前言
最近在公司实习,给整了个活,像是数学建模一样的数据分析的活,目标是在几个互相有关联的大表中找出满足某条件的那些业务,其中第一步就是把两个表拼起来,就叫它们A和B吧,省略拼表过程中需要的逻辑判断。
串行
两个长为M和N的表,在判断中需要一个M*N级别的判断,也就是N2的复杂度,当M和N都很大时,比如3w,那还是得花点时间的,比如七八分钟。所以得想办法加速。
使用concurrent.futures的线程池
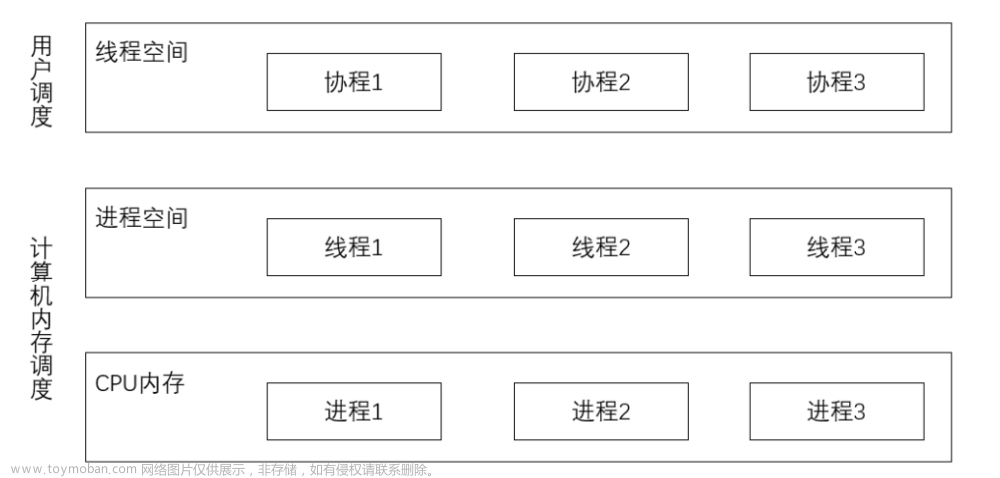
既然是在一个py进程里干的活,那自然就想到能不能多开几个线程,比如12个,反正每个判断是独立的,把一个表尽量平均拆成12份,让每个线程去做那一份的判断,最后再把结果返回给主进程进行拼接。这里我先使用了Python的concurrent.futures的线程池来看看效果。
concurrent.futures 是 Python 的一个模块,它提供了一个高级接口,用于异步执行可调用对象,也可以理解为并发。异步执行可以使用线程(使用 ThreadPoolExecutor)或单独的进程(使用 ProcessPoolExecutor)来执行。两者都实现了相同的接口,由抽象的 Executor 类定义 。
一个大致的使用框架:
import pandas as pd
import concurrent.futures
def sub_process(data: list) -> list:
res = []
# 处理
return res
df = pd.read_csv('large_data.csv')
num_threads = 12
chunk_size = len(df) // num_threads
results = []
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
for i in range(num_threads):
start = i * chunk_size
end = (i + 1) * chunk_size if i < num_threads - 1 else len(df)
data_chunk = df.iloc[start:end]
future = executor.submit(sub_process, data_chunk)
results.append(future)
final_result = []
for f in results:
final_result.extend(f.result())
使用multiprocessing
使用了上面这个后,效果并不好,CPU占用就没超过40%,肯定是那里出现了问题,查了一下可能是GIL锁的问题,它是一个互斥锁(mutex),用于防止多个本地线程同时执行 Python 字节码。这个锁主要是因为 CPython 的内存管理不是线程安全的,所以需要这个锁来保证线程安全。
无奈,只能再尝试其他的,比如multiprocessing,既然不让我的多个线程同时执行,那我开多个进程总行了吧,无非就是多用点内存,多复制几个其他要用到的数据给进程。需要注意的是, 使用这个的话,在循环中启动进程时,没法接收到子进程处理后的结果返回值,所以需要在主进程中创建一个数据结构,让子进程执行完了把结果往里面放,完事儿再让主进程去接收,正好multiprocessing中就有队列的类,可以直接用。推荐进程数和CPU的超线程数一样。试过如果和物理核数一样的话,还是不能拉满CPU,总耗时也比不过设置为线程数。
很喜欢看着CPU被拉满时任务管理器框框被占满的样子。文章来源:https://www.toymoban.com/news/detail-609844.html
from multiprocessing import Process, Queue
def worker(pro_id, data_slice, q):
result = [sum(data_slice)] * pro_id
q.put((pro_id, result))
if __name__ == '__main__':
data = list(range(100))
num_worker = 12
slice_size = len(data) // num_worker
q = Queue()
pool = []
for i in range(num_worker):
start = i * slice_size
end = (i + 1) * slice_size if i < num_worker - 1 else len(data)
data_slice = data[start:end]
p = Process(target=worker, args=(i, data_slice, q))
p.start()
pool.append(p)
result_list = []
for _ in range(num_worker):
result_list.append(q.get())
for p in pool:
p.join()
# 如果不在意结果的顺序的话,可以不用排序,队列保存时也可去掉id项。
result_list.sort(key=lambda x: x[0])
final_result = [x[1] for x in result_list]
print(final_result)
没了,主打一个短小精悍,浓缩的就是精华,希望能对你有所帮助
其实如果要并发的任务只是纯计算的话,用上一个方法更加适合。文章来源地址https://www.toymoban.com/news/detail-609844.html
到了这里,关于Python并行处理数据多进程/多线程,榨干你的CPU的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!