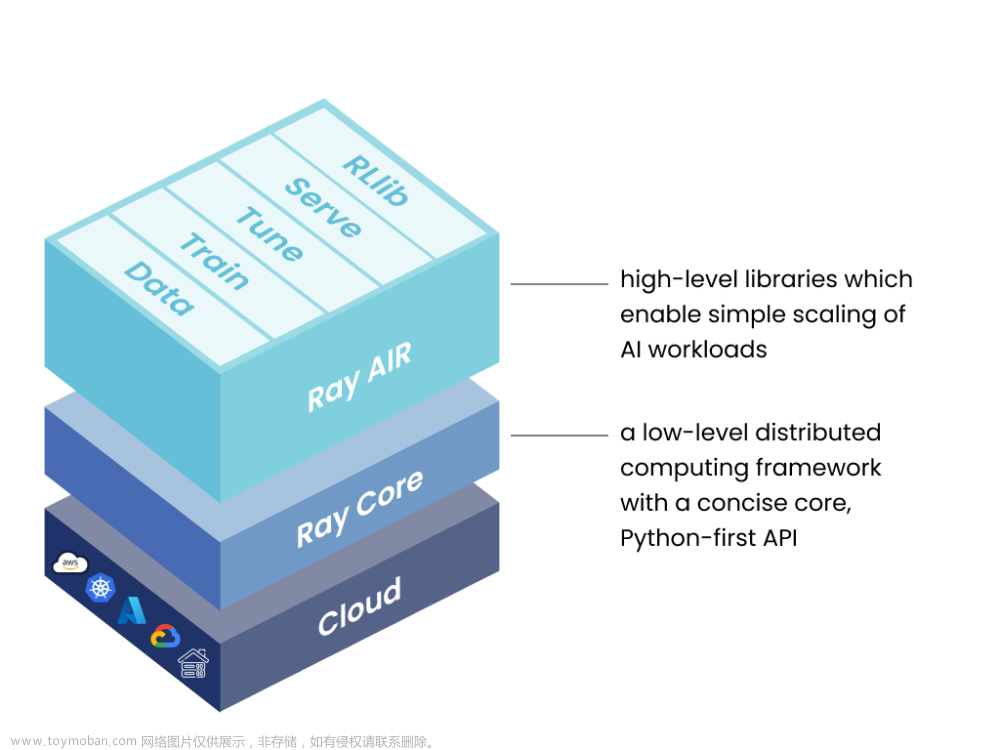
Ray Tune作为Ray项目的一部分,它的设计目标是简化和自动化机器学习模型的超参数调优和分布式训练过程。Ray Tune简化了实验过程,使研究人员和数据科学家能够高效地搜索最佳超参数,以优化模型性能。
Ray Tune的主要特点包括:
-
超参数搜索空间规范: Ray Tune允许您使用多种方法定义超参数搜索空间,如网格搜索、随机搜索和贝叶斯优化。这使您能够轻松地尝试不同的超参数组合。
-
与多种机器学习库集成: Ray Tune不依赖于任何特定的机器学习框架,这意味着它可以与流行的库(如TensorFlow、PyTorch、Scikit-learn等)一起使用。它为不同库提供了统一的API,方便在不改变代码库的情况下切换框架。
-
分布式计算: Ray Tune是建立在Ray分布式计算框架之上,使其能够高效地跨多个CPU和GPU进行扩展。这种分布式执行能力可以加速大规模模型的超参数搜索和训练。
-
异步超参数搜索: Ray Tune支持异步超参数搜索,这意味着它可以同时评估多个超参数配置。这有助于显著减少整体搜索时间,特别是在评估计算成本较高的模型时。
-
超参数调度器: 该库包含各种调度器,如HyperBand和ASHA(Asynchronous Successive Halving Algorithm),它们可以动态地为有希望的超参数配置分配资源,同时剪枝不太有希望的配置。这种自适应资源分配策略有助于集中精力处理最有希望的超参数设置,节省时间和计算资源。
-
简单的实验跟踪和可视化: Ray Tune与流行的机器学习实验跟踪工具TensorBoard集成在一起,方便可视化和分析不同超参数调优实验的结果。
要使用Ray Tune,通常需要将模型训练代码定义为可训练函数,并使用提供的API指定超参数搜索空间。然后,Ray Tune将管理探索超参数组合的过程,以分布式方式启动训练任务,并跟踪结果。
Ray Tune的核心思想原理是将超参数调优和分布式训练过程进行有效地集成和管理,以提高机器学习模型的性能和训练效率。以下是Ray Tune的核心思想原理:
-
分布式计算和任务调度:Ray Tune建立在Ray分布式计算框架之上,利用Ray的强大分布式能力来并行地执行多个模型训练任务。Ray允许跨多个CPU和GPU节点运行任务,从而显著加速模型训练过程。
-
可训练函数:Ray Tune要求用户将模型训练代码封装在一个可训练函数中,通常称为Trainable Function。这个函数接受一个超参数配置作为输入,并在给定超参数配置下训练模型。Ray Tune将根据指定的超参数搜索空间多次调用这个函数。
-
超参数搜索空间规范:用户可以在Trainable Function中使用Ray Tune提供的API来定义超参数搜索空间。可以使用
tune.grid_search、tune.choice、tune.uniform等函数来指定超参数的取值范围,从而确定超参数搜索范围。 -
并行运行和异步搜索:Ray Tune支持并行运行多个模型训练任务,每个任务对应不同的超参数配置。这样可以同时评估多个超参数配置,实现异步超参数搜索,从而加快搜索过程。
-
超参数调度器:Ray Tune提供了一些超参数调度器,如HyperBand和ASHA。这些调度器可以动态地为有希望的超参数配置分配更多资源,并提前终止不太有希望的配置,从而加速搜索过程。
-
实验结果跟踪和分析:Ray Tune集成了TensorBoard,可以将试验结果可视化,包括不同超参数配置的性能和训练过程。这有助于用户更好地理解实验结果,从而优化超参数搜索策略。
-
提前终止和资源限制:用户可以在Trainable Function中实现提前终止机制,当模型在某个超参数配置下没有进一步提高时,可以提前终止训练,节省时间和资源。此外,用户还可以使用资源限制来控制每个试验使用的资源,避免资源过度消耗。
Ray Tune的核心思想是通过分布式计算和异步超参数搜索,有效地管理并加速超参数调优和模型训练过程。同时,提供多样的搜索算法和超参数调度器,帮助用户更好地优化模型性能。整体上,Ray Tune使超参数调优过程更高效、更自动化,并在大规模模型和计算密集型任务中表现出色。
当使用Ray Tune进行超参数调优时,以下是一些技巧和最佳实践,可以帮助您更有效地利用这个强大的库:
-
定义可训练函数(Trainable Function): 将模型训练代码封装在一个可训练函数中,这样可以使代码更加模块化和易于管理。可训练函数应该接受一个参数(通常称为
config),其中包含要调优的超参数。Ray Tune将根据指定的超参数配置多次调用该函数。 -
指定搜索空间: 在
config参数中定义超参数搜索空间。可以使用tune.grid_search、tune.choice、tune.uniform等函数来指定超参数的取值范围。根据问题的复杂性,选择合适的搜索空间。 -
选择适当的搜索算法: Ray Tune支持多种搜索算法,包括网格搜索、随机搜索和贝叶斯优化等。对于较小的搜索空间,可以使用网格搜索和随机搜索。对于更大和复杂的搜索空间,贝叶斯优化可能更有效率。
-
使用超参数调度器: 超参数调度器,如HyperBand和ASHA,可以在调优过程中动态地分配资源,更快地收敛到较好的超参数配置。考虑使用调度器来节省计算资源。
-
并行运行: 如果计算资源充足,可以增加
num_samples参数,以在并行中执行多个超参数配置的试验。这将加速调优过程。 -
提前终止(Early Stopping): 在可训练函数中实现提前终止机制,当模型在某个超参数配置下没有进一步提高时,可以提前终止训练,节省时间和资源。
-
使用资源限制: 根据资源的可用性和预算,使用
tune.run的resources_per_trial参数来限制每个试验使用的资源。这有助于避免资源过度消耗。 -
实验结果可视化: Ray Tune与TensorBoard集成,可以将试验结果可视化,包括不同超参数配置的性能和收敛情况。这有助于更好地理解超参数搜索的效果。
-
迭代优化: 超参数调优往往需要多次迭代。根据之前的结果调整超参数搜索空间和搜索策略,逐步优化模型性能。
-
使用Checkpoints: 如果训练过程较长,建议使用
tune.Checkpoint来保存中间结果。这样,如果程序崩溃或中断,您可以从上次保存的检查点继续进行,节省时间和计算资源。 -
利用Ray Tune的其他功能: Ray Tune提供了许多其他功能,如可视化工具、实验结果分析等。充分利用这些功能,可以更好地管理实验和优化模型。
最后,超参数调优通常需要进行一定的试错和尝试。不同问题和模型可能需要不同的超参数搜索策略,因此建议尝试不同的方法,找到最适合您的情况的超参数调优策略。
Ray Tune是一个功能强大的超参数调优和分布式训练库,但它也有一些优点和缺点,让我们来看一下:
优点:
-
灵活性和通用性:Ray Tune不依赖于特定的机器学习框架,因此可以与多个流行的框架(如TensorFlow、PyTorch等)无缝集成。这使得它在各种不同的机器学习任务中都能发挥作用。
-
分布式计算:Ray Tune建立在Ray分布式计算框架之上,能够高效地利用多个CPU和GPU进行并行训练。这使得它适用于大规模模型和计算密集型任务。
-
多样的搜索算法:Ray Tune支持多种超参数搜索算法,包括网格搜索、随机搜索和贝叶斯优化。这使得用户可以根据不同问题和资源预算选择合适的搜索策略。
-
异步超参数搜索:Ray Tune支持异步超参数搜索,可以同时评估多个超参数配置,从而节省整体搜索时间。
-
超参数调度器:Ray Tune提供了一些超参数调度器,如HyperBand和ASHA,可以动态地分配资源并提前终止不太有希望的超参数配置,从而加速搜索过程。
-
实验结果可视化:Ray Tune与TensorBoard集成,可以轻松地可视化不同超参数配置的性能和训练过程,帮助用户更好地理解实验结果。
缺点:
-
学习曲线:对于一些简单的模型和小规模数据集,使用Ray Tune的收益可能不会那么明显。超参数调优对于某些模型和数据集的提升可能有限。
-
算法选择复杂性:选择合适的搜索算法和超参数搜索空间可能需要一些经验和实验,特别是对于新手来说可能需要一定的学习曲线。
-
资源消耗:分布式计算和异步超参数搜索会消耗更多的计算资源。如果资源有限,可能需要进行适当的资源配置和限制。
-
高级用法学习成本:Ray Tune提供了许多高级功能,例如提前终止、资源限制、检查点等,了解和使用这些功能可能需要花费一些时间。
-
依赖性:Ray Tune依赖于Ray分布式计算框架,这意味着在使用Ray Tune之前需要安装和配置Ray,可能会增加一些复杂性。
