今天在看NLP代码的时候,有一段代码没有看懂:
def _regex_match(self, smiles):
tokenized = []
for smi in smiles:
tokens = self.prog.findall(smi)
tokenized.append(tokens)
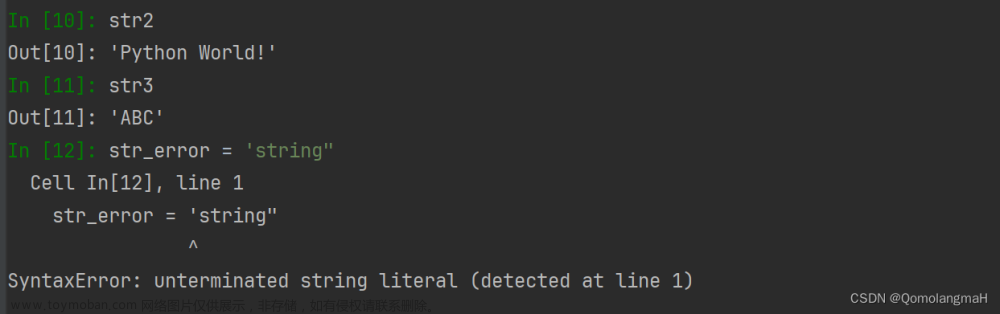
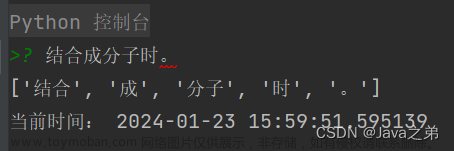
return tokenizedtokens = self._regex_match(sents1)通过正则匹配对第一个句子(sents1)进行分词,得到tokens。
正则匹配分词是将输入的序列按照特定的规则进行分割和标记的过程(其实就是将句子拆分成多个token的过程)。正则表达式是一种用于匹配字符串的表达式,通过定义一系列模式来描述要匹配的字符串的规则。在这段代码中,"_regex_match"方法使用了一个正则表达式引擎(self.prog)来对输入的SMILES序列进行正则匹配的操作。
具体而言,该方法将遍历输入的SMILES序列,并对每个SMILES字符串进行正则匹配操作。匹配的结果是根据预定义的正则表达式模式,提取出符合规则的子字符串作为分词结果。这些分词结果将被存储在一个列表 tokenized = [] 中,并作为方法的返回值。文章来源:https://www.toymoban.com/news/detail-611403.html
通过正则匹配分词,可以将输入的SMILES序列拆分成一组符号和操作符,以便进一步处理和分析分子的结构和属性。文章来源地址https://www.toymoban.com/news/detail-611403.html
到了这里,关于NLP“正则匹配分词“什么意思的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!