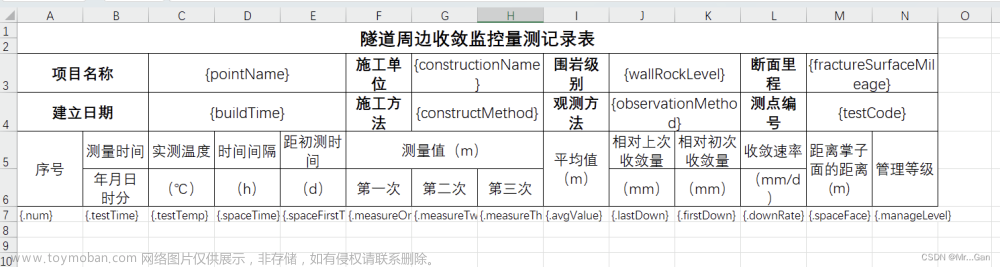
实现多个sheet的excel导出功能
效果展示:
maven依赖
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.17</version>
</dependency>
相关工具类
**此处省略异常处理类
ExcelReportUtil 类
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellRangeAddress;
import java.math.BigDecimal;
import java.util.*;
/**
*
* @ClassName: ExcelReportUtil
* @Description: excel导出工具类
* @version v1.0
*/
public class ExcelReportUtil {
private static Log logger = LogFactory.getLog(ExcelReportUtil.class);
/**
* clone the height, cells and cellRangeAddress to destRow from srcRow
* @param sheet
* @param srcRow
* @param destRow
*/
public static void cloneRow(Sheet sheet, Row srcRow, Row destRow) {
if (sheet == null || srcRow == null || destRow == null)
return;
Set mergedRegions = new HashSet();
destRow.setHeight(srcRow.getHeight());
if (srcRow.getFirstCellNum() >= 0 && srcRow.getLastCellNum() >= 0) {
for (int i = srcRow.getFirstCellNum(), j = srcRow.getLastCellNum(); i <= j; i++) {
Cell srcCell = srcRow.getCell(i);
Cell destCell = destRow.getCell(i);
if (srcCell != null) {
logger.debug("cell is found at col[" + i +
"], will be cloned to the destRow");
if (destCell == null) {
destCell = destRow.createCell(i);
}
cloneCell(srcCell, destCell);
CellRangeAddress mergedRegion = getMergedRegion(sheet, srcRow.getRowNum(),
srcCell.getColumnIndex());
if (mergedRegion != null) {
CellRangeAddress newMergedRegion = new CellRangeAddress(
destRow.getRowNum(),
destRow.getRowNum() + mergedRegion.getLastRow() - mergedRegion.getFirstRow(),
mergedRegion.getFirstColumn(),
mergedRegion.getLastColumn());
if (isNewMergedRegion(newMergedRegion, mergedRegions)) {
logger.debug("CellRangeAddress is found at col[" + i +
"], will be cloned to the destRow");
mergedRegions.add(newMergedRegion);
sheet.addMergedRegion(newMergedRegion);
}
}
}
}
}
}
/**
* get the CellRangeAddress of sheet at [rowNum, colNum] if exists
* @param sheet
* @param rowNum
* @param colNum
* @return null if not exists
*/
public static CellRangeAddress getMergedRegion(Sheet sheet, int rowNum, int colNum) {
for (int i = 0, c = sheet.getNumMergedRegions(); i < c; i++) {
CellRangeAddress merged = sheet.getMergedRegion(i);
if (isRangeContainsCell(merged, rowNum, colNum)) {
return merged;
}
}
return null;
}
/**
* to judge whether the CellRangeAddress includes the cell at [row, col]
* @param range
* @param row
* @param col
* @return
* true if the CellRangeAddress includes the cell at [row, col]
*/
public static boolean isRangeContainsCell(CellRangeAddress range, int row, int col) {
if ((range.getFirstRow() <= row) && (range.getLastRow() >= row)
&& (range.getFirstColumn() <= col)
&& (range.getLastColumn() >= col)) {
return true;
}
return false;
}
/**
* to judge if the CellRangeAddress is not included in mergedRegions,
* using {@link #areRegionsEqual(CellRangeAddress, CellRangeAddress)} to compare
* @param region
* @param mergedRegions
* @return
* true if the CellRangeAddress is not included in mergedRegions
*/
private static boolean isNewMergedRegion(CellRangeAddress region,
Collection mergedRegions) {
for (Iterator iterator = mergedRegions.iterator(); iterator.hasNext();) {
CellRangeAddress cellRangeAddress = (CellRangeAddress) iterator.next();
if (areRegionsEqual(cellRangeAddress, region)) {
return false;
}
}
return true;
}
/**
* compares region1 with region2
* @param region1
* @param region2
* @return
* true if both of them are null or
* their firstColumn, lastColumn, firstRow and lastRow are all the same
*/
public static boolean areRegionsEqual(CellRangeAddress region1,
CellRangeAddress region2) {
if ((region1 == null && region2 != null)
