摘要
英创嵌入式主板,如ESM7000系列、ESM8000系列等,均可配置标准的PCIE×1高速接口。连接NVMe模块作高速大容量数据存储、连接多通道高速网络接口模块都是PCIE接口的典型应用。此外,对于工控领域中的高速数据采集,还可采用FPGA的PCIE IP核实现PCIE EP端点,与英创嵌入式主板构成高效低成本的应用方案。本文简要介绍方案硬件配置,以及PCIE在Linux平台上的驱动程序实现。
硬件设计要点
Xilinx公司为它的FPGA设计有多种PCIE EP端点的IP核,针对本文的应用需求,选择DMA/Bridge Subsystem for PCI Express v4.1(简称PCIE/XDMA)。PCIE/XDMA在硬件上把PCIE接口转换为AXI-Stream高速并行接口(简称AXIS),工控前端逻辑只需把采集数据转换成AXI-Stream格式提供给AXIS通道。IP核会采用PCIE总线的DMA机制,把AXIS通道数据按数据块的形式直接传送至Linux的内存中,这样在Linux的应用程序就可直接处理采集数据了。Xilinx Artix 7系的低成本芯片XC7A35T、XC7A50T均可容纳PCIE/XDMA IP核,这样可保证应用方案的成本处于合理的范围。

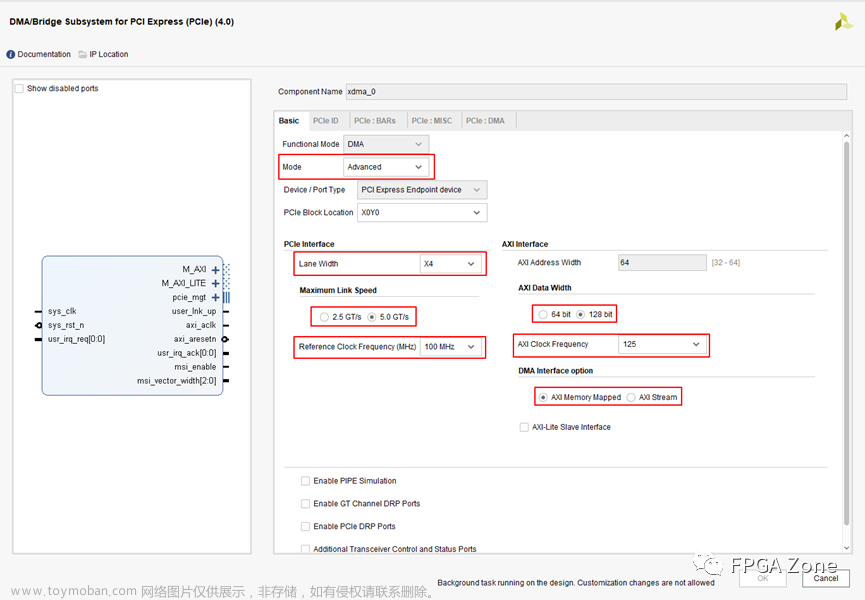
图1中的实例xdma_0是Xilinx公司的PCIE/DMA IP模块,作为PCIE端点设备(PCIE Endpoint Device)。Dtaker1_5_0是应用相关的前端逻辑。对PCIE的主要配置如下图所示:

上述配置定义的AXIS总线为64-bit数据宽度、总线时钟62.5MHz(ACLK)。
AXIS总线典型的握手时序如图3所示,一个数据传输周期最快需要3个ACLK,T3上升沿为数据锁存时刻:

若前端逻辑每4个ACLK产生一个dword数据,则对应的数据速率就是125MB/s。

基于XC7A50T的PCIE/DMA IP可支持最多4路DMA通道,分别为2路发送(H2C通道)和2路接收(C2H通道),加上用户前端逻辑中断,共有至少5个中断源。采用PCIE的MSI中断机制是解决多中断源的最好方式,所以配置8个中断矢量,实际使用5个。
DMA Engine驱动
目前Xilinx公司为其IP核DMA/Bridge Subsystem for PCI Express v4.1,仅提供基于x86体系的驱动,而没有在Linux DMA Engine架构上做工作。而事实上,DMA Engine架构已成为ARM嵌入式Linux平台的DMA应用的事实标准(de facto),为此本方案首先构建了标准的DMA Engine架构驱动程序,包括通用DMA Controller驱动和面向应用的DMA Client驱动,应用程序通过标准的字符型设备节点,操作DMA Client驱动,从而实现所需的数据采集。图5是从软件开发角度来看的总体功能框图。

DMA Engine架构为不同的DMA模式提供不同的API函数,其中最主要的是单次DMA和周期DMA两种,其API函数分别为:
struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_data_direction direction,
unsigned long flags);
struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_data_direction direction);DMA Controller驱动要求DMA支持Scatter-gather结构的非连续数据Buffer,但在本方案的应用中,对单次DMA情形,采用单个Buffer是最常见的应用方式,这时可采用DMAEngine的简化函数:
struct dma_async_tx_descriptor *dmaengine_prep_slave_singl(
struct dma_chan *chan, dma_addr_t buf, size_t len,
enum dma_data_direction direction, unsigned long flags);Cyclic DMA模式,是把多个DMA Buffer通过其描述符(dma descriptor)表连接成环状,当一个buffer的DMA传送结束后,驱动程序的中断线程将自动启动面向下一个描述符的DMA Buffer。由DMA descriptor表描述的逻辑流程如图2所示:

