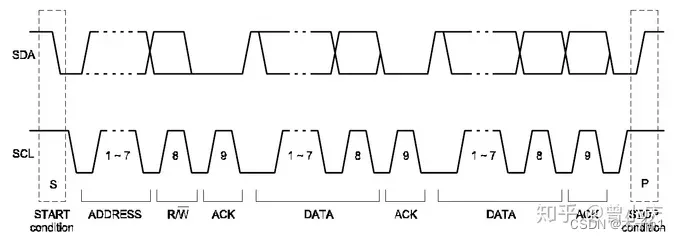
一、SRIO通信方式
使用SRIO进行通信需要大概注意以下几点:
1.初始化DSP的SRIO,主要是对SerDes进行配置,然后是Lane和Speed的配置,最后需要等待FPGA的LinK建立。
2.数据发送,DSP上提供的数据发送方法主要有两种,DirectIO和Message,主要区别为DirectIO需要TX和RX双方知道地址映射关系,而Message是通过Message中mail信息得到数据需要保存的地址,6678上提供了8组LSU来进行DirectIO数据发送,每个LSU有6个寄存器,当5th寄存器写完后,数据会发送出去,第6个寄存器主要用于检测当前的LSU状态。LSU还有16(32)个影子寄存器。
3.SWRITE/NWRITE/NREAD:对DSP来说,初始化完SRIO后,FPGA便可以通过SRIO来发送数据,但是要注意,Designer并不知道什么时候FPGA会发送数据,所以通常会先发送一个DoorBell信息来告知DSP,FPGA要发送数据了,DoorBell可以触发中断,对于NREAD来说,FPGA发送这个命令后,DSP会自动的将请求的数据发送出去,Designer也并不知道数据发送出去,这些都需要DoorBell来支持。
二、Direct I/O 操作
2.1 框架流程
-
direct I/O的LSU模块(加载/存储)是所有传出的direct I/O 包(direct I/O 包)的来源。
-
通过direct I/O包,Rapid I/O包包含了目标设备上数据的存储地址和读取地址。
-
direct I/O 需要RapidIO源设备包含目标设备的本地存储器地址列表。
-
一旦地址列表建立,RapidIO源控制器就利用这些数据来计算目标地址,并将其插入到包header里。RapidIO目标外设从接收到的包header中提取目标地址,并通过DMA把包的payload(包的序列号,大家可以理解为包的指针。注意包一般都会有数据部分(data),header部分和payload部分)传递给存储设备。
CPU要想将存储空间的数据发送到外部处理单元(processing element (PE)),或当CPU想从外部处理单元读取数据时,CPU必须提供RapidIO外设的必要信息,包括:DSP存储地址,目标设备IP,目标设备地址,包的优先级等等。
若要将本地的源设备地址表填满RapidIO包的header的所有区域,需要使用LSU模型,此方法通过一系列的MMR(Memory Mapped Register 存储器映射寄存器),将这些寄存器作为传输描述符进行信息交换,CPU可以通过配置总线寻址这些寄存器。
一共有8个LSU,每个LSU都有自己的7个寄存器,
即LSU_REG0-LSU_REG6,REG0-REG4用来存储控制信息,
REG5、REG6用来存储命令和状态信息。
除了REG6,其它寄存器都是可读可写的,只有REG6有只读和只写两种模式。
配置完LSU_REG5之后,传输就开始。有些必须的例如传输目标,传输源,都不需要人为配置,是硬件配置好的。
下图为每个LSU所拥有的寄存器。

下表为LSU的寄存器的域到RapidIO的包header的映射。

REG0中的内容代表RapidIO的地址高位,映射到RapidIO包header域中就是包要发送的扩展目标地址(只适用于包类型2,5,6)。
REG1中的内容代表RapidIO的地址低位,或者代表配置补偿(Config_offset)具体代表这两者中的哪一个还是要看RapidIO 包的类型。
如果包的类型是2,5,6,REG1中的内容就代表RapidIO的地址低位,映射到RapidIO包header域就是以下功能:这32位目标地址将与REG3中的Byte_COUNT 共同作用创建64位的对齐RapidIO包header地址。
如果包的类型是维护包类型8,REG1中的内容就代表配置补偿,映射到RapidIO包header域就是以下功能:配置补偿与REG3中的Byte_COUN共同作用创建64位的对齐RapidIO包header的配置补偿。REG1的这个域的最低的两位必须是00,因为配置的最小单位是4位。
REG2中的内容代表DSP的地址,也就是DSP读取PE中的信息或往PE中传递信息时,所需的DSP的地址。这个域没有对应的映射到RapidIO包header域。
REG3中的Byte_Count内容代表读写的总字节数,最高可以到达1MB。Byte_Count与RapidIO的目标地址一起,共同在RapidIO包header中创建WRSIZE/RDSIZE和WDPTR。