|| (region1 != null && region2 == null)) {
return false;
}
if (region1 == null) {
return true;
}
return (region1.getFirstColumn() == region2.getFirstColumn()
&& region1.getLastColumn() == region2.getLastColumn()
&& region1.getFirstRow() == region2.getFirstRow()
&& region2.getLastRow() == region2.getLastRow());
}
/**
* clone the style and value to destCell from srcCell
* @param srcCell
* @param destCell
*/
public static void cloneCell(Cell srcCell, Cell destCell) {
if (srcCell == null || destCell == null)
return;
destCell.setCellStyle(srcCell.getCellStyle());
switch (srcCell.getCellTypeEnum()) {
case NUMERIC :
destCell.setCellValue(srcCell.getNumericCellValue());
break;
case STRING :
destCell.setCellValue(srcCell.getRichStringCellValue());
break;
case FORMULA :
destCell.setCellFormula(srcCell.getCellFormula());
break;
case ERROR:
destCell.setCellErrorValue(srcCell.getErrorCellValue());
break;
case BOOLEAN:
destCell.setCellValue(srcCell.getBooleanCellValue());
break;
default :
destCell.setCellType(CellType.BLANK);
break;
}
}
/**
* Set a value for the cell.
* Value whose type is {@link Calendar}, {@link Date}, {@link Number}, {@link String}
* is supported directly, otherwise will be processed as string.
* @param cell
* @param value
*/
public static void setCellValue(Cell cell, Object value) {
if (cell == null)
return;
if (value == null) {
cell.setCellType(CellType.BLANK);
} else if (value instanceof Calendar) {
cell.setCellValue((Calendar) value);
//Date格式化日期输出
} else if (value instanceof Date) {
//cell.setCellValue((Date) value);
//cell.setCellValue(BaseUtils.Date2String((Date)value, CommonConstants.FORMAT_Date));
cell.setCellValue(BaseUtils.Date2String((Date)value, "yyyy-MM-dd HH:mm:ss"));
} else if (value instanceof Number) {
setCellValue(cell, (Number) value);
} else if (value instanceof String) {
cell.setCellValue((String) value);
} else {
logger.warn("value type [" + value.getClass().getName() +
"] is not directly supported, will be processed as String");
cell.setCellValue((String) value.toString());
}
}
/**
* set a number value for the cell
* @param cell
* @param value
* @throws XLSReportException
* if the Number can not be unwrapped
*/
private static void setCellValue(Cell cell, Number value) {
double doubleContent = 0.0;
if (value instanceof Byte) {
doubleContent = (Byte) value;
} else if (value instanceof Double) {
doubleContent = (Double) value;
} else if (value instanceof Float) {
doubleContent = (Float) value;
//BigDecimal转换为Double
}else if (value instanceof BigDecimal) {
doubleContent = TypeCaseHelper.convert2Double(value);
} else if (value instanceof Integer) {
float tmp = (Integer) value;
doubleContent = tmp;
} else if (value instanceof Long) {
float tmp = (Long) value;
doubleContent = tmp;
} else if (value instanceof Short) {
short tmp = (Short) value;
doubleContent = tmp;
} else {
throw new XLSReportException("value type [" + value.getClass().getName() +
"] can not be processed as double");
}
cell.setCellValue(doubleContent);
}
/**
* get the string value of a cell
* @param cell
* @return "" if type of the cell is not in
* {CELL_TYPE_NUMERIC, CELL_TYPE_STRING and CELL_TYPE_BOOLEAN}
* @see Cell#CELL_TYPE_BLANK
* @see Cell#CELL_TYPE_NUMERIC
* @see Cell#CELL_TYPE_STRING
* @see Cell#CELL_TYPE_FORMULA
* @see Cell#CELL_TYPE_BOOLEAN
* @see Cell#CELL_TYPE_ERROR
*/
public static String getCellStringValue(Cell cell) {
String cellStringValue = null;
switch (cell.getCellTypeEnum()) {
case NUMERIC:
cellStringValue = cell.getNumericCellValue() + "";
break;
case STRING:
cellStringValue = cell.getStringCellValue();
break;
case BOOLEAN:
cellStringValue = cell.getBooleanCellValue() + "";
break;
default :
logger.warn("can not get the string value of a cell whose type is " + cell.getCellTypeEnum());
cellStringValue = "";
break;
}
return cellStringValue;
}
/**
* remove a comment from sheet
* @param sheet
* @param comment
*/
public static void removeComment(Sheet sheet, Comment comment) {
if (sheet != null && comment != null) {
sheet.getRow(comment.getRow())
.getCell(comment.getColumn())
.removeCellComment();
}
}
}
excel 接口
import org.apache.poi.ss.usermodel.Sheet;
import java.util.Map;
/**
*
* @ClassName: ExcelProcessor
* @Description: 自定义的excel接口
* @author huali
* @version v1.0
*/
public interface ExcelProcessor{
/**
* initialize the CommentProcessor
*/
void init();
boolean isInited();
/**
*
* @Title: process
* @Description: fill the XLS sheet by data
* @param @param sheet
* @param @param dataSource
* @return void
*/
void process(Sheet sheet, Map dataSource);
}
实现类
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.ibatis.ognl.Ognl;
import org.apache.ibatis.ognl.OgnlException;
import org.apache.poi.ss.usermodel.*;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
/**
* Implementation of {@link ExcelProcessor},
* it fills a list in the XLS horizontally.
* Besides 'type', 'expression', 'firstIndex' and 'dataMapping' are added to finish that,
* 1) expression, mandatory, a OGNL expression, is used to get the list from XLS data
* 2) firstIndex, mandatory, the beginning row index of filling list
* 3) dataMapping, mandatory, a Map<Integer, String> value,
* whose key is the cell column index and value is a OGNL expression to
* get the cell value from list element.
* In filling, the list element is transfered by {@link ExcelDataSource},
* and the index of element is put in the transfered data as key 'index'.
* A typical configuration is like this,
* { type : 'I', expression : 'students', dataMapping : { 1 : 'index', 2 : 'name'...} }
*
*/
public class ExcelIteratorNoLastRowProcessor implements ExcelProcessor {
//填充类型
public static String TYPE_ID = "I";
private static Log logger = LogFactory.getLog(ExcelIteratorNoLastRowProcessor.class);
private boolean inited;
//批注
private final Comment comment;
//填充数据的名称
private String expression;
//从第几行开始填充
private int firstIndex;
//填充的数据
private Map<Integer, String> dataMapping;
public ExcelIteratorNoLastRowProcessor(Comment comment) {
this.comment = comment;
}
public String getExpression() {
return expression;
}
public void setExpression(String expression) {
this.expression = expression;
}
public int getFirstIndex() {
return firstIndex;
}
public void setFirstIndex(int firstIndex) {
this.firstIndex = firstIndex;
}
public Map<Integer, String> getDataMapping() {
return dataMapping;
}
public void setDataMapping(Map<Integer, String> dataMapping) {
this.dataMapping = dataMapping;
}
@Override
public void init() {
try {
Map<String, Object> classMap = new HashMap<String, Object>();
classMap.put("dataMapping", Map.class);
Map<String, Object> cfg = JSON.parseObject(this.comment.getString().toString(),Map.class);
Object expresionCfg = cfg.get("expression");
Object firstIndexCfg = cfg.get("firstIndex");
Object dataMappingCfg = cfg.get("dataMapping");
if (expresionCfg == null || !(expresionCfg instanceof String)) {
throw new XLSReportCfgException("expresion must be configured and its type must be String");
}
this.expression = (String) expresionCfg;
if (firstIndexCfg == null || !(firstIndexCfg instanceof Integer)) {
throw new XLSReportCfgException("firstIndex must be configured and its type must be Integer");
}
this.firstIndex = (Integer) firstIndexCfg;
if (dataMappingCfg == null || !(dataMappingCfg instanceof Map)) {