本方案的DMA Controller驱动实现了上述两种DMA传输方式,即单次DMA传输和周期DMA传输。DMA Controller驱动本质上讲,是一种通用的DMA服务器,如何使用DMA的传输功能,实现具体的数据传输任务,则是由DMA Client来决定的。Linux把DMA服务与具体应用分成两个部分,有利于DMA Controller驱动面向不同的应用场景。
DMA Client驱动
DMA Client驱动是一个面向应用的驱动,如图5所示,它需要与User Space的上层应用程序配合运行,来完成所需的数据采集与处理。
单次DMA的操作如下所示。
/* prepare a single buffer dma */
desc = dmaengine_prep_slave_single(dchan, edev->dma_phys,
edev->total_len, DMA_DEV_TO_MEM,
DMA_PREP_INTERRUPT | DMA_CTRL_ACK);
if (!desc) {
dev_err(edev->dev, "dmaengine_prep_slave_single(..) failed\n");
ret = -ENODEV;
goto error_out;
}
/* setup dtaker hardware */
eta750_dtaker_setup(edev);
/* put callback, and submit dma */
desc->callback = dma_callback;
desc->callback_param = edev;
edev->cookie = dmaengine_submit(desc);
ret = dma_submit_error(edev->cookie);
if (ret) {
dev_err(edev->dev, "DMA submit failed %d\n", ret);
goto error_submit;
}
/* init complete, and fire */
reinit_completion(&edev->xdma_chan_complete);
dma_async_issue_pending(dchan);
/* simulate input data */
eta750_dtaker_run(edev);
/* wait dma complete */
count = wait_for_completion_timeout(&edev->xdma_chan_complete, msecs_to_jiffies(DMA_TIMEOUT));
if (count == 0) {
dev_err(edev->dev, "wait_for_completion_timeout timeout\n");
ret = -ETIMEDOUT;
eta750_dtaker_end(edev);
goto error_submit;
}
/* error processing */
eta750_dtaker_error_pro(edev);
/* stop front-end daq unit */
count = eta750_dtaker_end(edev);
/* dump data */
eta750_dtaker_dump_data(edev);
return edev->total_len;
error_submit:
dmaengine_terminate_all(dchan);
error_out:
return ret;只有周期DMA方式才能实现连续数据采集,在DMA Client中采用双DMA Buffer的乒乓结构来实现连续采集,应用程序处理0# Buffer数据时,DMA传输数据至1# Buffer,传输结束时,进行切换,应用程序处理1# Buffer数据,DMA传输新数据至0# Buffer。周期DMA需要指定每个buffer的长度period_len,同时需指定由2个buffer构成的ping-pong buffer的总长度total_len。其DMA流程如下所示。文章来源:https://www.toymoban.com/news/detail-609591.html
/* prepare cyclic buffer dma */
desc = dmaengine_prep_dma_cyclic(dchan, edev->dma_phys, edev->total_len,
edev->period_len, DMA_DEV_TO_MEM, DMA_PREP_INTERRUPT);
if (!desc) {
dev_err(edev->dev, "%s: prep dma cyclic failed!\n", __func__);
ret = -EINVAL;
goto error_out;
}
/* in cyclic mode */
edev->cyclic = true;
/* setup dtaker hardware */
eta750_dtaker_setup(edev);
/* put callback, and submit dma */
desc->callback = dma_callback;
desc->callback_param = edev;
edev->cookie = dmaengine_submit(desc);
ret = dma_submit_error(edev->cookie);
if (ret) {
dev_err(edev->dev, "cyclic dma submit failed %d\n", ret);
goto error_submit;
}
/* init complete, and fire */
reinit_completion(&edev->xdma_chan_complete);
dma_async_issue_pending(dchan);
edev->running = true;
/* simulate input data */
eta750_dtaker_run(edev);
edev->data_seed += ((edev->period_len / sizeof(u16)) * edev->data_incr);
while(!kthread_should_stop()) {
/* wait dma complete */
count = wait_for_completion_timeout(&edev->xdma_chan_complete,
msecs_to_jiffies(DMA_TIMEOUT));
if (count == 0) {
dev_err(edev->dev, "wait_for_completion timeout, transfer %d\n", edev->transfer_count);
ret = -ETIMEDOUT;
break;
}
/* data processing */
eta750_dtaker_error_pro(edev);
edev->transfer_count++;
reinit_completion(&edev->xdma_chan_complete);
/* fill more data */
eta750_dtaker_run(edev);
edev->data_seed += ((edev->period_len / sizeof(u16)) * edev->data_incr);
}
/* stop front-end daq unit */
count = eta750_dtaker_end(edev);
edev->running = false;
error_submit:
dmaengine_terminate_all(dchan);
edev->cyclic = false;
dev_info(edev->dev, "%s: dma stopped, cyclic %d, running %d\n", __func__, edev->cyclic, edev->running);
error_out:
return ret;从上面代码可见,传送过程是一个无限循环,DMA Controller驱动会自动进行ping-pong buffer的切换。并通过回调函数通知上层应用程序,新数据已准备就绪。应用程序可通过命令来终止采集传输过程。文章来源地址https://www.toymoban.com/news/detail-609591.html
到了这里,关于FPGA PCIE接口的Linux DMA Engine驱动的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!