REG3中的Drbll_val是控制门铃的,只应用于包类型的FType不是10的情况。如果将该位设置为0,就说明在包发送完成之后不需要发送任何门铃信息。如果将该位设置为1,就是需要发送信息,这种情况下,如果不需要响应,就在发送完包的最后一段时发送一个门铃;如果需要响应,就在所有响应收到并没有任何错误时,用Drbll_info位产生一个门铃,如果收到的响应中有错误,门铃将不会产生。

REG4的Interrupt Req位没有到RapidIO包header域的映射。该位是CPU控制的request位用来产生中断的。一般与non-posted 命令共同使用,在请求数据或状态到来的时候提醒CPU。该位是0,代表命令完成后没有请求中断,是1代表命令完成后请求中断。
REG4的SUP_GINT位是用来“镇压”中断的,如果该位是1,命令完成后产生的中断就会被镇压,即CPU收不到该中断,如果是0,则没有镇压的作用。
REG4的Xambs域指明扩展地址的最高位。
REG4的Priority域是用来确定包的优先级的,优先级被三个变量影响:VC,PRIO[1-0],CRF。
RapidIO的CRF域是与priority一同作用来完成优先级定义的。在拥有相同PRIO,VC变量的情况下,CRF=1标志着该包拥有低一级的优先级,CRF=0标志着该包拥有高一级的优先级。
PRIO确定包的优先级,有4个等级,请求包为了避免系统僵化,不能使优先级3。设置合适的输出优先级是软件的责任。
VC是RapidIO的虚拟通道位,目前只支持虚拟通道0。
REG4的OutPortID域没有映射到RapidIO包header中,该域指明了传出包的port的号码,由CPU和NodeID共同设置。
REG4的ID Size 域指明了设备ID是8位的还是16位的。
REG4的SrcID_MAP域确定了本次传输要使用的ID寄存器。注意RIO_DeviceID_REGn是逻辑层的输入,并不是逻辑层的存储映射。
REG4的DestID域指明了目标设备的ID。
REG5的Ftype和TType是来确定包类型的。
REG5的Hop Count域是为类型8的维护包准备的。
REG5的DRbll Info域是为类型10的包准备的。
下表为状态寄存器(LSUn_REG6)的只读模式的描述

该模式下的LTID域是LSU的传输索引。 一个LSU能支持不止一个传输,这个索引就帮助确认传输的完成信息(completion code(cc)。
该模式下的LCB域是LSU的背景(上下文)位。该位的信息被传输过程利用,来确认CC的背景是否和当前的传输有关。
该模式下的FULL位指明所有的的影子寄存器(shadow registers)正在被使用,如果该位是0,则说明至少有一个影子寄存器可以被写入。如果该位是1,说明没有影子寄存器可以配置给任何传输过程。
该模式下的BUSY位指明了指令寄存器的状态。如果该位是0,说明接下来的一套传输描述符可以写入之指令寄存器。如果该位是1,说明指令寄存器正在被当前的传输过程占据,不可用。
下表展示的是LSU_REG6的只写模式

该模式下的Flush位有以下作用:如果LSU因为一个错误情况被冻结,该位写1将会清除掉所有匹配SRCID的影子寄存器。这一位将比Restart有更高的优先级。
该模式下的Restart位有以下作用:如果LSU因为一个错误情况被冻结,该位写1将会重启传输过程,到错误发生之前。
该模式下的SrcID_MAP域能被软件编辑,来指明要被清除的影存器的SRCID。
该模式下的CBusy位有以下功能:写1的情况下,如果PirvID匹配,就会清空busy位。写0没有什么作用。
该模式下的PrivID域有以下作用:当试图手动释放busy位的时候,释放busy位的CPU的PirvID必须与原始锁定LSU的CPU的PirvID匹配。
每个LSU的背后都有一套影子寄存器(shadow registers),每一个影子寄存器都可以配置用来提前准备传输,即transaction,当LSU空闲之后,就把数据从影存器中拿出来,送到LSU中去。当数据送到LSU中的时候,LSU0-LUS5的值是可以被读取的。在数据传输到LSU中之前,系统将会读取LSU0-5中的上一个数据。上面这些话的意思就是,在写REG5寄存器之前,是不能去LSU中读数的,还有,如果当前实施的指令前面还有未执行完的指令,也不能去LSU中读数。REG6可以读时写,因为它是用来锁定和释放的。
所有能被分配给LSU的影子寄存器都是可以配置的,一共有32套寄存器。这32套寄存器中,16套是用于LSU0-3的,其它16套是用于LSU4-7的,配给一个LSU的影子寄存器的数量,可以通过RIO_LSU_SETUP_REG0,这个寄存器配置。
