知识铺垫
bean的生命周期
这里简单过一下
class ->无参构造 ->普通对象 ->依赖注入(对加了autowire等的属性赋值) ->初始化前->初始化 ->初始化后(aop) ->放入单例池的map(一级缓存) ->bean对象
这里提一点单例bean单例bean 其实就是用map<beanName,Bean对象>创建的,多例bean就不用map
循环依赖
现在有A类和B类,A持有B的引用,B持有A的引用,这就是循环依赖。如果没有Spring,我们又是如何去解决循环依赖呢。注意autowire的内部属性required默认为ture代表这个对象一定要有,不能给他设为null,所有在依赖注入的时候他就一定要有B对象,而B呢一定要有A对象
自己调用自己也算是循环依赖
@Test public void testCircle() throws Exception { TestA a = new TestA(); TestB b = new TestB(); b.setTestA(a); a.setTestB(b); }
spring解决循环依赖的原理
spring解决循环依赖也是如此,首先暴露一个未初始化的实例TestA放到缓存中,创建TestB的实例时,获取的是TestA的未初始化对象,TestB创建完成以后,将TestA进行初始化,由于TestB中TestA的引用和TestA是一样的,TestB中的属性也是完全的初始化的
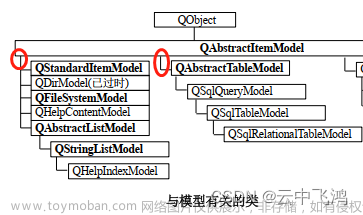
三级缓存
DefaultSingletonBeanRegistry中存在三个Map,用作三级缓存。
一级缓存:singletonObjects ,用于保存BeanName与创建bean实例。(存放最终的bean)
二级缓存:earlySingletonObjects ,用于BeanName与创建bean实例,与singletonObjects 不同的是earlySingletonObjects 中存放的bean是一个未初始化的bean。(下文有讲解)
三级缓存:singletonFactories ,用于存放BeanName与bean工厂。打破循环
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
解决循环依赖就是要打破循环
出现循环依赖了就要提前进行aop
首先我们放在spring容器中的bean是单例的也就是唯一的,当我们出现循环依赖的时候,不如说a b两个类进行了互相调用还交给了spring管理,那么在生程a的时候 回去spring容器中去找b,而此时发现b 还没有创建(此时呢a就被放到了第二级缓存中,属性还没注入呢,就先拿来用了),那么就开始创建b (此时呢 a, 和b只是个普通对象,还没生产bean对象)那么创建b的时候呢,先去singletonObjects 这个map里去找,发现没有(当然创建a的时候们也会先去这去找),在判断a是否在创建,发现a在创建,就去第二级缓存中找,找到了这个a的提前使用的普通对象,就把他那拿到手,为什么这时候不能把他给bean对象呢?按照生命周期应该是这时候成为bean的呀,是因为我们生成的是单例bean 而如果他又aop操作的时候就又会生成代理对象给spring,那这样就不是单例了呀,那么这时候就把aop操作提前,再交给spring。而以上说的这个aop是怎么提前的呢,就是第三级缓存来判断生成额。第三集缓存主要是一个lamada表达式
在这里呢我理解的spring解决循环依赖,其实就是再bean的生命周期时,提前去用生成的这个生成的普通对象,然后最后依赖注入属性值,生成bean对象(其实两级缓存就可以了)
第二级缓存的作用,就是存储那些提前给别人去用的单例bean
三层缓存的关键不是保存前期的bean对象,而是打破循环,其实这个第三级缓存呢就是去打破这个循环的,比如说我们在一个依赖循环中需要一个a,我们在一二级缓存中找不到他的任何bean啊,早期bean啊,这时候我们可以认为这个第三级缓存就是提供这个a的
如果真的找到第三级缓存了,那么他回去判断你要不要aop如果不要aop 我原封不动的把你返回,如果要我返回你的代理对象,然后再放到二级缓存去
必须要第三级缓存判断aop,而且进入第三级缓存没有附加的条件去判断近不近,只要从第二级找不着,就进入三级缓存

如何去判断某个bean有没有提前进行aop这样你初始化后就不会了
、

这两个图中的字段
解决不了的依赖注入


这样的循环解决不了,这是在实例化的时候就出现了循环依赖,连对象都创建不了,咋办不行呗
他这个构造方法的过,你构造a的时候需要b,而你构造b的时候需要a。加个空参构造是可以的。
用@lazy 能解决吗
 文章来源:https://www.toymoban.com/news/detail-609518.html
文章来源:https://www.toymoban.com/news/detail-609518.html
加了lazy,spring会直接给生成一个代理对象,跟aop没关系文章来源地址https://www.toymoban.com/news/detail-609518.html
至此结束,关于lazy如何生成代理对象,肥春本章不做讲解
到了这里,关于spring 的循环依赖以及spring为什么要用三级缓存解决循环依赖的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!