有小伙伴问了怎么将 pdf文件转图片的问题,我百度了一波儿,搞了以下python代码给他封装成exe工具了。
中途打包踩了个坑,python进程池的问题,本地运行没啥问题,打包好的exe文件双击就会使电脑内存爆破卡死,重新开机才好。
准备工作:
- 安装PyMuPDF 直接 pip install PyMuPDF 即可
- 在代码当前路径创建一个名为pdf_dir的文件夹,用于存放要转换的pdf 文件
以下是代码实现,支持批量转换,可以放多个pdf文件
# -*- coding: UTF-8 -*-
import multiprocessing
from multiprocessing import Pool
# 安装fitz需要安装PyMuPDF才能使用
import fitz
import os
import time
tmp = 'pdf_dir' #pdf路径
export_file = "导出文件"
os.makedirs(export_file, exist_ok=True)
pdf_dir = [i for i in os.listdir(tmp) if os.path.splitext(i)[-1] == ".pdf"]
def pdf_to_jpg(name):
# 拼接pdf的文件路径
pwd_name = os.path.join(tmp, name)
print(pwd_name)
doc = fitz.open(pwd_name)
print(1111)
# 将文件名同我们的保存路径拼接起来(保存图片的文件夹)
dir_name = os.path.splitext(name)[0]
pdf_name = os.path.join(export_file, dir_name)
# print(pdf_name)
temp = 0
os.makedirs(pdf_name, exist_ok=True)
for pg in range(doc.pageCount):
page = doc[pg]
temp += 1
rotate = int(0)
# 每个尺寸的缩放系数为2,这将为我们生成分辨率提高四倍的图像。
zoom_x = 2.0
zoom_y = 2.0
trans = fitz.Matrix(zoom_x, zoom_y).preRotate(rotate)
pm = page.getPixmap(matrix=trans, alpha=False)
pic_name = '{}.png'.format(temp)
# 拼接生成pdf的文件路径
pic_pwd = os.path.join(pdf_name, pic_name)
print(pic_pwd)
pm.writePNG(pic_pwd)
def main():
pool = Pool(10)
for i in pdf_dir:
res = pool.apply_async(pdf_to_jpg, (i,))
pool.close()
pool.join()
if __name__ == '__main__':
# 如果要打包成exe供别人使用,要加上下面这行,不然会爆破电脑内存,导致电脑卡死
multiprocessing.freeze_support()
st = time.time()
main()
end_time = time.time()
print('总用时:%s'%(end_time-st))
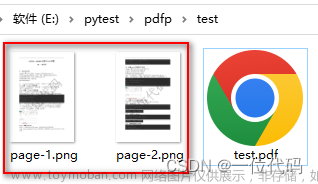
比如我们放了一个pytorch.pdf的文件,直接运行代码 文章来源:https://www.toymoban.com/news/detail-612969.html
文章来源:https://www.toymoban.com/news/detail-612969.html
直接就成功了 文章来源地址https://www.toymoban.com/news/detail-612969.html
文章来源地址https://www.toymoban.com/news/detail-612969.html
到了这里,关于python 将pdf文件转图片的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


](https://imgs.yssmx.com/Uploads/2024/01/803807-1.png)