当对RIO_LSU_SETUP_REG0寄存器进行编辑写入的时候,以下步骤必须遵循:
- step1:通过给BLK1_EN寄存器写0,禁用LSU块。
- step2:查看BLK1_EN_STAT寄存器的值为0,以确保LSU被禁用。
- step3:写值给LSU_SETUP_REG0寄存器,分配影子寄存器给LSU。
- step4:给BLK1_EN寄存器写1,使能LSU块。
影子寄存器还有以下限制:
- 每个LSU至少要拥有一个影子寄存器;
- 一个LSU拥有的影子寄存器不能超过9个;
- LSU0-3的影子寄存器合起来不能超过16个,这是软件必须检查的部分;
- 影子寄存器没有特殊的MMR(存储器映射寄存器),他们使用所属LSU的地址作为自己的地址。
下表列出了预定义的影存器组合。其它任何组合都不支持。有一个与32个影子寄存器有关的配置寄存器。配置数字是写到配置寄存器中的,基于配置数字,硬件分配影子寄存器给每个LSU。对于LSU0-3和LSU4-7,配置数字可以是不一样的。只有在LSU禁用,外设使能的双重前提下该配置影子寄存器才可以被编辑。

在使用LSU时可以使用核配置LSU模型
每个核都能将一定数量的影存器分配给LSU。如果一个LSU有6个影存器,那么就可以分配4个给核0,剩下两个给核1,当然这只是一种情况,你也可以分配1个给核0,5个给核1等等。这种分配方式保证了影存器可以在核之间公平的分配,而且也不会出现有一个核极度缺乏影存器的情况。如果一个核中的影存器被释放了,这意味着该核可以进行新的传输(transaction)了。
另一种情况是将一个LSU的所有影存器都给同一个核。
最推荐的是用户将所有传输分配给一个特定的LSU,这样会帮助缓解HOL blocking的压力。(HOL全称是head of line,意思就是由于FIFO的限制,很有可能排在队列后面的指令所需的设备已经空闲下来,但是指令因为排在队列后边,只能等待被处理,这样就浪费了等待时间内该设备的资源。)
EDMA配置LSU模型
该配置模型只支持一个特定的LSU上的EDMA单通道,而且只能用于一个核。LSU不能被共享,默认情况下是只有一个影存器分配给LSU,但是如果用户想要分配更多的影存器给LSU也是没有问题的。每套影存器都有LSU_Reg0-5。LSU_Reg6在Reg0-5之间是共享的,共享的目的最终是作用于一个特定的LSU。一次LSU传输是由写LSU_Reg0-5开始的,这些写的动作其实发生在影存器当中。如果LSU空闲,那么马上就选择一个可用的影存器,为 NREAD, NWRITE,NWRITE_R, SWRITE, ATOMIC, 或者 MAINTENANCE RapidIO transaction初始化一次数据传输。如果LSU正在工作于一组影存器之下,那么其余的影存器所共同配置的,正在等待的数据传输,应该等到当前传送结束。一旦LSU完成了它的当前任务,它将马上载入下一组影存器信息。因此,如果一个LSU有3个影存器,那么在他的队列里就永远都会有两个等待数据传输和一个正在进行的数据传输。
Full bit(满位)
CPU在给影存器写入数据之前,必须检测哪些影存器是可用的。因此CPU就会读取REG6的Full位来确认是否有寄存器空闲,如果该位是1,说明没有空闲的影存器了;如果该位是0,说明至少还有一个影存器正处于空闲状态。Full位只会在以下情况下被系统自动写1:当最后的影存器的LSU_Reg5的写入完成之后。所以Busy位和Full位是不可能同时被置1 的。
Busy bit(繁忙位)
为了避免两个CPU同时访问同一套影存器,设置了LSU_Reg6的Busy位。如果一个CPU想夺取LSU的使用权,它必须按照下面几种情况中的描述执行:
###1、锁住寄存器
CPU在确认LSU_Reg6的Busy位和Full位都是0的过程中,会发生以下几种情况:
a、Full位是1:这说明没有空闲的影存器,CPU必须重复读取Full位直到有空闲的影存器出现,如果软件设置了每一个CPU都能使用影存器的话,这种情况不可能出现。
b、有些CPU把LSU给锁了:在多核环境里,有可能发生一个CPU要读取的LSU被其它CPU锁住的情况。这种情况下读取LSU_Reg6得到的结果是Busy位是1,该核必须重复读取Reg6以尝试自己锁定它,EDMA没必要做这样的读取,因为它自己有专属的LSU所以不会导致冲突。
c、正常:CPU读取发现Busy位是0,这意味着可以使用LSU寄存器了,硬件将储存锁定LSU的核的PrivID,然后Busy位将会被置为1。这种情况下的唯一特例是,如果读的操作是来自于debugger端的动作,但尽管寄存器的值会被返回,然后这样的读取不会造成其他任何变化。
