目录
🌷1、JVM是什么?
🌷2、JVM的执行流程(能够描述数据区5部分)
🌷3、JVM类加载过程
🌷4、双亲委派机制:描述类加载的过程
问题1:类加载器
问题2:什么是双亲委派模型?
问题3:双亲委派模型的优点
🌷5、垃圾回收机制(重要,针对的是堆)
问题1:判定对象死亡的算法
问题2:垃圾回收的过程?
问题3:垃圾回收算法
问题4:垃圾回收器(7种)
🌷6、强引用、软引用,弱引用、软引用?
🌷1、JVM是什么?
JVM是个虚拟机,Java所有的程序都运行在JVM中;JVM是一个规范。HotSpot是目前使用最广泛的虚拟机,也就是JVM其中的一个实现。
类似于:教育部现在制定了大学生培养的一个标准,这就是一个规范,然后各个大学根据这个规范去制定自己的培养准则,这就是它的一个实现。

🌷2、JVM的执行流程(能够描述数据区5部分)
红色的是内存共享的,黄色的是和线程相关的,都是线程私有的。

编号2:问题:new出来的对象都在堆中,那对象是不是也会溢出?
演示一下OOM异常(OutOfMemory)堆内存占满
分别表示堆的最大内层和起始内存, 设置堆的最大值和启动值都是20M。
Java堆内存的OOM异常是实际应用中最常见的内存溢出情况。当出现Java堆内存溢出时,异常堆栈信息"java.lang.OutOfMemoryError"会进一步提示"Java heap space"。当出现"Java heap space"则很明确的告知我们,OOM发生在堆上,出现了堆内存占满的情况,一般通过
优化堆内存大小的方式解决。
堆溢出:配置-Xmx20m -Xms20m栈溢出:配置-Xss。
编号3:Java虚拟机栈
编号4:本地方法栈(线程私有):工作原理和Java虚拟机栈相同,不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的,记录的是本地方法的调用关系。
编号5:程序计数器(线程私有):记录当前线程的方法执行到哪一行了。
执行引擎:Java字节码到CPU指令的一个转换过程;
本地方法接口:调用不同系统(Windows,Linux)的API。
在《Java虚拟机规范中》把此区域称之为“方法区”,而在 HotSpot 虚拟机的实现中,在 JDK 7 时此区域叫做永久代(PermGen),JDK 8 中叫做元空间(Metaspace)。





🌷3、JVM类加载过程

(1)加载:读取.class文件;
(2)连接
- 验证:验证.class文件是否符合规范;
- 准备:分配内存并设置初始化值:比如此时有这样一行代码:public static int value = 123,它是初始化 value 的 int 值为 0,而非 123。
- 初始化:将符号引用替换为直接引用:将值赋值为真实的值123。
(3)初始化:Java虚拟机开始真正执行类中编写的Java代码,控制权在应用程序。


🌷4、双亲委派机制:描述类加载的过程
观察这个现象:
我们在代码中写的String,默认调用的是java.lang包下的


如果我们自己写了一个String类,放在自己创建的java,lang包下,那么系统该加载哪一个呢?因此就有了双亲委派机制。
问题1:类加载器
- 启动类加载器:加载 JDK 中 lib 目录中 Java 的核心类库,即$JAVA_HOME/lib目录。
- 扩展类加载器。加载 lib/ext 目录下的类。
- 应用程序类加载器:加载我们写的应用程序。
- 自定义类加载器:根据自己的需求定制类加载器。
问题2:什么是双亲委派模型?
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最 终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无 法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载。
以人家已有的为准,没有了才用自己写的包java.lang.String。

问题3:双亲委派模型的优点
- 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。
- 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
破坏双亲委派机制:JDK中只定义接口,但是实现类是在第三方厂商的JAR包中。(简单知道。)
🌷5、垃圾回收机制(重要,针对的是堆)
当main函数中调用完test()方法之后,test对象就无效,这种无效对象就会被回收掉。

问题1:判定对象死亡的算法
(1)引用计数算法(Java中不用)
当开始执行前4行代码的时候,如下图所示:

