优先级队列(堆)
羡慕别人就让自己变得更好!
- 优先级队列(堆)可用于topK问题
- 有大小根堆
- 注意堆的模拟实现
坚持真的很难但是真的很酷!
一、优先级队列
1. 概念
- 队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列。
- 此时,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
- 优先级队列实现了Queue接口。
二、优先级队列的模拟实现
JDK1.8中的PriorityQueue底层使用了堆的数据结构,而堆实际就是在完全二叉树的基础之上进行了一些元素的调整。
1. 堆的概念
- 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
(即: 大根堆:根结点值比左右子树的值都大;
小根堆:根结点值比左右子树的值都小) - 堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;(也就是有小大根堆之分)
- 堆总是一棵完全二叉树。
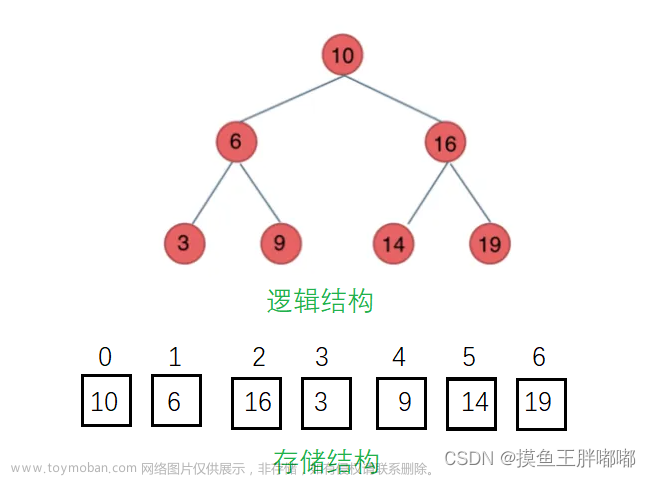
2. 堆的存储方式
- 堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储
- 注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
- 也就是说:
完全二叉树适合使用数组进行存储,层序遍历; 一般二叉树不适合顺序方式进行存储,浪费存储空节点的空间。 - 注意如何推导孩子结点以及父亲结点:
将元素存储到数组中后,可以根据二叉树的性质对树进行还原。假设i为节点在数组中的下标,则有:
- 如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
- 如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
- 如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
3. 堆的创建
1. 堆向下调整
-
【向下调整】:调整时,找左右孩子中的最大值(最小值),然后与根结点进行比较并交换就ok。调整都是从每棵子树的根结点开始的。
-
问题:
1)如何确定最后一颗子树的根结点位置:
(数组长度-1) 是最后一个结点位置,而根据子结点是可以确定父
亲节点的,即:(数组长度-1-1)/2
2)如何确定下一颗子树根结点的位置:当前根结点-1(倒序)
其实就是去写每个子树的调整即可。 -
在代码实现时,每棵子树结束的位置是不一样的,为啥直接写个usedSize作为结束标志?
因为最后每课子树的下标其实都是>=usedSize的。 -
【向下调整】时间复杂度分析:(n为结点总数)
最坏的情况即从根一路比较到叶子,比较的次数为完全二叉树的高度,即时间复杂度为
-
注意:在调整以parent为根的二叉树时,必须要满足parent的左子树和右子树已经是堆了才可以向下调整。
2. 建堆
-
时间复杂度:
最坏情况是满二叉树,(每层的节点个数 * 该层移动的层数)之和,
最后就类似于等差数列 * 等比数列求和–用q乘以数列再相减进行计算
(即:差比数列求和 用错位相减法)
so:建堆的时间复杂度是:O(n) -
注意:对于二叉树而言
总结点个数n= 2^层数h-1
而每层节点个数最多:2^(层数h-1)
4. 堆的插入与删除
1. 堆的插入
- 插入之后仍然要保证原来的大根堆(小根堆)不变:
先插入到最后一棵子树的空的孩子结点处(考虑是否需要扩容),然后该节点直接与根结点进行比较,根据大小堆关系必要时互换,一旦产生互换就进行现在根节点与孩子节点的变换,不断重复,直至到达根结点。 - 注意每次交换父亲节点与孩子节点值后后,child和parent都要发生变化!!
