生成式模型与判别式模型
生成式模型,又称概率模型,是指通过学习数据的分布来建立模型P(y|x),然后利用该模型来生成新的数据。生成式模型的典型代表是朴素贝叶斯模型,该模型通过学习数据的分布来建立概率模型,然后利用该模型来生成新的数据。
判别式模型,又称非概率模型,是指通过学习输入和输出之间的映射关系来建立模型y=f(x),然后利用该模型来预测新的输出。判别式模型的典型代表是支持向量机模型,该模型通过学习输入和输出之间的映射关系来建立分类模型,然后利用该模型来预测新的分类结果。文章来源:https://www.toymoban.com/news/detail-613042.html
- 常见生成式模型:决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型;
- 常见判别式模型:感知机、支持向量机、K临近、Adaboost、K均值、潜在语义分析、神经网络;
- 逻辑回归既可以看做是生成式也可以看做是判别式。
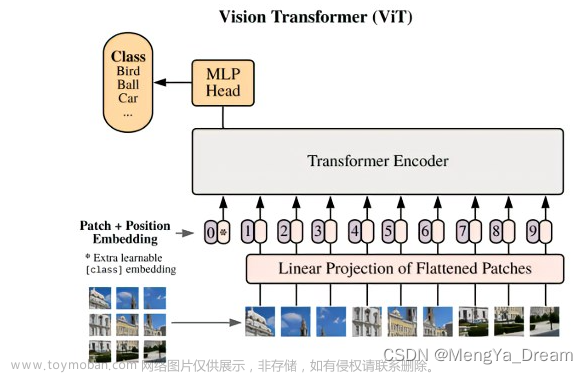
结论:vit在中小型数据集上效果不佳,在大型数据集上进行预训练效果较好。文章来源地址https://www.toymoban.com/news/detail-613042.html
英文积累
de-facto standard 事实上的标准
in conjunction with 与...一起(协力)
unprecedented 无前例的(崭新的)
scaling 可扩展性
inductive biases 归纳偏置(相当于先验知识,卷积神经网络中有两个先验知识即假设,第一个是locality(局部性):CNN以滑动窗口形式进行卷积,因此假设图片上相邻的区域会有相邻的特征; 另外一个归纳偏置是“平移等变性”:translation equivariance,用公式表示为f(g(x))=g(f(x)),可以理解f为卷积操作,g为平移操作,即假设无论先做卷积还是先做平移操作,最后的结果是一样的。卷积核就像一个模板template一样,不论一张图片同样的物体移到哪里,只要是同样的输入进来,遇到同样的卷积核,得到的输出永远是一样的。)
used very sparingly 使用非常少
Hybrid Architecture 混合架构
(前面CNN得到的特征图拉平转为embedding输入注意力的encoder)
spatial size 空间大小
interpolation 插值
manually 手动的
Model Variants 模型变体
inversely proportional 成反比的
到了这里,关于Vision Transformer (ViT)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!