throw new XLSReportCfgException("dataMapping must be configured and its type must be Map");
}
this.dataMapping = (Map<Integer, String>) dataMappingCfg;
this.inited = true;
} catch (JSONException e) {
throw new XLSReportCfgException("the comment configuration at [" +
comment.getRow() + "," + comment.getColumn() + "] " + comment.getString().toString() +
" is error", e);
}
}
@Override
public boolean isInited() {
return this.inited;
}
@Override
public void process(Sheet sheet, Map dataSource) {
try {
if (!isInited())
throw new XLSReportException("the CommentProcessor has not inited yet");
//从dataSource中找到填充目标名称
Object content = Ognl.getValue(this.expression, dataSource);
if (content == null) {
content = Collections.EMPTY_LIST;
}
if (!(content instanceof Iterable)) {
content = Arrays.asList(content);
}
int index = 0;
boolean isAddRow = false;
for (Object element : (Iterable) content) {
//clone row
logger.debug("clone the row at index[" + (this.firstIndex + index + 1) + "] to the new row at index[" + (this.firstIndex + index) + "]");
ExcelReportUtil.cloneRow(sheet, sheet.getRow(this.firstIndex + index + 1), sheet.createRow(this.firstIndex + index));
//获取填充行
Row aimedRow = sheet.getRow(this.firstIndex + index);
//fill data
for (Integer key : this.dataMapping.keySet()) {
int cellIndex = key;
//获取第一行的数据
Map rowDS = new ExcelDataSource(element).getData();
rowDS.put("index", index);
Cell aimedCell = aimedRow.getCell(cellIndex);
if (aimedCell == null)
aimedCell = aimedRow.createCell(cellIndex);
//找到列对应的数据
Object value = Ognl.getValue(this.dataMapping.get(key), rowDS);
//样式
if(Boolean.parseBoolean(rowDS.get("isBolded") == null ? "":rowDS.get("isBolded").toString())){
Workbook workbook = sheet.getWorkbook();
CellStyle cellStyle = workbook.createCellStyle();
Font font = workbook.createFont();
//font.setBoldweight(Font.BOLDWEIGHT_BOLD);
font.setBold(true);
cellStyle.setFont(font);
aimedCell.setCellStyle(cellStyle);
}
logger.debug("set the value of cell[" + (this.firstIndex + index) + ", " + cellIndex + "] to " + value);
//给列填值
ExcelReportUtil.setCellValue(aimedCell, value);
}
index++;
}
//remove comment
ExcelReportUtil.removeComment(sheet, this.comment);
} catch (OgnlException e) {
throw new XLSReportException("extracting data error while using OGNL expression[" +
this.expression + "] with root object : " + dataSource);
}
}
}
excel填充数据处理类
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.beans.BeanInfo;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
/**
* Implementation of XLSReportDataSource, which is constructed by a original bean.
* The original bean will be processed as following,
* 1. Collections.emptyMap() if it is null
* 2. used directly if its type is Map
* 3. otherwise it will be transformed to Map, {@link #transformPropertiesToMap(Object)}
*/
public class ExcelDataSource {
private static Log logger = LogFactory.getLog(ExcelDataSource.class);
/**
* the original bean
*/
private Object dataSource;
public ExcelDataSource(Object dataSource) {
this.dataSource = dataSource;
}
public Map getData() {
Map ds = null;
if (this.dataSource == null) {
ds = Collections.emptyMap();
} else if (this.dataSource instanceof Map) {
ds = (Map) this.dataSource;
} else {
logger.debug("the type of dataSource is [" + dataSource.getClass() +
"], will be transformed to Map");
ds = transformPropertiesToMap(this.dataSource);
}
return ds;
}
/**
* Used locally to transform a bean to Map.
* The property names are transformed to the keys,
* theirs values are transformed to the value of the corresponding key.
* Besides, the property named 'class' is excluded.