什么时候停止循环:child==0 or parent<0 - 注意:插入是插入到最后,然后再慢慢进行【向上调整】!
2. 堆的删除
- 删除(出队):出的是优先级最高的元素;即:优先级队列的删除只能删除堆顶的元素。
- 堆顶元素与最后一个元素进行交换,然后usedSize就–(此时队列中有效长度范围内就不包含已经交换至最后的堆顶元素了)
此时只需要【向下调整】0下标开始的子树即可。
5. 用堆模拟实现优先级队列
// 优先级队列(堆)的模拟实现
import java.util.Arrays;
public class PriorityQueue {
public int[] elem;
public int usedSize;
// 构造方法:进行变量初始化
public PriorityQueue() {
this.elem = new int[10];
this.usedSize = 0; // 有效长度
}
// 初始化数组
public void initArray(int[]arr) {
this.elem = Arrays.copyOf(arr,arr.length); //将数组中元素拷贝给数组
this.usedSize = this.elem.length;
}
/**
* 建堆的时间复杂度:差比数列求和--O(N)
* 注意:从最后一个根节点依次向上的根结点遍历,以使得每棵子树都是大堆形式--使用根结点循环
* @param array
*/
public void createHeap(int[] array) {
// 注意:如果这里不传参时,usedSize就不用重新计算,直接使用initArray中已经初始化好的就行;
// 其实,就算传入数组参数也可以直接使用this.usedSize
int usedSize = array.length;
for (int parent=(usedSize-1)/2; parent>=0; parent--) {
shiftDown(parent,usedSize); // 注意结束条件是数组长度!
}
}
/**
* 向下调整(一次针对的是一棵子树)--大根堆
* 比较左右孩子结点大小,找到最大,然后与根结点进行比较,若果根结点小就进行交换--循环实现
* @param root 是每棵子树的根节点的下标
* @param len 是每棵子树调整结束的结束条件
* 向下调整的时间复杂度:O(logn)
*/
private void shiftDown(int root,int len) {
int child = 2*root+1; // 左孩子结点
while(child < len) { // 进入循环的条件其实是:好孩子结点要小于数组长度
// 判断左右孩子结点大小:
if((child+1<len) && (elem[child]<elem[child+1])) {
child++; // 赤裸裸的记录最大孩子结点的下标
}
// 来到这儿说明两种情况:只有左孩子or左孩子小于右孩子--两种情况都是child结点有最大值
// 判断最大子结点和父亲节点的大小 -- 进行交换swap
if(elem[child] > elem[root]) {
swap(elem,child,root);
// child root变化
root = child;
child = 2*root+1;
} else {
// 说明是:父亲节点大
break;
}
}
}
private void swap(int[] elem, int child, int root) {
int tmp = elem[child];
elem[child] = elem[root];
elem[root] = tmp;
}
/**
* 入队是先加在尾部 然后进行向上调整
* 入队:仍然要保持是大根堆
* @param val
*/
public void push(int val) {
if(isFull()) {
// 进行扩容
this.elem = Arrays.copyOf(elem,2*elem.length);
}
// 要么扩容成功,要么未满 就开始进行尾插
this.elem[this.usedSize] = val;
this.usedSize++; // 要注意++!!
// 向上调整:
shiftUp(this.usedSize-1); // 因为之前已经usedSize++l,此时有效下标需要--
}
// 向上调整:也是孩子结点与父亲节点比较
private void shiftUp(int child) {
int parent = (child-1)/2;
// 注意调整条件:child>0
while(child>0) {
// 直接与父亲节点进行比较就行,不需要再与另一个孩子结点进行比较,因为其他已经是有序的大根堆
if(this.elem[parent] < this.elem[child]) {
swap(this.elem,child,parent);
// 注意交换后一定要进行变量的变化
child = parent;
parent = (child-1)/2;
} else {
break;
}
}
}
public boolean isFull() {
return this.usedSize==this.elem.length;
}
/**
* 出队【删除】:每次删除的都是优先级高的元素!! 即:删除的是堆顶元素!
