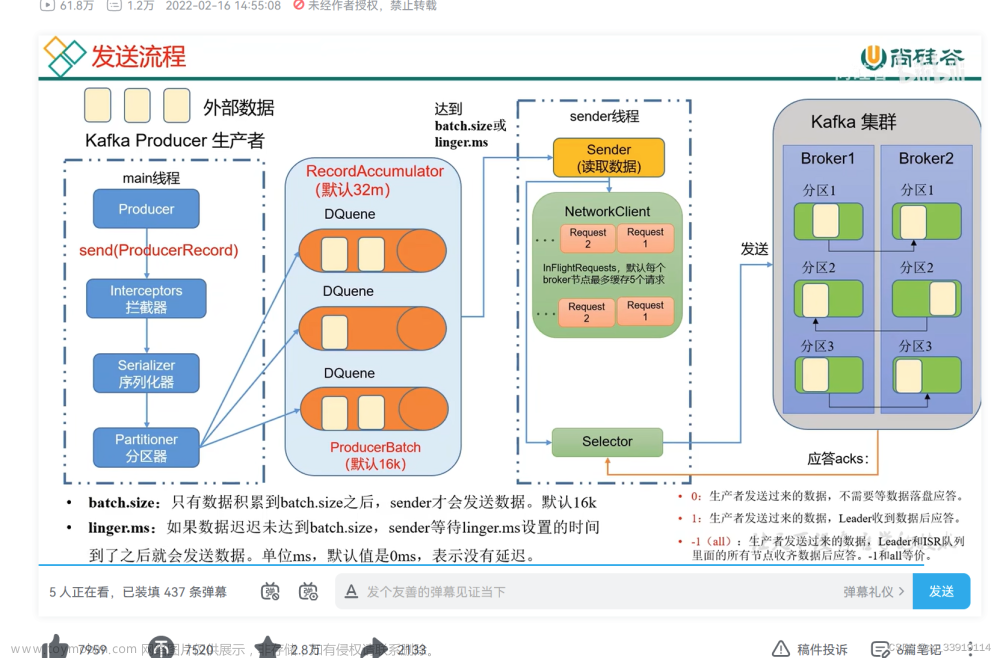
一、Kafka生产者简介
1.1 概述
Kafka是一个分布式流平台,是由LinkedIn开发的一个开源项目。Kafka采用发布-订阅模式,消息的发送者称为“生产者”,消息的接收者称为“消费者”。Kafka以高吞吐量、可靠性和存储容量等优点,成为了大规模实时数据处理的首选。
在Kafka中生产者将消息发布到一个Topic(主题)中,并且可以在多个Partition(分区)之间切分这些消息。每个Partition中的数据都具有顺序,因此能够保证键相同的消息被写入到同一个Partition中。
1.2 Kafka生产者性能的重要性
Kafka生产者性能的优化是非常重要的,因为它直接影响到整个系统的吞吐量和延迟。下面是一些提升Kafka生产者性能的技巧:
1.2.1 批量发送消息
Kafka支持批量发送消息的功能,可以在一个请求中发送多个消息,从而降低网络I/O的延迟和负载。可以通过设置batch.size参数来控制批处理的大小。
1.2.2 指定分区
在发送消息时可以选择指定消息发送到哪个Partition,避免消息乱序问题。可以通过实现Partitioner接口来自定义分区策略。
1.2.3 使用压缩算法
Kafka支持在发送消息时进行压缩,可以选择使用LZ4、Snappy或GZIP等压缩算法。压缩的好处是可以降低网络I/O的数据量,从而减少网络传输延迟和负载。
1.2.4 合理设置ACKs参数
ACKs参数指定了消息写入到多少个副本才认为写入成功。值得注意的是,ACKs参数设置越小,写入的速度就越快,但是数据可靠性也会降低。反之,如果设置得太大,数据可靠性会提高,但写入的速度会变慢。
下面是一个简单的代码示例用于创建KafkaProducer实例
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaProducerExample {
public static void main(String[] args) {
// 定义Kafka生产者配置
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
for (int i = 0; i < 10; i++) {
String msg = "Hello, Kafka!" + i;
ProducerRecord<String, String> record = new ProducerRecord<>("test", msg);
producer.send(record);
}
// 关闭KafkaProducer
producer.close();
}
}
二、Kafka生产者性能调优技巧
2.1 硬件配置优化
2.1.1 CPU、内存、磁盘等硬件参数调整注意事项
- Kafka是依赖CPU和磁盘的高性能消息队列,由于Kafka生产者需要对数据进行序列化和压缩,因此建议使用高频率的CPU。
- 内存大小可以考虑设置为内存总量的30%-50%。
- 磁盘空间大小需要根据应用场景和需求来设置,适当的磁盘缓存可以提高性能。
- 可以选择基于SSD的磁盘。
2.1.2 如何通过负载均衡提高集群吞吐量
- 可以将多个Kafka实例分布在不同的机器上,在数据量大的情况下可以使用多实例的方式,以此提高吞吐量。
- 通过增加Kafka实例和增加Topic的partition数目来实现负载均衡。
2.2 网络配置优化
2.2.1 网卡性能优化
- 对于高负载的Kafka集群,应尽可能选择高带宽的网络设备。
- Linux系统中可以通过更改网卡中的中断处理程序使网络性能得到优化,如采用irqbalance来对网络中断进行优化。
2.2.2 TCP协议配置
- Kafka生产者与Broker之间的数据传输都是基于TCP协议的,因此需要对TCP协议进行配置。
- 可以在Kafka生产者与Broker之间提高TCP缓冲区大小来实现高吞吐量,在Linux系统中可以使用sysctl命令进行修改。
2.3 Kafka生产者代码优化
2.3.1 Producer配置参数设置
- 在Kafka生产者的代码中,可以通过设置Producer的参数来调整性能。
- 通常情况下,batch.size、linger.ms和compression.type是需要关注的参数,它们会直接影响Kafka生产者的性能。
- 设置batch.size较大的值可以减少消息数量,从而减少磁盘I / O负担。而linger.ms設置較大的值則可避免短時間內大量請求導致broker壓力增加。