如果一个核锁了一个LSU,但是通过其他外设中读取了该LSU的busy位,那么该busy位就会一直被读取为1。因此,我们能够利用busy位将一套LSU寄存器在同一个核的不同任务中共享。只要REG5的被写操作完成,busy位就会清除,即变为0。
对REG6的读操作将会返回以下信息:
i. LTID(LSU transaction ID):这是一种暂时依附于transaction的ID,在传输的最后,软件可以使用这个ID来读取传输完成的相关代码。这个ID不能超过映射给LSU的寄存器的数量。例如对于LSU0,如果分给LSU0最多4个影存器,那么LTID只能是0-3.
ii. LCB (LSU Context Bit):这给status位给了一个参考系,来确定它是否是当前的transaction或者之前/之后的transaction。重置之后,如果某个LSU为了一个特定transactionID而锁定了,那LCB会返回一个‘1’值,下一次如果LSU又为了相同的transactionID而锁定,LCB就会返回一个‘0’值。因此如果读取的时候LCB位为1,而完成代码中指示的LCB位为0,软件就知道了完成信息并不是我们想要的。重置之后新的LCB对一个新的transactionID的返回值将会是‘1’。(这部分说的有点乱,意思就是LCB起到了一个区分同一个LSU的不同寄存器所做的传输的作用)。
注意:Busy位和Full位是要一起被读取的,因为如果CPU读取了Full位并获取了LSU寄存器的使用权,busy位马上就会被置1,试图查看busy位之后就会马上导致busy位被置1。所以Busy位和Full位一定要一起读取。
先读取REG6确定是否Full位和Busy位都是0,如果都是0,那么LSUx马上进入锁死工作阶段,直到它完成当前的任务,它才会被释放。如果有一个位是1,那么想要使用LSU的核就会一直读取Full位和Busy位来等待使用LSU。
###2、配置寄存器
REG0-4用CPU配置,CPU写REG0-4的请求的PrivID必须和之前锁定LSU的privID匹配,如果不匹配,CPU将无法对REG0-4进行写入。
当然,如果LSU被EDMA使用,那就另当别论,此时不需要进行PrivID的匹配。注意配置寄存器的时候,LSU可能在处理其他请求。
###3、解除锁定
最终对REG5的写入将会导致Busy位的清除。此时影存器已经准备好被LSU使用了。如果LSU正在繁忙当中,数据就会暂时存在影存器中,直到LSU完成了他当前的传输工作,影存器就会为LSU对他的使用,再次做好准备。
###4、由锁定而未写入导致的持续锁定
如果由于某些原因,锁定LSU的那个CPU没有继续完成写入其余寄存器的工作,LSU将锁定。另一个想要用这个LSU的CPU一直在读取REG6的返回内容,但是在一些尝试后,发现这个LSU一直被锁定,因为它发现busy位一直是1,并且LTID和LCB一直是同一个值,此时该CPU突然意识到有个CPU锁定了这个LSU并且没有再回来管它。
为了避免以上这种情况,在LSU_REG的只写模式中有一个位,叫CBUSY(clear busy),设备的master可以出面并且对cbusy置位。如果PrivID符合之前没有来的那个CPU的PrivID,硬件就会释放busy位。这个动作(释放busy位)将会对CC位写‘111’,这样这个特定的影存器的写入就完成了。注意下一个锁定该LSU的CPU将会使用完全不同的LTID和LCB。
寄存器 RIO_LSU_STAT_REG0-2用来与不同transaction的CC(completion code)保持密切联系,利用LTID附上信息返回给CC位。因为软件知道transaction分配给了哪个LSU,所以它知道要监控 RIO_LSU_STAT_REG0-2的哪一位。寄存器中的LCB位用来通知软件现在的参考系是否适用于当前传输,或之前和之后的传输,这个信息在软件咨询CC位的时候需要利用。
我们还需要影存器的状态位来显示影存器的状态。LSU4-7中也有一套3个相似的寄存器(RIO_LSU_STAT_REG3-5),如果CPU对LSU发出了清除或者重启的命令,CC位就会置为000,所有 RIO_LSU_STAT_REG0-5 寄存器的reset结果都是0。
寄存器 RIO_LSU_STAT_REG0-2用来与不同transaction的CC(completion code)保持密切联系,利用LTID附上信息返回给CC位。因为软件知道transaction分配给了哪个LSU,所以它知道要监控 RIO_LSU_STAT_REG0-2的哪一位。寄存器中的LCB位用来通知软件现在的参考系是否适用于当前传输,或之前和之后的传输,这个信息在软件咨询CC位的时候需要利用。
