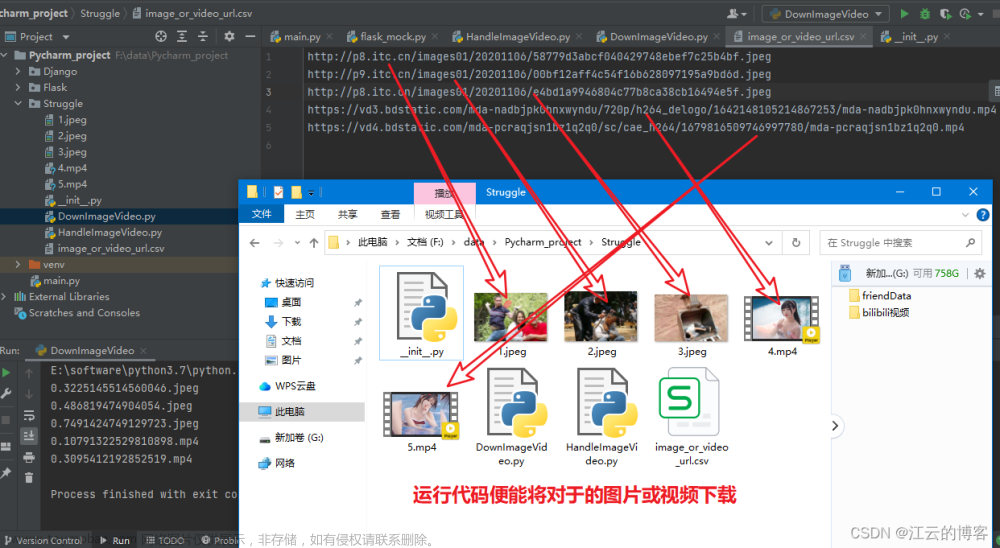
主程序文件 app.js
运行主程序前需要先安装使用到的模块: npm install superagent --save
axios要安装指定版,安装最新版会报错:npm install axios@0.19.2 --save
const {default: axios} = require('axios');
const fs = require('fs');
const superagent = require('superagent');
const charset = require('superagent-charset');
charset(superagent);
const cheerio = require('cheerio');
const express = require('express');
const app = express();
var baseUrl = 'https://www.qqtn.com/'; //目标网站
// 访问地址示例 http://127.0.0.1:8081/index?page=6
app.get('/index', function(req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//解析网址传递的类型
var type = req.query.type;
//解析网址传递的页码
var page = req.query.page;
//当网址没有传值的时候设置默认值
type = type || 'weixin';
page = page || '1';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.buffer(true)
.end(function(err, sres) {
var items = [];
var titelStr = '';
if (err) {
console.log('ERR: ' + err);
res.json({
code: 400,
msg: err,
sets: items
});
return;
}
//使用JQuery风格定义$
var $ = cheerio.load(sres.text);
//遍历标签提取属性值
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function(idx, element) {
var thumbImgSrc = $(element).find('img').attr('src');
var oldtitle = $(element).attr('title');
var title = oldtitle.replace(/\s*/g, ""); //去除字符串内所有的空格
var href = $(element).attr('href');
items.push({
title: title,
href: href,
thumbSrc: thumbImgSrc
});
//标题拼接为html格式的字符串
titelStr = '<li>'+title+'</li>' + titelStr
//调用方法下载图片
downloadFile(thumbImgSrc, title);
});
//发给前端
//res.json({ code: 200, msg: "我是返回给前端的消息", data: items });
//res.end();
//读取html文件并替换内容,再发送给前端显示出来
fs.readFile('./index.html',(err,data)=>{
//报错则抛出错误
if(err) throw err;
//读取出来的内容转为字符
var htmlStr = data.toString();
//把 <li>%</li> 替换为拼接后的字符串
var html = htmlStr.replace('<li>%</li>',titelStr);
res.writeHead(200,{'Content-Type':'text/html'});
res.end(html);
})
});
});
// 下载图片的方法
async function downloadFile(uri, name) {
let dir = "./imgs";
//如果文件夹不存在就创建
if (!fs.existsSync(dir)) {
await fs.mkdirSync(dir)
};
//文件名
let filePath = `${dir}/${name}.png`;
//请求数据
let res = await axios({
url: uri,
responseType: 'stream',
});
//文件流写入磁盘
let ws = fs.createWriteStream(filePath);
res.data.pipe(ws);
res.data.on("close", () => {
ws.close();
});
//console.log(`${name}... ...下载完成`);
};
var server = app.listen(8081, function() {
var host = "127.0.0.1" //server.address().address
var port = server.address().port
console.log(`应用实例,访问地址为 http://${host}:${port}`)
})
index.html 文件
后端爬到数据后,把结果写入index.html再返回给前端显示。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Nodejs爬虫</title>
<style>
li{margin-top: 10px;}
</style>
</head>
<body>
<div style="margin-left: 10%; margin-right: 10%;">
<form action="http://127.0.0.1:8081/index" method="GET">
<br> 页码:<input type="text" name="page">
<input type="submit" value="Submit">
</form>
<hr />
<h3>查询结果:</h3>
<div>
<!-- 使用百分号做占位符,用于nodejs操作替换实际内容 -->
<ul><li>%</li></ul>
</div>
</div>
<script>
</script>
</body>
</html>
前端请求效果图 文章来源:https://www.toymoban.com/news/detail-610056.html
文章来源:https://www.toymoban.com/news/detail-610056.html
后端运行效果图
下载到文件夹的图片 文章来源地址https://www.toymoban.com/news/detail-610056.html
文章来源地址https://www.toymoban.com/news/detail-610056.html
到了这里,关于node.js 爬虫图片下载的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!