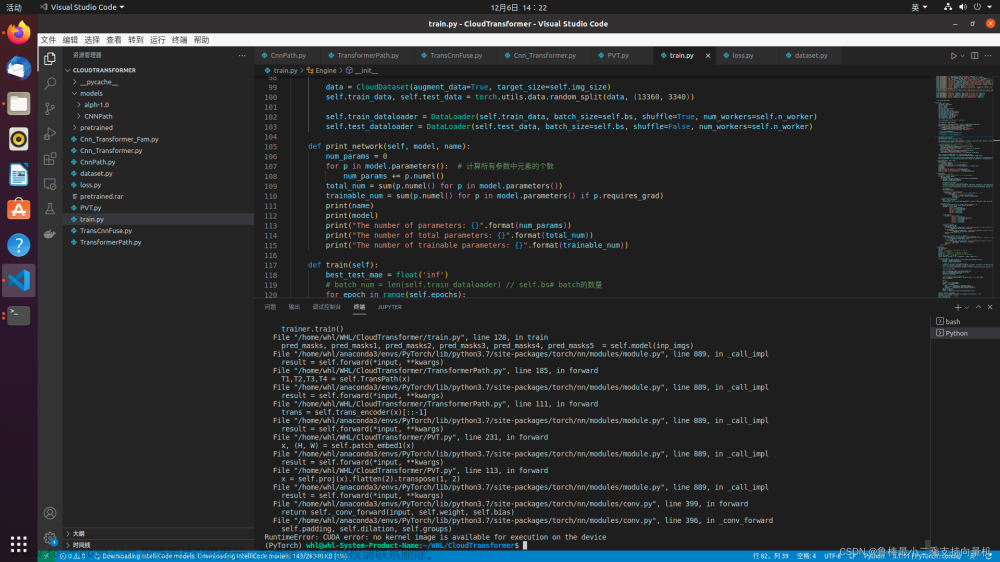
明明跑了一段时间?跑过一次完整的?怎么就出现这个报错呢?代码也未改动?而这就是现实!文章来源地址https://www.toymoban.com/news/detail-609525.html
显存不足?
- 观察显卡使用情况,多人共用同一服务器,项目各自运行,会抢占显存,进而报错!
- 多个项目运行,占用增加,导致内存用完报错,还是很真实的!
- 文件是否设置了CUDA_VISIBLE_DEVICES?
- 只有一张卡的话,CUDA_VISIBLE_DEVICES对应编号为0。
- 如果多张显卡的话,不妨换张卡跑!Linux-ubuntu系统查看显卡型号、显卡信息详解、显卡天梯图
windows10怎么查看gpu显卡使用情况 - 位置参考:CUDA_VISIBLE_DEVICES设置要在模型加载到GPU上之前!
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "2"
import torchPytorch版本?
- 未见明显改善。
- cudatoolkit降级到10.1版可能可以解决这个问题。尝试使用cudatoolkit 10.1重新安装pytorch。
conda install pytorch torchvision cudatoolkit=10.1编程设置?
# True:每次返回的卷积算法将是确定的,即默认算法。
torch.backends.cudnn.deterministic = True
# 程序在开始时花额外时间,为整个网络的每个卷积层搜索最适合它的卷积实现算法
# 实现网络的加速。
torch.backends.cudnn.benchmark = True- torch.backends.cudnn.benchmark = True
- torch.backends.cudnn.benchmark = False
- 建议优先尝试!True or False
文章来源:https://www.toymoban.com/news/detail-609525.html
到了这里,关于【Pytorch报错】RuntimeError:cuDNN error:CUDNN_STATUS_INTERNAL_ERROR 高效理解记录及解决!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!