我们还需要影存器的状态位来显示影存器的状态。LSU4-7中也有一套3个相似的寄存器(RIO_LSU_STAT_REG3-5),如果CPU对LSU发出了清除或者重启的命令,CC位就会置为000,所有 RIO_LSU_STAT_REG0-5 寄存器的reset结果都是0。
可以看到Completion Code域有3位二进制数,指明了正在等待的命令的状态。
completion code域的取值如果是000,说明传输完成,没有错误,包括被提交的错误和没有提交的错误,都没有;
如果取值是001,说明在未提交的传输中发生了传输时间用尽;
如果是010,说明传输完成,但包没有发送,因为流控封锁了;
如果是011,说明传输完成,未提交的响应包(类型8和13)包含了错误状态,或者响应负载长度错误;
如果是100,传输完成,包没有发送,原因是包的类型不支持,或者出现了对至少一个LSU的编码是无效的;
如果是101,说明DMA传输错误;
如果是110,是重试门铃响应已经收到的情况,或者不允许atomic 测试交换;
如果是111,说明传输完成,没有发送包因为传输已经被Cbusy位的改变消灭(即Cbusy位改变导致旧的传输终结)。
LSU Context Bit域是当前CC的参考系,对一次传输来说,这需要LCB在读取LSU_REG6之后是同样匹配的,意思就是LCB在REG6读取之后和传输完成之后应该是同一个数值。
中断和LSU释放
LSU的CC位能够表示正在进行的传输的状态,自然也能显示出执行过程中的错误,而且一点出错,与这些错误有关的中断将迅速被上报给CPU。在上报处理阶段不会提交新的任务。
错误上报给CPU后,LSU只有在以下几种情况下才会被释放:
- CPU对restart或者flush位进行写入
- 如果对于未提交给CPU的transaction的所有响应都已经被接收,或者在接收响应时发生了超时。一旦发送响应超时,就不会有额外的中断或者CC位置位,来处理这次响应超时。如果接收到了所有响应,LSU就会只清除当前运行的transaction,并载入正在等待的一套寄存器。如果CPU写入了flush位,并且收到了所有响应,CPU将会清除掉影存器中的所有transaction,这里的影存器是特定LSU的影存器,这里的transaction是有特定SRCID_MAP 的transaction。如果restart和flush的命令都没有收到,但是收到了所有响应,外设将会一直等待直到收到CPU的restart或者flush超时信号。LSU将会抛弃所有transaction,包括当前拥有同一SRCID_MAP 的transaction导致的错误。在这之后,LSU会自动装载下一组数据。
有8个寄存器集,这允许对所有需要响应的transaction类型提供8个突出请求。对于多核设备来说,软件对这些寄存器进行管理,通过共享配置总线VBUSP来管理这些寄存器。单核设备能利用全部8个LSU块。
下图显示了一个NWRITE_R类型的transaction,图中包括该transaction的数据流和域映射。

“写”类型的命令,它的payload(负载消息内容的一个指针)与来自控制/命令寄存器的header信息相结合,然后导入到TX SharedBuffer-Pool,即图中右下角所示。最终payload被传递到TX的FIFO队列中进行传输。
“读”类型的命令没有payload,所以就只有控制/命令寄存器的域被缓存,然后使用它来创建一个RapidIO NREAD 包,进而传递到TX FIFO队列进行传输。从接收接口传递相应的响应包时,READ响应包的payload在RX资源池中被缓存。提交和未提交给CPU的操作都基于OutPortID命令寄存器,这样设计是为了确定合适的输出口或者确定合适的输出队列。
数据以DMA时钟频率,向Load/Store模块发送。
总结一下Load/Store模块的作用就是产生directIO包。
下图显示了发送数据的端口操作流程图。

- 用户通过配置LSU寄存器出发LSU传输
- LSU检查流控列表来确定哪个DestID是可以用的
- LSU检查每一个port的TX_FIFO状态
- 如果TX_FIFO可用并且没有正在进行的传输,CAU就发送VBUSM Read Commands来读取来源信息,并且将来源信息移动到共享TX Buffer池;如果TX_FIFO可用和没有正在进行的传输,这两个条件有一个不存在,就回到检查流控列表确定DestID可用那一步。