当执行到test1=null和test2=null的时候。
Java并不采用引用计数法来判断对象是否已"死",而采用"可达性分析"来判断对象是否存活。
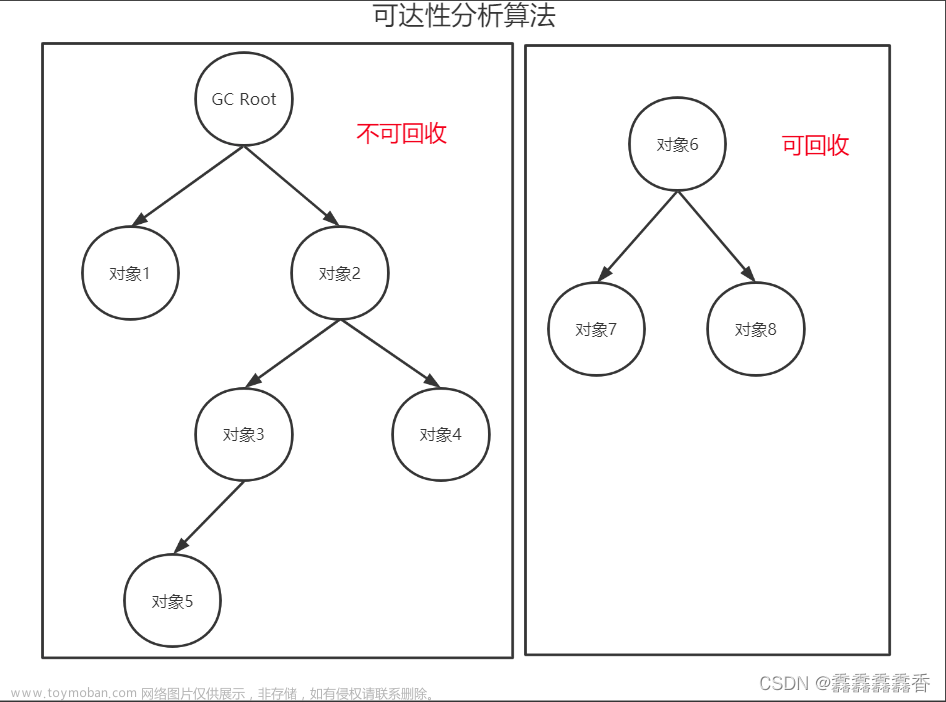
(2)可达性分析算法
此算法的核心思想为 : 通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为"引用链",当一个对象到GC Roots没有任何的引用链相连时(从GC Roots到这个对象不可达)时,证明此对象是不可用的。

问题2:垃圾回收的过程?
整个垃圾回收的过程就是在堆中进行的。一般默认新生代和老年代的比例是1:2,新生代中Eden和S1和S0的比例是8:1:1。(S区表示Survivor区)

上述过程总结:
新生代中98%的对象都是"朝生夕死"的,所以并不需要按照1 : 1的比例来划分内存空间,而是将内存(新生代内存)分为一块较大的Eden空间和两块较小的Survivor(幸存者)空间,每次使用Eden和其中一块Survivor(两个Survivor区域一个称为From区,另一个称为To区域)。当回收时,将Eden和Survivor中还存活的对象一次性复制到另一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。
当Survivor空间不够用时,需要依赖其他内存(老年代)进行分配担保。
HotSpot默认Eden与Survivor的大小比例是8 : 1,也就是说Eden:Survivor From : Survivor To =8:1:1。所以每次新生代可用内存空间为整个新生代容量的90%,而剩下的10%用来存放回收后存活的对象。
HotSpot实现的复制算法流程如下:
1. 当Eden区满的时候,会触发第一次Minor gc,把还活着的对象拷贝到Survivor From区;当
Eden区再次触发Minor gc的时候,会扫描Eden区和From区域,对两个区域进行垃圾回收,经过
这次回收后还存活的对象,则直接复制到To区域,并将Eden和From区域清空。
2. 当后续Eden又发生Minor gc的时候,会对Eden和To区域进行垃圾回收,存活的对象复制到
From区域,并将Eden和To区域清空。
3. 部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数
MaxTenuringThreshold决定,这个参数默认是15),最终如果还是存活,就存入到老年代。补充:
(1)一般创建的对象都会进入新生代;如果新生代放不下,就会放到老年代,同时大对象和经历了N次(一般默认15次)的垃圾回收依然存活下来的对象也会从新生代移动到老年代。
(2)每次进入垃圾回收的时候,程序都会进入暂停状态:STOP THE WORD。
问题1:MinorGC,FullGC,MajorGC的介绍?
(1)Minor GC又称为新生代GC : 指的是发生在新生代的垃圾收集。因为Java对象大多都具备朝生夕灭的特性,因此Minor GC(采用复制算法)非常频繁,一般回收速度也比较快。
(2)Full GC 又称为 老年代GC或者Major GC : 指发生在老年代的垃圾收集。出现了Major GC,经常会伴随至少一次的Minor GC(并非绝对,在Parallel Scavenge收集器中就有直接进行Full GC的策略选择过程)。Major GC的速度一般会比Minor GC慢10倍以上。
问题3:垃圾回收算法
通过上面我们现在可以将死亡对象标记出来了,标记出来之后我们就可以进行垃圾回收操作了。其中,垃圾回收算法是垃圾回收器的指导思想。
(1)标记-清除算法
"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段 : 首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。后续的收集算法都是基于这种思路并对其不足加以改进而已。
问题:碎片化的空间,找不到连续的大空间使用。

