[论文解读]比sam快50倍的通用视觉模型fastsam(Fast Segment Anything) - 知乎MetaAI提出的能够“分割一切”的视觉基础大模型SAM提供了很好的分割效果,为探索视觉大模型提供了一个新的方向。 虽然sam的效果很好,但由于sam的backbone使用了vit,导致推理时显存的占用较多,推理速度偏慢,对…https://zhuanlan.zhihu.com/p/639179724fastsam虽然也叫sam系列,但其实和sam的关系不大,它相当于保存了sam的壳子,把sam里面的组件全换了。

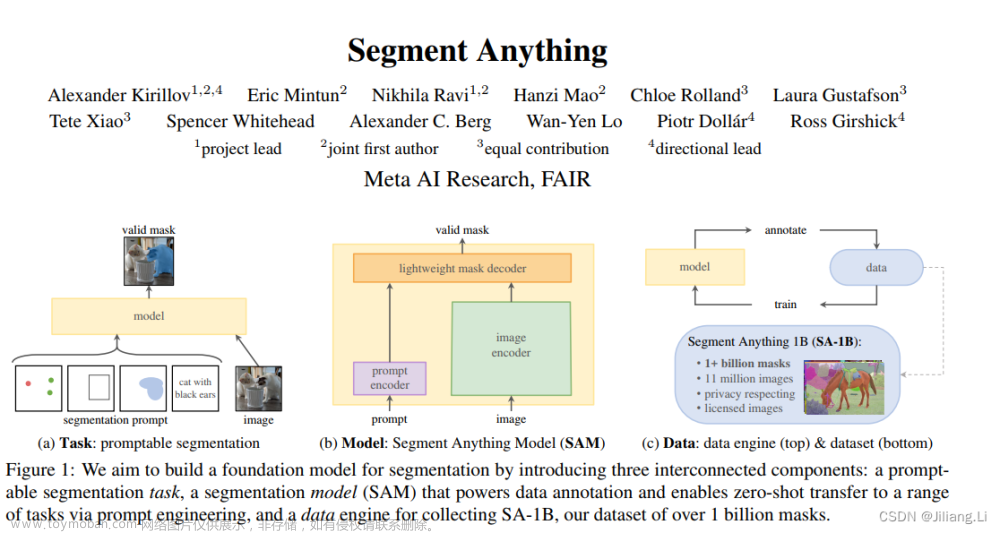
sam是mae提取图像的embeddings,对输入的prompt进行编码,得到tokens,再将image embeddings和prompt tokens输入到mask decoder中解码,解码之后得到两个head,一个输出masks,一个输出iou scores。
fastsam包括两个部分,第一部分是基于yolov8的全实例分割,结果包括检测和分割分支,检测分支输出box和类别cls,分割分支输出k个mask,fastsam中默认是32以及k个mask系数,检测和分割是并行的,fastsam中使用的就是yolov8的segment分支,第二部分是prompt-guided selection,利用prompt挑选出感兴趣的目标,支持point/box/text,point prompt:点prompt用点和示例分割输出的mask进行匹配,和sam一样,利用前景点/背景点作为prompt,如果一个前景点落在多个mask中,可以通过背景点进行过滤,通过使用一组前景/背景点,能够在感兴趣区域选择多个mask,再将这些mask合并为一个mask用于返回,此外利用形态学操作来提高mask合并的性能。box prompt:与实例分割输出的mask的box和输入的box进行iou计算,利用iou得分过滤mask。text prompt:利用clip模型,利用图像编码和文本编码的相似性,提取分数较高的mask,因为引入clip模型,text prompt的运行速度较慢。

总的来说,虽然叫fastsam,其实不过是加了后处理逻辑的yolov8实例分割。至于训练数据只用了SA-1B的2%,数据量是不多,将yolov8的reg_max从16改成26,图像输入改为1024,不同任务使用不同的训练数据在real world data上,说白了就是yolov8在SA-1B数据上训练之后泛化性不错。文章来源:https://www.toymoban.com/news/detail-610701.html
代码:文章来源地址https://www.toymoban.com/news/detail-610701.html
input = Image.open(args.img_path)
input = input.convert("RGB")
model = FastSAM(args.model_path)
- fastsam.model.FastSAM.__call__.predict()->
- overrides:{'task': 'segment', 'data': 'ultralytics/datasets/sa.yaml', 'imgsz': 1024, 'single_cls': False, 'model': '/root/autodl-tmp/e_commerce_sd/weights/FastSAM-x.pt', 'conf': 0.4, 'device': device(type='cpu'), 'retina_masks': True, 'iou': 0.9, 'mode': 'predict', 'save': False}
- self.predictor=FastSaMPredictor(overrides)->DetectionPredictor->BasePredictor
- self.predictor.setup_model(model)->
- self.predictor()-> yolov8中的推理
prompt_process=FastSAMPrompt(image,results,device)->
ann=prompt_process.everything_prompt() 72x1200x1800->
fastsam.prompt.FastSAMPrompt.plot->
- result=self.plot_to_result()->
- self.fast_show_mask_gpu()->到了这里,关于fast segment anything的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!