CPU利用VBUSP配置总线和控制/命令寄存器。这些寄存器包含传输描述符,这些传输描述符需要初始化读/写包的产生。在传输描述符被初始化写好之后,就要确认流控状态。确认流控状态的模块检测命令寄存器的DESTID和PRIORITY域来确定流通道是否已经被占用,还有,TX FIFO的空闲状态也要被检查,该操作是通过检查命令寄存器的OutPortID实现的。只有在流控通道被打开,TX FIFO被分配缓存之后,才会产生一个VBUSM读命令,该读命令作用于将被移入到TXbuffer池的payload数据。数据以简单的顺序从共享buffer池移动到合适的输出TX FIFO,这种顺序基于VBUSM传输的completion情况。只要数据被传输到FIFO中,数据就一定能通过管脚发送。
TX操作
写传输
下图显示了SRIO内部的缓存机制。

多核之间共用Shared TX Data Buffer。一个状态机在LSU和其他协议单元之间进行仲裁和分配可用的buffer。只有在来自VBUSM的payload的最后一个字节被写入Shared TX Data buffer之后,Load/Store模块才会把包送到TX FIFO,一旦包被送到TX FIFO,共享缓存就可以释放,并且用于其他transaction了。
TX缓冲区在所有输出源之间动态共享,这些输出源包括LSU,TX CPPI,来自RX CPPI和MAU的响应包。所以缓存空间存储需要分段对带payload的包和不带payload的包进行处理。
一条消息最多有16个包,每个包的最大尺寸是256B,同时还可以有不带payload只含header的包。数据以接收的顺序离开共享缓存,离开时不需要确认包的优先级,但是数据离开TX FIFO时需要考虑到优先级。
对于提交的WRITE操作不需要RapidIO响应包,一个核有可能提交各种各样的输出请求。例如,一个单一的核可能在任何给定的时间内让流写数据包进行缓存,并且提供了输出源。在这个例子中,一旦数据包写入共享TX缓存池,LSU就会释放给影存器。如果请求被流控,外设将设置completion code status register并且使用中断位ICSR。当中断路由完成的时候,控制/命令寄存器就会被释放。
对于未提交的WRITE操作需要RapidIO响应包,任何给定的时间里每个核只能有一个向外的请求。消息包会写入TX缓存池,当然,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。在原子输出测试和交换包中有一种特殊情况,这种包是唯一 一种需要有带有payload的响应的Write类型的包,这种响应的payload被路由到LSU,然后payload被检查以确认信号是否被收到,随后对completion code进行适当的设置。payload并没有通过VBUSM传出外设。
所以一般的流程是:
- 通过VBUSP(配置总线)配置控制寄存器
- 流控确认
- TX FIFO(TX共享缓存池)可用确认
- VBUSM读取对数据payload的请求
- VBSUM在共享TX缓存区域响应给特定模块缓存的写数据
- VBSUM读响应被监控,等待payload的最后一位
- 命令寄存器的header数据写入共享TX缓存空间
- 将payload和header传递给TX FIFO
- 如果不需要RapidIO响应,载入下一个影存器
- 基于优先级从TX FIFO传递数据给外部
读传输
产生读传输的流程和产生带有响应的未提交的WRITE传输相似。不过还是有两个主要的不同,首先,READ包包含不带数据的payload;其次,READ响应是带payload的。所以读命令只需要TX缓存池中的一块无负载缓存,当然,还需要一块共享RX缓存,这块缓存不是在READ包传输开始之前就分配好的,因为这会造成其它输入包去其它模块的交通阻塞。
重复一遍,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。
因此一般的流程是这样的:
- 通过配置总线VBUSP配置命令寄存器
- 流控确认
- 分配TX FIFO缓存
- 命令寄存器中的header数据写入到共享TXbuffer
- 传递header数据给TX FIFO
- 基于优先级从TX FIFO相外部传递数据
- 当数据返回UDI接口时,通过VBUSM总线将数据发送出去
对于所有的传输,共享TX缓存都会在包被推送到TX FIFO之后就立即释放,如果接收到了一个未提交传输(non-posted transaction)的ERROR或者RESPONSE信号,CPU必须重新配置REG6或者重新开始这个传输。
包分段