* @param bean
* @return
*/
private Map transformPropertiesToMap(Object bean) {
Map properties = new HashMap();
BeanInfo beanInfo;
try {
beanInfo = Introspector.getBeanInfo(bean.getClass());
PropertyDescriptor[] pds = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor pd : pds) {
if (!"class".equals(pd.getName())) {
properties.put(pd.getName(), pd.getReadMethod().invoke(bean));
}
}
} catch (Exception e) {
throw new XLSReportException(e);
}
return properties;
}
}
excel填充处理类
import com.alibaba.fastjson.JSON;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.poi.ss.usermodel.*;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*
* @ClassName: ExcelReportFiller
* @Description: 读取模板数据处理
* @version v1.0
*/
public class ExcelReportFiller {
private static final Log logger = LogFactory.getLog(ExcelReportFiller.class);
public void fill(Workbook template, Map dataSource) {
int sheetCount = template.getNumberOfSheets();
for (int i = 0; i < sheetCount; i++) {
logger.debug("scan the sheet at index[" + i + "]");
fillSheet(template.getSheetAt(i), dataSource);
}
}
public void fillSheetName(String sheetName, Workbook template,
Map dataSource) {
logger.debug("scan the sheet at [" + sheetName + "]");
fillSheet(template.getSheet(sheetName), dataSource);
}
/**
* fill the XLS sheet by data
* @param sheet 模板template
* @param dataSource
*/
private void fillSheet(Sheet sheet, Map dataSource) {
int rowCount = sheet.getLastRowNum();
for (int i = 0; i <= rowCount; i++) {
Row row = sheet.getRow(i);
if (row != null) {
int cellCount = row.getLastCellNum();
for (int j = 0; j <= cellCount; j++) {
Cell cell = row.getCell(j);
if (cell != null ) {
Comment comment = cell.getCellComment();
if (comment != null) {
logger.debug("comment is found at [" + i + ", " + j + "]");
ExcelProcessor processor = ExcelProcessorFactory.getCommentProcessor(comment);
processor.process(sheet, dataSource);
//refresh rowCount
rowCount = sheet.getLastRowNum();
}
}
}
}
}
}
}
excel模板处理
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.ss.usermodel.WorkbookFactory;
import javax.servlet.http.HttpServletRequest;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
/**
*
* @ClassName: ExcelReportTemplate
* @Description: 通过模板创建流
* @version v1.0
*/
public class ExcelReportTemplate {
private static final Log logger = LogFactory.getLog(ExcelReportTemplate.class);
private final String path;
private ClassLoader classLoader;
/**
*
* @param path
*/
public ExcelReportTemplate(String path) {
this(path, (ClassLoader) null);
}
/**
*
* @param path
* @param classLoader
*/
public ExcelReportTemplate(String path, ClassLoader classLoader) {
if (path == null) {
throw new IllegalArgumentException("Path must not be null");
}
this.path = path;
if (classLoader == null) {
try {
classLoader = Thread.currentThread().getContextClassLoader();
} catch (Throwable ex) {
logger.debug("Cannot access thread context ClassLoader - falling back to system class loader", ex);
classLoader = ExcelReportTemplate.class.getClassLoader();
}
}
this.classLoader = classLoader;
}
public Workbook getTemplate() throws IOException, InvalidFormatException {
InputStream is =new FileInputStream(this.path);
if (is == null) {
throw new FileNotFoundException(
"class path resource [" + this.path + "] cannot be opened because it does not exist");
}
//return new HSSFWorkbook(is);
Workbook workbook = WorkbookFactory.create(is);
if(is != null){
is.close();
}
return workbook;
}
public Workbook getTemplate(HttpServletRequest resquest) throws IOException, InvalidFormatException {
InputStream is = this.classLoader.getResourceAsStream(this.path);
if (is == null) {
throw new FileNotFoundException(
"class path resource [" + this.path + "] cannot be opened because it does not exist");
}
Workbook workbook = WorkbookFactory.create(is);
if(is != null){
is.close();
}
return workbook;
}
}
实现关键代码展示
通过模板实现导出功能
try {
os = new FileOutputStream(excelPth);
ExcelReportCreator.createXLS(new ExcelReportTemplate(excelTempletPath),
new ExcelDataSource(jsonMap),
new ExcelReportFiller(),
os);
excelFilePathName = ftpPath + fileModel.getRealFileName();
} catch (Exception e) {
log.error("导出excel文件出错" + " excel文件路径=" + excelPth + " 模板路径=" + excelTempletPath, e);
log.error("excel内容 " + jsonMap);
throw e;
} finally {
if (os != null) {
os.close();
}
}
ExcelReportCreator 中的代码文章来源:https://www.toymoban.com/news/detail-612401.html
/**
*
* @param dataSource
* @param filler
* @param os
* @throws IOException
* @throws InvalidFormatException
*/
public static void createXLS(ExcelReportTemplate template,
ExcelDataSource dataSource, ExcelReportFiller filler,
OutputStream os) throws IOException, InvalidFormatException {
Workbook workbook = template.getTemplate();
filler.fill(workbook, dataSource.getData());
workbook.write(os);
}
导入数据案例展示
excel模板批注案例
每个sheet页都需要写批注,通过批注中的expression对应的值来判断是哪个sheet页的数据,从而进行填充。dataMapping中的key值指的是列序号,value值指的是填充的字段名称,通过名称找对应的数据。 文章来源地址https://www.toymoban.com/news/detail-612401.html
文章来源地址https://www.toymoban.com/news/detail-612401.html
到了这里,关于如何使用Java 实现excel模板导出---多sheet导出?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!