。
预训练之后,需要评价模型的性能。LM的常用评价指标PPL主要用于评价LM生成的句子是否流畅和通顺。除此之外,更重要的是评测LLM对下游任务的知识蕴含能力,包括常识推理,问答,代码处理,数学推理,阅读理解等多种能力。
prompt设计
和以往专家模型的 “预训练+微调” 范式不同,当前LLM主要采用 “预训练+上下文学习” 的范式,因此需要对每个下游任务选择合适的prompt模板,帮助模型回忆起自己预训练学到的知识,做到下游任务和预训练任务的统一。
模板是一个文本字符串,有两个部分:一个输入槽 [X],用于输入问题,一个输出槽 [Z],用于中间生成的答案。在实际操作中,为了让模型理解任务,用问题和答案 填充模板得到几个学习样例。然后用实际输入填充模板并和学习样例组合起来,得到完整的prompt一起输入模型。在情感分析任务中,模板的形式可以采用"[X], it is [Z].”。假设 X=“I like this dish” ,则完整的prompt则是“I like this dish, it is [Z].”。填充的答案在文本中间称为完形填空提示(cloze prompt),在文本末尾称为前缀提示(prefix prompt)。然后将生成的答案转换成任务需要的输出。下表展示了更多的示例。
NLP指令微调
经过预训练之后的LLM具有广泛的知识储备,拥有强大的自然语言推理和代码处理能力。但在某些任务上的Zero-Shot能力很差。为了进一步提高LLM在未见任务上的指令泛化能力,即Zero-Shot能力,需要在自然语言众包指令数据上微调预训练模型,参考论文FLAN。微调数据集来自于通用的NLP基准集,通过指令模板改造输入输出的格式得到CoT和非CoT任务的指令数据集。微调后可以显著提高在各种模型类(PaLM、T5、U-PaLM)、各种学习样例设置(Zero-Shot、Few-Shot、CoT)和各种未见评估基准(MMLU、BBH、TyDiQA、MGSM、开放式生成、RealToxicityPrompts)上的性能。
与人类对齐
该步骤的目的是使模型和人类对齐。通过使用用户的真实反馈对模型训练(SFT / RLHF),使LLM的输出更符合人类偏好,并与用户意图保持一致。这既包括明确的意图,如遵循指示,也包括隐含的意图,如保持诚实,不偏见,或其他有害的价值观。最关键的步骤是收集真实多样的指令以及回复,得到指令跟随数据集(问答形式)。同时,可以混合一些对话形式的指令跟随数据(把之前发生的所有对话都写进下一个问题的提示中),让LLM能够以对话形式和用户交流。文章来源:https://www.toymoban.com/news/detail-609346.html
- SFT:首先收集大量的
<指令,回复>数据对,得到一个指令跟随数据集。然后用指令数据集通过有监督的方式对前面训练得到的LLM进行指令调优,得到SFT模型。到这一步得到的SFT模型已经能实现和人类很好的对齐。 - RLHF:为了实现更好的对齐,可以继续用强化学习训练SFT模型。收集一组真实的指令集合,用SFT模型对每条指令生成回复,基于标注人员对回复按照多个指标进行人类偏好排序。用排序结果训练一个符合人类偏好的打分模型(Reward Model,RM)。最后,使用PPO算法用RM的打分优化SFT模型。
融合多模态
为了进一步让LLM获得图像理解能力,需要在LLM中融合多模态。一种做法是利用预训练的大型语言模型以及视觉编码器来构建多模态的统一模型。文章来源地址https://www.toymoban.com/news/detail-609346.html
到了这里,关于基础语言模型LLaMA的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!