* 仍然要保持是大根堆
* 把堆顶数据域最后一个数据进行交换,然后进行向下调整成大根堆
*/
public void pollHeap() {
if(isEmpty()) {
return;
}
int old = this.elem[0];
swap(this.elem,this.usedSize-1,0);
this.usedSize--; // 此时有效数据中被换到最后的数据就不被包含在内
// 注意该方法其实是在<usdSize时进行变换,所以不需要-1!!!
//shiftDown(0,this.usedSize-1); // 向下调整
shiftDown(0,this.usedSize);
System.out.println(old);
}
public boolean isEmpty() {
return this.usedSize == 0;
}
/**
* 获取堆顶元素
* @return
*/
public int peekHeap() {
return this.elem[0];
}
}
6. 常见习题
- 下列关键字序列为堆的是:()
A: 100,60,70,50,32,65
B: 60,70,65,50,32,100
C: 65,100,70,32,50,60
D: 70,65,100,32,50,60
E: 32,50,100,70,65,60
F: 50,100,70,65,60,32
思路:
此题没有指明大小堆,那就都有可能; 但是该关键字系列其实是完全二叉树层序遍历的结果,所以其实是可以确定的。
然后该题需要复习大小根堆的定义。
- 已知小根堆为8,15,10,21,34,16,12,删除关键字8之后需重建堆,在此过程中,关键字之间的比较次数是()
A: 1 B: 2 C: 3 D: 4
思路:
小根堆:根节点比孩子节点小; 删除关键字之后依旧要保持原来的小根堆不变。
注意:出队出的是优先级最高的堆顶元素,堆顶元素与最后一个元素交换,然后usedSize–,【向下调整:左右孩子节点的大小比较,孩子节点与父亲节点的比较】
注意:大小堆的定义–根结点比左右子树都大(小),但是左右子树结点
大小没关系
题解:
12是最后一个节点,12与8进行交换,进行【向下调整】:15与10比较(①),10更小,10与12进行比较(②),10小,10与12进行交换;16与12进行比较(③),12小,不交换。
- 一组记录排序码为(5 11 7 2 3 17),则利用堆排序方法建立的初始堆为()
A: (11 5 7 2 3 17)
B: (11 5 7 2 17 3)
C: (17 11 7 2 3 5)
D: (17 11 7 5 3 2)
E: (17 7 11 3 5 2)
F: (17 7 11 3 2 5)
思路:
堆排序方法:
(根节点与最后一个节点交换,向下调整;重复这两个步骤 最后一个节点不断往前推进)
public void heapSort() {
int end = this.usedSize-1;
// 循环变换
while(end>0) {
// 进行交换
swap(this.array,0,end);
// 先进行【向下调整】,需要到end,因为比较时本来就不包含边界,所以先不进行—-
shiftDown(0,end);
end--;
}
}
题解:
根节点与最后一个节点交换一下就行。
写题时,堆排序默认是升序的(即:大根堆),如果不行再使用降序来做
- 最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A: [3,2,5,7,4,6,8]
B: [2,3,5,7,4,6,8]
C: [2,3,4,5,7,8,6]
D: [2,3,4,5,6,7,8]
思路:
删除(出队):只能是堆顶元素,堆顶元素与最后一个元素交换,usedSize–,然后比较左右子结点的大小,然后拿最小值与根结点进行比较与交换,重复每棵子树即可。
答案:
1.A
2.C
3.C
4.C
三、 常用接口介绍
1. PriorityQueue的特性
- Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的。本文重点是PriorityQueue。
- PriorityQueue的底层默认是小根堆!
- 接口关系图:

- 关于PriorityQueue的使用要注意:
1)使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
2) PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出ClassCastException异常
3) 不能插入null对象,否则会抛出NullPointerException
4) 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
5) 插入和删除元素的时间复杂度为:O(logN)
6) PriorityQueue底层使用了堆数据结构
7) PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
2. PriorityQueue常用接口介绍
- 此处列出了PriorityQueue中常见的几种构造方式:

- 注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器。
用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可;或者实现Comparable接口,重写compareTo方法。 - 插入/删除/获取优先级最高的元素:

- 在JDK 1.8中,PriorityQueue的扩容方式:
如果容量小于64时,是按照oldCapacity的2倍方式扩容的
如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
- 小结:
1) java的优先级队列底层数组默认大小是11
2) 当对优先级队列指定大小的时候,不要给<=0的容量,一定要>1,否则会抛出异常。
3) 比较器Comparator是需要自己传入的,不传入就会默认这个变量是可比较的;默认实现的是Comparable接口。
4) 当使用比较器Comparator的对象作为参数传入时,不管走的哪个方法,数组的容量都是被赋予的。
5) offer是如何维护的?如何保证小根堆的呢?
