消费者组 - Consumer Group
上文我们已经讲过消费者组了,我们知道消费组的存在可以保证一个主题下一个分区的消息只会被组内一个消费者消费,从而避免了消息的重复消费
什么是消费组 - Consumer Group?
消费者组是Kafka 提供的可扩展且具有容错性的消费者机制
消费组的三大特性
- 消费组有一个或多个消费者,消费者可以是一个服务、一个进程、一个线程
- 消费组具有一个唯一标识字符串,
group.id - 消费组订阅的主题每个分区只能分配给一个消费者
怎么理解呢,其实就是让Kafka的客户端(此时指消费者)具有弹性,弹性伸缩,可扩展,具有容错性
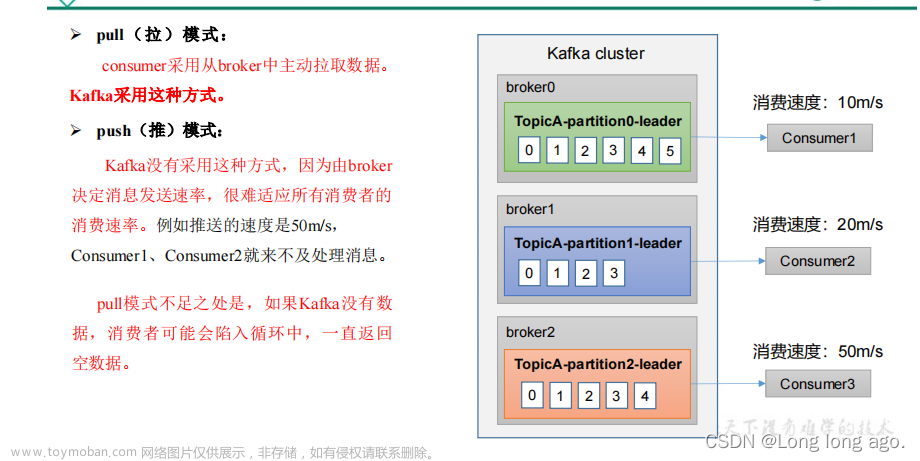
比如我们有一个主题,主题有5个分区,我们有一个消费组,组内有3个消费者组成消费者集群,如下图
比如此时消费者消费能力不够了,我们可以在线添加一个消费者到消费组,提升消费能力,当然不管增加消费者还是消费者下线,都需要重新分配分区与消费者的关系(Rebalance)如下图


消费组的存在就是说: 以消费组的名义,去消费主题的消息,当然最终消费组里的消费者有多少取决于主题有多少个分区
记录偏移量,多于分区个数的消费者会分配不到分区而造成空闲;同时也是以消费组的名义,在Kafka里记录消费消息的偏移量
既然讲到偏移量,那我们来看看偏移量(位移)是怎么管理的?
位移管理
首先位移就是偏移量(offset),就是消息的编号,Kafka内置了一个主题
_consumer_offset来记录分区消费情况(该分区消费到第几号消息了),那么为什么说偏移量是由消费者自己管理的呢?因为是消费者自己决定消费分区里第几号消息,然后把这个偏移量信息定期提交到Kafka去,Kafka再将偏移量信息记录到_consumer_offset主题去,所以其实消费者本身也是一个生产者
消费者提交偏移量的两种方式
- 自动提交,Kafka默认自动提交,可以通过参数调整
enable.auto.commit = false即关闭自动提交 - 手动提交
Kafka 是如何记录偏移量信息的呢?
消费者是在消费消息的过程中定期提交偏移量的
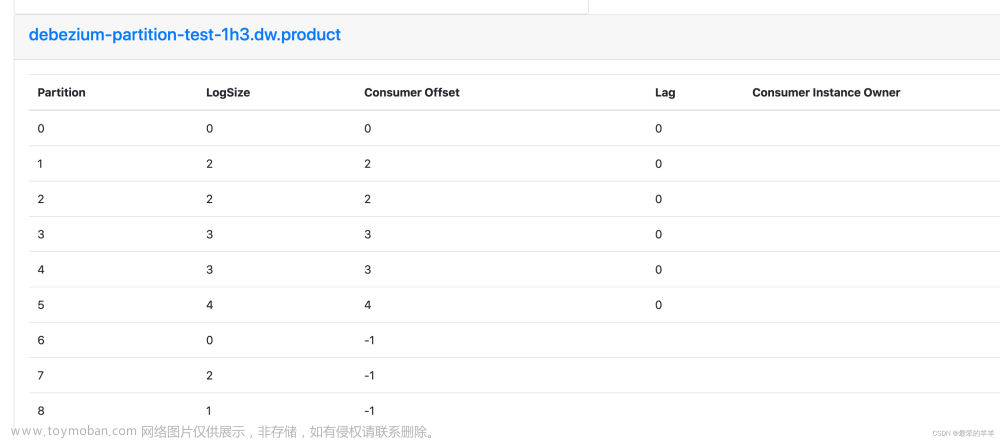
Kafka会将group消费情况保存起来,做成一个offset map,如下图:文章来源:https://www.toymoban.com/news/detail-614217.html
key: groupId + Topic + partition
value: offset
绿色代表已经消费过了,红色代表未被消费消息,箭头代表偏移量,下一次要消费的消息
在文件里实际存储形式如下:
在这里插入图片描述文章来源地址https://www.toymoban.com/news/detail-614217.html
以消费组的名义记录偏移量信息
这里我们发现记录偏移量时没有消费者什么事,这也是Kafka设计的精妙之处,
任意消费者分配了分区后只要以消费组的名义都能获取分区数据,
当消费者伸缩重新分配分区后,依然可以继续消费,
因为偏移量没有跟消费者绑定,是跟消费组绑定的,这也是一种容错机制
类似于Java里面多态的一种思想
到了这里,关于Kafka 入门到起飞系列 - 消费者组管理、位移管理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!