LSU对向外的请求有两种分段方法。一种是请求的Byte_Count超过256B,另一种是请求的RapidIO地址是非64位的。这两种情况下,向外的请求都要被分解成多个RapidIO请求包。例如,CPU相对外部的RapidIO设备进行1KB的存储操作,配置好LSU寄存器之后,CPU对REG5命令寄存器进行了一个简单的写入操作,然后外设硬件将存储操作分为4个RapidIO写包,每个都是256B大,然后计算每个包的64位RapidIO地址,WRSIZE和 WDPTR。在所有提交包传递给TX FIFO之后,释放LSU。对于未提交操作,像CPU载入,在LSU释放之前,必须收到所有的包响应。
RX操作
响应包的类型一直是RapidIO包类型13。所有带有传输类型的响应包不等于0b0001,并且不超过128个SRCTID以接收顺序路由给LSU。这些包是否带有payload取决于相应的请求包。由于RapidIO交换系统的性质,响应包可以以任何顺序到达。数据payload(如果有的话)和数据header是从RX FIFO移动到共享RX缓存中去。包的TargetID域用以确定等待响应的核和相应的寄存器。记住,每个核只能有一个外向请求。通过VBUSM总线操作,所有的payload数据从共享RX缓存池移动到存储区域。
MAU管的是所有进来的DirectIO包,包括 NREAD,SWRITE, NWRITE 和 NWRITE_R 传输。不支持进来的原子操作,如果进来会以ERROR的形式响应。对于DirectIO包,MAU负责路由DOORBELL消息给中断处理器,MAU也负责包的前向传输。
所有进来的DirectIO包包含一个存储地址域,该地址是设备的存储映射,决定数据将会写在哪里或者从哪里读取数据。不支持通过外设翻译RX地址。RapidIO包的地址将被应用于DMA传输。这种方式需要DirectIO传输知道目标设备的映射地址信息。当然,我们必须知道对目标地址的覆盖写,是没有一种硬件保护机制的。这种保护必须在系统级的软件层面进行管理。一些存储访问可能在设备级层面被限制到监督协议中,即设备自身带有监督协议,来管理存储访问。大多数存储访问通过用户允许就能使用。MAU给每一个接收到的DMA传递来的包配置用户许可证,除非包的SOURCEID和RIO_SUPRVSR_ID的值相匹配。如果匹配RIO_SUPRVSR_ID的值,就会被颁发监督许可证。
复位和掉电
通过reset,Load/Store模块将所有寄存器的域置为默认状态的值,等待CPU的处理。
如果DirectIO协议在应用中不被支持,那么Load/Store模块就可以掉电。例如,如果使用Message协议进行传输,那么就可以对Load/Store模块进行掉电操作,以达到省电的目的,在这种情况下命令寄存器应该掉电并设置为不能访问。在掉电状态下,这些模块的时钟就要被gate掉。
时序
对于 传输来说,任何时候LSU都能准备就绪。在传输确定时序之前,下面的情况要被提供。
-
优先级,CRF:只有最高等级的优先级和CRF的传输才会为每个port考虑时序
-
流控:transaction的DESTID不应该被流控
-
未提交传输的SRCID:如果这个SRCID正在被一个未提交传输使用,而新的为提交传输来自同一个SRCID,那么新的传输就会被挂起,直到旧的传输完成
-
SRIO VBUSM总线限制:VBUSM接口最多支持4个写和4个读传输同时进行,VBUSM被MAU、LSU和TXU共享,如果LSU想在VBUSM接口发送一个命令,那么VBUSM接口应该处于空闲状态。
-
FIFO : FIFO中应该有足够的空间容纳一次传输
如果多个LSU达到了以上条件,scheduler将以环形签字方式决定谁先谁后。
DirectIO编程注意事项
下面的代码段中显示了LSU的编辑细节,这里用的是CSL 寄存器层的API来演示读和写操作。文章来源:https://www.toymoban.com/news/detail-613674.html
/***** 步骤1:锁定LSU ************************************************************************************************/
/* 同时检测FULL位和BUSY位,确定影存器是否空闲和未锁定*/
value = CSL_FEXTR(SRIO_REGS->LSU[Lsuno].LSU_REG6, 31, 30);
while (value != 0)
{
value = CSL_FEXTR(SRIO_REGS->LSU[Lsuno].LSU_REG6, 31, 30);
}
/***** 存储LTID域,以得到LSU影存器号码*****/