其实就是在重写compare方法(Compara比较器)时,如果o1-o2就是默认的小堆,o2-o1则是大堆;因为一旦两个相减<0就进行就进行交换。
(o1就是当前传入的对象!!)文章来源:https://www.toymoban.com/news/detail-614275.html
四、堆的应用
1. PriorityQueue的模拟实现
用堆作为底层结构封装优先级队列。文章来源地址https://www.toymoban.com/news/detail-614275.html
2. 堆排序
- 在原数组本身上进行堆排序:
从小到大排序建立大根堆:
堆顶元素与最后一个结点进行交换,然后进行【向下】调整(左右孩子最大值,然后与堆顶元素进行交换);不断重复
即:每次让0下标的值与end下标的值进行交换,【向下调整】调整;当end==0就结束 - 大小根堆的堆排序方法都一样,交换+【向下调整】
- 源代码在习题中
- 写题时,堆排序默认是升序的(即:大根堆),如果不行再使用降序来做
3.topK问题
- top-k应用:求前k个最大(建小根堆)/最小、求第k大(建小根堆–堆顶元素)/小。
- top-k问题:
假设:100个数据中,找前k个最大(最小) - 方法一:将数据放入大根堆(小根堆)中–堆顶元素就是max(min),然后出k次–每出一次都会进行调整成大小根堆
(注意在建优先级队列时直接传入比较器Comparator)和重写compare方法)
缺陷:如果堆较大的话,时间复杂度会较高:O(N*log2N) - 优化方法:如果是找前k个最大的
先建立一个k大小的小根堆(注意是小根堆)来存储数组的前k个元素,然后从k下标开始依次遍历,与堆顶元素进行比较,如果堆顶元素<当前元素,那么堆顶元素一定不是所要找的前k个最大之一,所以将堆顶元素进行出堆poll(堆顶元素与最后一个元素互换),然后调整成小根堆,再将当前元素放置最后一个元素位置,再调整小根堆offer。循环遍历。
时间复杂度:O(N*log2K) (N是结点个数,K是前K个) - 代码:(以 找前k个最大值为例)
// 方法一:放入相同堆中,出k次
public void topK1(int[] arr,int k) {
if(k==0) {
return;
}
// 注意传入比较器
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1; // 大根堆
}
});
// 放入堆中
for (int i = 0; i < arr.length; i++) {
priorityQueue.offer(arr[i]);
}
// 出k次
for (int i = 0; i < k; i++) {
System.out.print(priorityQueue.poll() + " ");
}
}
// 方法二:k大小的相反堆 + 遍历比较出堆
public int[] topK2(int[] arr, int k) {
// 建立一个数组用于存储所找的前k个元素
int[] ret = new int[k];
if (k==0) {
return ret;
}
// 同样传入比较器:但是此时找小根堆
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(k,new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2; // 小根堆
}
});
// 建立k大小的小根堆(数组元素进行存入)
for (int i = 0; i < arr.length; i++) {
if(priorityQueue.size()<k) {
priorityQueue.offer(arr[i]);
} else {
// 说明已经建好了k堆,要进行比较变换
// 获取栈顶元素
int top = priorityQueue.peek();
// 栈顶元素与数组遍历的i下标的元素去比较大小
// 找前k个最大的
if(arr[i] > top) {
// 要是新元素大,则说明堆顶元素不包含在内
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
}
// 然后进行出k个元素:
for (int i = 0; i < k; i++) {
int val = priorityQueue.poll();
ret[i] = val;
}
return ret;
}
总结
- 优先级队列:底层是堆(完全二叉树的层序遍历)
- 优先级队列模拟实现
- 优先级队列常用方法
- 优先级队列应用:堆排序、topK问题等。
到了这里,关于【JAVA】优先级队列(堆)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!