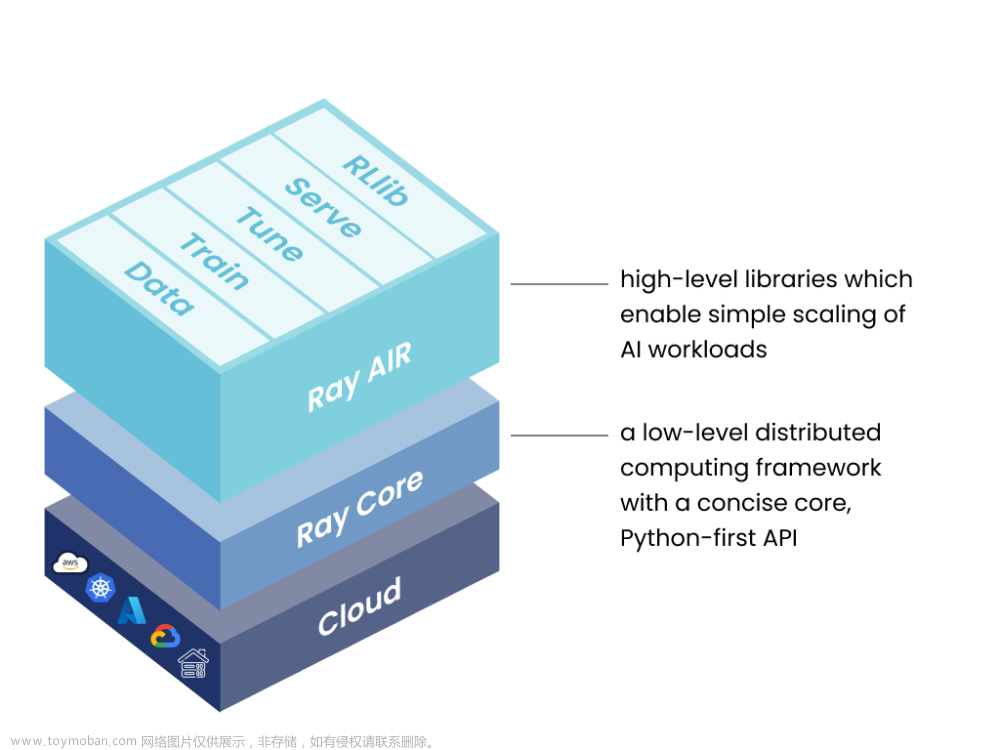
使用Ray来实现TensorFlow的训练是一种并行化和分布式的方法,它可以有效地加速大规模数据集上的深度学习模型的训练过程。Ray是一个高性能、分布式计算框架,可以在集群上进行任务并行化和数据并行化,从而提高训练速度和可扩展性。
以下是实现TensorFlow训练的概括性描述:
-
Ray集群配置:首先,需要配置Ray集群,确保所有节点都能够访问共享的存储和资源。这可以通过安装Ray库并启动Ray头节点和工作节点来完成。
-
数据并行化:将大规模的数据集划分为多个部分,并将其分发到不同的Ray工作节点上。每个节点负责处理自己的数据子集,以实现数据并行化。
-
模型定义:使用TensorFlow定义深度学习模型,包括输入层、隐藏层、输出层等。确保模型的参数可以在不同节点间传递和同步。
-
训练任务并行化:使用Ray的任务并行功能,将TensorFlow的训练任务拆分为多个独立的子任务,并在Ray工作节点上同时运行这些任务。这样可以并行地更新模型参数,提高训练速度。
-
参数同步:在每个训练迭代中,通过Ray的分布式共享内存 (distributed memory) 功能来同步模型参数。这确保所有节点上的模型保持一致,以避免训练过程中的不一致性。
-
迭代训练:重复执行训练迭代直至收敛。每个节点将根据自己的数据子集计算梯度,并在全局参数更新后更新自己的本地模型。
-
结果汇总:在训练完成后,收集所有节点的模型参数,并根据需要对它们进行平均或其他集成方法,以获得最终的训练模型。
通过Ray的并行化和分布式计算能力,可以充分利用集群中的计算资源,加快TensorFlow模型的训练过程,特别是在处理大规模数据集时,可以显著提高效率和训练速度。
使用 Ray 来实现 TensorFlow 的训练代码可以通过将训练任务分发到多个 Ray Actor 进程中来实现并行训练。以下是一个简单的示例代码,演示了如何使用 Ray 并行训练 TensorFlow 模型:
首先,确保你已经安装了必要的库:
pip install ray tensorflow现在,让我们来看一个使用 Ray 实现 TensorFlow 训练的示例:
import tensorflow as tf
import ray
# 定义一个简单的 TensorFlow 模型
def simple_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
return model
# 定义训练函数
def train_model(config):
model = simple_model()
optimizer = tf.keras.optimizers.SGD(learning_rate=config["lr"])
model.compile(optimizer=optimizer, loss='mse')
# 假设这里有训练数据 data 和标签 labels
data, labels = config["data"], config["labels"]
model.fit(data, labels, epochs=config["epochs"], batch_size=config["batch_size"])
return model.get_weights()
if __name__ == "__main__":
# 初始化 Ray
ray.init(ignore_reinit_error=True)
# 生成一些示例训练数据
data = tf.random.normal((100, 10))
labels = tf.random.normal((100, 1))
# 配置训练参数
config = {
"lr": 0.01,
"epochs": 10,
"batch_size": 32,
"data": data,