(2)复制算法(新生代使用)
"复制"算法是为了解决"标记-清理"的效率问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块内存需要进行垃圾回收时,会将此区域还存活着的对象复制到另一块上面,然后再把已经使用过的内存区域一次清理掉。这样做的好处是每次都是对整个半区进行内存回收,内存分配时也就不需要考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运行高效。
内存分两份,一份是要被回收的,一份是存活的。
问题:只能用一半的内存,空间效率问题。

(3)标记-整理算法:(老年代使用)
复制收集算法在对象存活率较高时会进行比较多的复制操作,效率会变低。因此在老年代一般不能使用复制算法。
针对老年代的特点,提出了一种称之为"标记-整理算法"。标记过程仍与"标记-清除"过程一致,但后续步骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存。在回收过后多了一步整理内存的工作:整理出大片的连续空间;
问题:多了一步操作用来整理内存。

问题4:垃圾回收器(7种)
前期是内存小用串行,后来用并行。目的是为了减少STW(stop-the-world),让程序尽快回到原始的正常状态。
7种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明他们之间可以搭配使用。所处的区域,表示它是属于新生代收集器还是老年代收集器。

(garbage collection):即垃圾收集
(1)Serial收集器:新生代收集器,串行扫描
(2) ParNew收集器:新生代收集器,并行GC,是对于Serial的优化,用多线程的方式扫描内存,提升垃圾回收的效率,减少STW的时间。
(3)Parallel Scavenge收集器:新生代收集器,并行GC;Parallel Scavenge收集器与ParNew收集器的一个重要区别是它具有自适应GC调节策略。一般建议Parallel Old和Parallel Scavenge搭配使用。
(4)Serial Old是Serial收集器的老年代版本,它同样是一个单线程收集器;(5)Parallel Old是Parallel Scavenge收集器的老年代版本,并行GC;
(6)CMS收集器:老年代收集器,并发GC。使用的是三色标记算法。
(7)G1收集器:唯一一款全区域(不区分老年代与新生代)的垃圾回收器。(使用最广泛)
G1(Garbage First)垃圾回收器是用在heap memory很大的情况下,把heap划分为很多很多的region块,然后并行的对其进行垃圾回收。

🌷6、强引用、软引用,弱引用、软引用?
(1)强引用:new的对象就是强引用,会经历正常的GC,如果被判断为死亡,就会被回收;
(2)软引用:当系统内存不够时,或者触发阈值时,软引用对象就会被回收;(软引用一般用在大的内存操作上,比如加载大的图片)
(3)弱引用:每次新生代GC都会回收弱引用;
(4)虚引用:只是在对象被回收的时候收到一个通知而已。

昔之善战者,先为不可胜,以待敌之可胜。不可胜在己,可胜在敌。文章来源:https://www.toymoban.com/news/detail-610371.html
胜,不妄喜;败,不遑馁;胸有激雷而面如平湖者,可拜上将军!文章来源地址https://www.toymoban.com/news/detail-610371.html
到了这里,关于【JVM】JVM执行流程 && JVM类加载 && 垃圾回收机制等的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!