Ray Tune是一个非常有用的工具,可以大大简化超参数调优和分布式训练的流程。但是,对于一些简单的问题和资源有限的情况,可能需要权衡是否使用Ray Tune。对于复杂的问题和大规模的训练任务,Ray Tune可以发挥其优势,提高模型性能并节省训练时间。
以下是一个简单的Ray Tune示例代码,展示了如何使用Ray Tune进行超参数调优:
import ray
from ray import tune
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 定义可训练函数,用于训练随机森林模型并返回交叉验证的平均准确率
def train_model(config):
# 加载数据集
data = load_iris()
X, y = data.data, data.target
# 创建随机森林分类器
rf = RandomForestClassifier(n_estimators=config["n_estimators"],
max_depth=config["max_depth"],
min_samples_split=config["min_samples_split"])
# 使用交叉验证计算准确率
scores = cross_val_score(rf, X, y, cv=3)
accuracy = scores.mean()
# 将准确率返回给Ray Tune
return {"mean_accuracy": accuracy}
if __name__ == "__main__":
# 初始化Ray
ray.init(ignore_reinit_error=True)
# 定义超参数搜索空间
config = {
"n_estimators": tune.grid_search([50, 100, 150]),
"max_depth": tune.grid_search([None, 10, 20]),
"min_samples_split": tune.grid_search([2, 5, 10])
}
# 运行Ray Tune进行超参数调优
analysis = tune.run(train_model, config=config, num_samples=10, metric="mean_accuracy")
# 获取最佳超参数配置和结果
best_config = analysis.get_best_config(metric="mean_accuracy")
best_accuracy = analysis.best_result["mean_accuracy"]
print("Best Hyperparameters:", best_config)
print("Best Mean Accuracy:", best_accuracy)
在这个例子中,我们使用sklearn库中的鸢尾花数据集,使用随机森林作为模型,并使用交叉验证计算模型的准确率。我们定义了三个超参数:n_estimators(决策树的个数)、max_depth(决策树的最大深度)和min_samples_split(决策树分裂所需的最小样本数)。我们通过tune.grid_search来指定超参数的搜索空间。
接下来,我们使用tune.run函数来运行Ray Tune进行超参数调优。num_samples参数指定了我们希望运行的超参数配置数量,metric参数指定了我们希望优化的指标(在这里是平均准确率)。
最后,我们可以通过analysis.get_best_config和analysis.best_result来获取最佳超参数配置和对应的平均准确率,并将其打印出来。
请注意,这只是一个简单的示例,Ray Tune还有许多高级用法和功能,可以根据具体情况进行更复杂和灵活的超参数调优。文章来源:https://www.toymoban.com/news/detail-613865.html
文章来源地址https://www.toymoban.com/news/detail-613865.html
到了这里,关于机器学习分布式框架ray tune笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!