"labels": labels
}
# 使用 Ray 来并行训练多个模型
num_models = 4
model_weights = ray.get([ray.remote(train_model).remote(config) for _ in range(num_models)])
# 选择最好的模型(此处使用简单的随机选择)
best_model_weights = model_weights[0]
# 使用训练好的模型进行预测
test_data = tf.random.normal((10, 10))
best_model = simple_model()
best_model.set_weights(best_model_weights)
predictions = best_model.predict(test_data)
print(predictions)
# 关闭 Ray
ray.shutdown()
上述代码演示了一个简单的 TensorFlow 模型(simple_model)和一个简单的训练函数 (train_model)。通过将训练任务提交给 Ray Actor 来并行训练多个模型,并在最后选择表现最好的模型进行预测。请注意,这里的数据集和模型都是简化的示例,实际情况下,你需要使用真实数据和更复杂的模型来进行训练。
首先导入所需的库,包括TensorFlow和Ray。
定义一个简单的TensorFlow模型simple_model,该模型包含一个具有ReLU激活函数的10个神经元的隐藏层,以及一个没有激活函数的输出层,输出层具有1个神经元。
定义一个训练函数train_model,该函数接受一个配置字典config,其中包含训练所需的参数。在此函数中,首先创建了一个简单的TensorFlow模型。然后,根据配置字典中的学习率创建一个随机梯度下降(SGD)优化器,并将均方误差(MSE)作为损失函数。接下来,从配置字典中获取训练数据data和标签labels,并使用这些数据对模型进行训练。最后,返回训练后的模型权重。
在主程序中,初始化Ray,设置ignore_reinit_error=True,以允许在同一个程序中多次调用ray.init(),这样可以避免Ray重复初始化的错误。
生成一些示例训练数据data和标签labels,并设置训练所需的配置参数config,包括学习率lr、训练轮数epochs、批量大小batch_size以及训练数据和标签。
使用Ray来并行训练多个模型,通过ray.remote将train_model函数转换为远程任务,然后使用列表推导式生成多个任务并行地进行训练。ray.get函数用于获取所有模型的权重列表model_weights。
简单地选择第一个模型的权重作为最佳模型权重。
使用测试数据test_data创建一个新的模型best_model,然后将最佳模型的权重设置到best_model中,并使用它对测试数据进行预测,得到预测结果predictions。
关闭Ray集群。这里并不需要等待所有训练任务完成,因为ray.get已经确保在获取模型权重时会等待所有任务完成。关闭Ray集群会释放资源。
总结:这段代码使用Ray实现了一个简单的多模型并行训练过程,首先生成一些示例训练数据,然后通过Ray并行地训练多个模型,最后选择其中一个模型作为最佳模型,并使用它对测试数据进行预测。通过Ray的并行化能力,可以加快训练过程,尤其是在大规模数据集和复杂模型的情况下,能够有效地提高训练效率。文章来源:https://www.toymoban.com/news/detail-614256.html
文章来源地址https://www.toymoban.com/news/detail-614256.html
到了这里,关于机器学习分布式框架ray运行TensorFlow实例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!