- 针对不同的应用场景,可以选择不同的compression.type(压缩类型)来使Kafka生产者更加适应和优化。
2.3.2 Producer消息发送策略优化
- 可以通过异步发送消息来提高性能,将回调函数放入Producer产生的新线程中,可以避免等待I/O操作完成的时间。
- 提高可重试次数或超时时间,来避免由于网络波动等情况导致发送失败的情况。
2.4 其他考虑因素
2.4.1 分区数量和Broker个数对性能的影响
- 分区数量和Broker个数,会对Kafka的性能产生不同的影响。
- 在分区数量增加的情况下,可以使Kafka集群整体吞吐量提高,但过多分区数可能会导致每个分区接收的消息量下降。
- 增加broker个数可以提高Kafka集群的可扩展性和容错能力。
2.4.2 ISR(in-sync replicas)配置及影响
- ISR指的是与leader相同数据一致性度量中的follower集合。在Kafka中,消息的发送需要follower确认接收。如果follower超时未接收,则被认为出了Sync,此消息也就无法成为ISR集合的一部分了。采用ISR配置可以提高Kafka生产者向kafka中写入消息的效率,从而提高Kafka的性能。
- 如果Broker中注册的ISR follower数量较少,则代表follower运行不稳定或宕机。需要保证leader的ISR集合中至少包含一个follower,这样才可以保证数据安全和可靠性。
三、Kafka生产者性能调优实战案例
在使用Kafka进行消息传递时需要关注生产者的性能,以确保快速和可靠地将消息发送到Kafka集群
1. 使用异步发送
在使用Kafka生产者时最好使用异步发送,因为这可以使发送操作变得非常快速而不必等待返回确认。以下是一个示例代码片段,演示了如何使用异步发送:
producer.send(new ProducerRecord<String, String>("topicName", message),
new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
e.printStackTrace();
} else {
System.out.printf("The offset of the record we just sent is: %d%n", metadata.offset());
}
}
});
2. 批处理消息
批处理是一种将多个消息作为单一请求进行发送的方法。这样可以减少网络流量和I/O操作,从而提高吞吐量。以下是一个示例代码片段,演示了如何批量发送消息:
ProducerConfig props = new ProducerConfig();
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("acks", "all");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 1000; i++) {
producer.send(new ProducerRecord<String, String>("topicName", Integer.toString(i), Integer.toString(i)));
}
该代码片段中的“batch.size”参数定义了每个批处理请求发送的消息数。 “linger.ms”参数确定如果该批量填满之前发送多长时间。 “buffer.memory”参数确定Kafka生产者可以使用的内存量。 “acks”参数指定是否需要确认。
3. 调整发送缓冲区大小
默认情况下,Kafka生产者使用的发送缓冲区大小为32KB。对于某些消息,尤其是大型消息或大型批次,这可能会导致性能下降。可以通过更改“send.buffer.bytes”参数来调整此值。例如:文章来源:https://www.toymoban.com/news/detail-610960.html
ProducerConfig props = new ProducerConfig();
props.put("send.buffer.bytes", 65536);
Producer<String, String> producer = new KafkaProducer<>(props);
该代码片段中的“send.buffer.bytes”参数定义了生产者发送缓冲区的大小。文章来源地址https://www.toymoban.com/news/detail-610960.html
到了这里,关于Kafka生产者性能调优技巧的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!