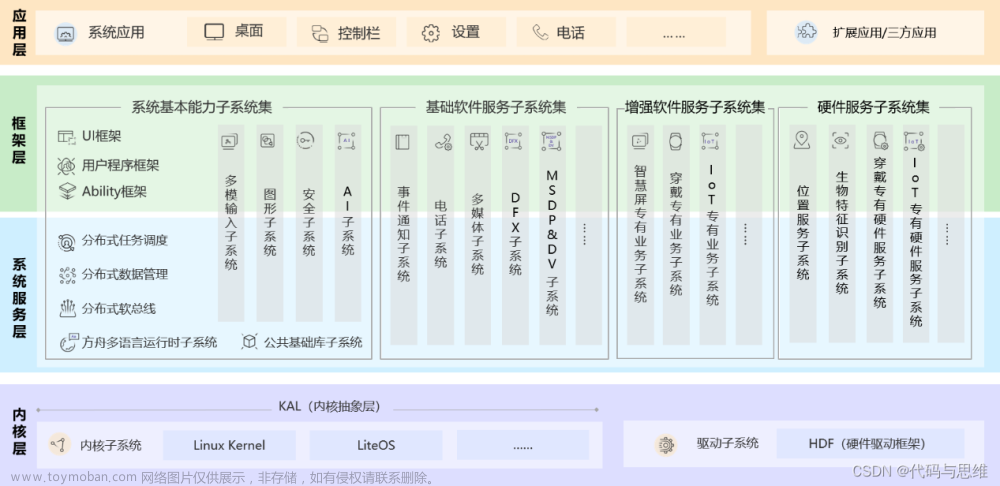
基础知识
struct list_head {
struct list_head *next, *prev;
};初始化:
#define LIST_HEAD_INIT(name) { (name)->next = (name); (name)->prev = (name);}相比于下面这样初始化,前面初始化的好处是,处理链表的时候,不用判空了。太厉害了。
#define LIST_HEAD_INIT(name) { (name)->next = (NULL); (name)->prev = (NULL);}遍历链表:
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)添加节点:(表头开始添加)
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}添加节点:(表尾开始添加)
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}删除节点
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
LIST_HEAD_INIT(entry);
}判空:
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static int list_empty(const struct list_head *head)
{
return (head->next) == head;
}基本功能就这些了文章来源:https://www.toymoban.com/news/detail-613085.html
测试代码
#include <stdio.h>
#include <stdlib.h>
#define _DEBUG_INFO
#ifdef _DEBUG_INFO
#define DEBUG_INFO(format,...) \
printf("%s:%d -- "format"\n",\
__func__,__LINE__,##__VA_ARGS__)
#else
#define DEBUG_INFO(format,...)
#endif
struct list_head {
struct list_head *next, *prev;
};
struct rcu_private_data{
struct list_head list;
};
struct my_list_node{
struct list_head node;
int number;
};
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define LIST_HEAD_INIT(name) { (name)->next = (name); (name)->prev = (name);}
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); })
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static int list_empty(const struct list_head *head)
{
return (head->next) == head;
}
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
LIST_HEAD_INIT(entry);
}
static int list_size(struct rcu_private_data *p){
struct list_head *pos;
struct list_head *head = &p->list;
int count = 0;
if(list_empty(&p->list)){
DEBUG_INFO("list is empty");
return 0;
}
list_for_each(pos,head){count++;}
return count;
}
static int show_list_nodes(struct rcu_private_data *p){
struct list_head *pos;
struct list_head *head = &p->list;
int count = 0;
struct my_list_node *pnode;
if(list_empty(&p->list)){
DEBUG_INFO("list is empty");
return 0;
}
list_for_each(pos,head){
pnode = (struct my_list_node*)container_of(pos,struct my_list_node,node);
DEBUG_INFO("pnode->number = %d",pnode->number);
count++;
}
return count;
}
int main(int argc, char **argv){
int i = 0;
static struct my_list_node * new[6];
struct rcu_private_data *p = (struct rcu_private_data*)malloc(sizeof(struct rcu_private_data));
LIST_HEAD_INIT(&p->list);
DEBUG_INFO("list_empty(&p->list) = %d",list_empty(&p->list));
for(i = 0;i < 3;i++){
new[i] = (struct my_list_node*)malloc(sizeof(struct my_list_node));
LIST_HEAD_INIT(&new[i]->node);
new[i]->number = i;
list_add(&new[i]->node,&p->list);
}
for(i = 3;i < 6;i++){
new[i] = (struct my_list_node*)malloc(sizeof(struct my_list_node));
LIST_HEAD_INIT(&new[i]->node);
new[i]->number = i;
list_add_tail(&new[i]->node,&p->list);
}
//输出链表节点数
DEBUG_INFO("list_size(&p->list) = %d",list_size(p));
//遍历链表
show_list_nodes(p);
//删除指定节点
list_del(&new[3]->node);
DEBUG_INFO("list_size(&p->list) = %d",list_size(p));
//遍历链表
show_list_nodes(p);
for(i = 0;i < 6;i++){list_del(&new[i]->node);}
DEBUG_INFO("list_size(&p->list) = %d",list_size(p));
//遍历链表
show_list_nodes(p);
for(i = 0;i < 6;i++){free(new[i]);}
free(p);
return 0;
}
编译
gcc -o app app.c执行结果:
 文章来源地址https://www.toymoban.com/news/detail-613085.html
文章来源地址https://www.toymoban.com/news/detail-613085.html
小结
到了这里,关于内核链表在用户程序中的移植和使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!