LTID = CSL_FEXT(SRIO_REGS->LSU[Lsuno].LSU_REG6, SRIO_LSU_REG6_LTID);
/***** 存储LCB位来确认完成码的有效性*****/
LCB = CSL_FEXT(SRIO_REGS->LSU[Lsuno].LSU_REG6, SRIO_LSU_REG6_LCB);
/*******************************************************************************************************************************/
/***** 当前LSU被锁定,所有核都会看到BUSY位是1***********/
/*******************************************************************************************************************************/
/***** 步骤2:配置LSUx_REG 0 – 4 ********************************************************************************/
/***** 为目标DSP缓存编辑地址*****/
SRIO_REGS->LSU[Lsuno].LSU_REG0 = CSL_FMK( SRIO_LSU_REG0_ADDRESS_MSB,0 );
SRIO_REGS->LSU[Lsuno].LSU_REG1 = CSL_FMK( SRIO_LSU_REG1_ADDRESS_LSB_CONFIG_OFFSET,(int )&rcvBuff[0] );
/***** 为源DSP缓存编辑地址*****/
SRIO_REGS->LSU[Lsuno].LSU_REG2 = CSL_FMK( SRIO_LSU_REG2_DSP_ADDRESS, (int )&xmtBuff[0]);
/***** 编辑payload大小并且在编程实现完成之后不会响铃*****/
SRIO_REGS->LSU[Lsuno].LSU_REG3 = CSL_FMK( SRIO_LSU_REG3_BYTE_COUNT,byte_count )|
CSL_FMK( SRIO_LSU_REG3_DRBLL_VAL, 0);
/***** 从Port0发送数据,只在错误情况下产生中断 *****/
SRIO_REGS->LSU[Lsuno].LSU_REG4 = CSL_FMK( SRIO_LSU_REG4_OUTPORTID,0 )|
CSL_FMK( SRIO_LSU_REG4_PRIORITY,0 )|
CSL_FMK( SRIO_LSU_REG4_XAMBS,0 )|
CSL_FMK( SRIO_LSU_REG4_ID_SIZE,1 )|
CSL_FMK( SRIO_LSU_REG4_DESTID,0xBEEF )|
CSL_FMK( SRIO_LSU_REG4__REQ,1 )|
CSL_FMK( SRIO_LSU_REG4_SUP_GINT, 1)|
CSL_FMK( SRIO_LSU_REG4_SRCID_MAP, 0);
/*******************************************************************************************************************************/
/*****步骤3:开始传输****************************************************************************/
SRIO_REGS->LSU[Lsuno].LSU_REG5 = CSL_FMK( SRIO_LSU_REG5_DRBLL_INFO,0x0000 )|
CSL_FMK( SRIO_LSU_REG5_HOP_COUNT,0x00 )|
CSL_FMK( SRIO_LSU_REG5_PACKET_TYPE,type );在步骤3之后,如果确定不会有其它核使用这个LSU,就没必要为下一次LSU操作检查BUSY位,只需要检查FULL位并且锁定LSU,为下一组影存器的写入做好准备。文章来源地址https://www.toymoban.com/news/detail-613674.html
到了这里,关于SRIO——DIO通信模式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!