初识 RabbitMQ
- 核心思想:接收并转发消息。可以把它想象成一个邮局。

producer:生产者
queue:队列
consumer:消费者 - 什么是消息队列
MQ(Message Queue):本质是队列,FIFO先入先出,只不过队列中存放的内容是 message 而已,还是一种跨进程的通信机制,用于上下游传递消息。在互联网架构中,MQ是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通信服务。使用了MQ之后,消息发送上游只需要依赖MQ,不用依赖其他服务。

消息队列起到的作用主要为:允许入列、存储消息及消息出列。
-
消息队列的特性
- 业务无关
- FIFO:先进先出
- 容灾:可以把消息进行持久化,即便未发出去或发送消息的过程突然断电、服务宕机,等恢复服务后把之前的消息重新发送,保证了可靠性。
- 性能:消息队列的吞吐量上去之后,整个系统内部通信效率也会提高。
-
为什么要使用消息队列
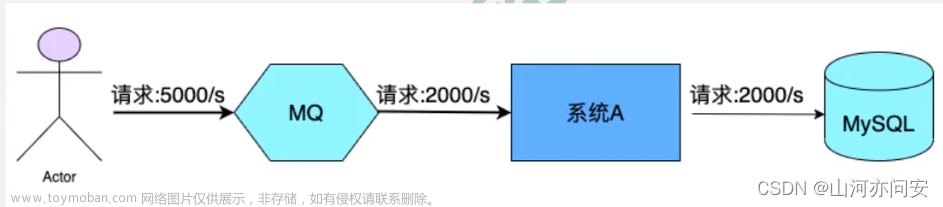
- 系统解耦:当系统A发送一个消息到多个系统,中间使用消息队列后,不用每个系统都调用一遍,减少处理时间,提高维护性。
- 异步调用:可以通过消息,异步调用多个业务模块,大大提升整体程序的运行速度。
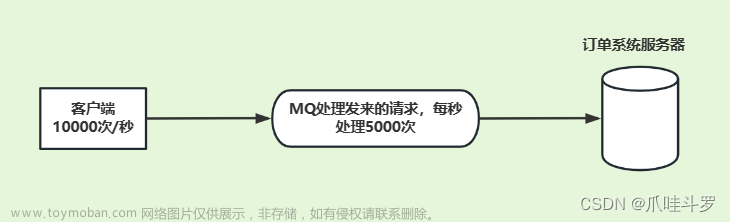
- 流量削峰:当系统出现流量高峰时,可以把请求放到消息队列里,再以服务器能处理的速度发给各个系统,从而减少不必要的物理资源扩充。
-
MQ的分类
- ActiveMQ
- 优点:单击吞吐量万级,时效性 ms 级,可用性高,基于主从架构实现高可用性,较低概率丢失数据。
- 缺点:官方社区现在对 ActiveMQ 5.x 维护越来越少,高吞吐量场景较少使用。
- Kafka
- 大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开 Kafka,为大数据而生的消息中间件,支持百万级 TPS 的吞吐量,在数据采集、传输、存储的过程中发挥着举足轻重的作用。
- 优点:性能卓越,单击写入 TPS 约在百万条/秒,最大的优点就是吞吐量高。时效性 ms 级,可用性非常高。kafka 是分布式的,一个数据多个副本,少量机器宕机不会丢失数据,不会导致不可用。消费者采用 pull 方式获取消息,消息有序,通过控制能够保证所有消息被消费且仅被消费一次。有优秀的第三方Kafka Web 管理界面 Kafka-Manager。在日志领域比较成熟,被多家公司和多个开源项目使用。功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用。
- 缺点:Kafka 单击超过 64 个队列/分区, Load 会发生明显的飙高现象,队列越多,load 越高,发送消息响应时间变长,使用短轮询方式,实时性能取决于轮询间隔时间,消费失败不支持重试;支持消息顺序,但是一台代理宕机后,就会产生消息乱序,社区更新较慢。
- RocketMQ
- RocketMQ 出自阿里巴巴的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进。被阿里巴巴吧广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
- 优点:单击吞吐量十万级,可用性非常高,分布式架构,消息可以做到 0 丢失,MQ功能较为完善,扩展性好,支持10亿级别的消息堆积,不会因为堆积导致性能下降,源码是Java,可以自己阅读源码,定制自己公司的 MQ。
- 缺点:支持的客户端语言不多,目前是Java及C++,其中C++不成熟;社区活跃度一般,没有在 MQ 核心中去实现 JMS 等接口,有些系统要迁移需要修改大量代码。
- RabbitMQ
- 2007年发布,是一个在AMQP(Advanced Message Queuing Protocol 高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
- 优点:由于 Erlang 语言的高并发特性,性能较好;吞吐量到万级,MQ 功能比较完备,健壮、稳定、易用、跨平台,支持多种语言,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript等。支持AJAX,文档齐全,开源提供的管理界面非常棒,用起来很好用,社区活跃度高,更新频率相当高。
- 缺点:商业版需要收费,学习成本较高。
- ActiveMQ
-
MQ 的选择
- Kafka:大量数据的互联网服务的数据收集业务,有日志采集功能,首选 Kafka。
- RocketMQ:金融互联网领域,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰等。RoketMQ 在稳定性上更值得信赖,在阿里双11经历了多次考验。
- RabbitMQ:结合 Erlang语言本身的并发优势,性能好,时效性微秒级,社区活跃度也比较高,管理界面用起来十分方便。如果数据量没那么大,中小型公司优先选择功能比较完备的 RabbitMQ。
-
RabbitMQ 核心概念

四大核心概念:生产者 Publisher、交换机 Exchage、队列 Queue、消费者Consumer。
- Broker:接受和分发消息的应用,RabbitMQ Server就是 Message Broker
- connection:publisher / consumer 与 broker 之间的 TCP 连接
- Channel:信道,在connection 内部建立的逻辑连接,每个connection可以包含多个信道,每次发消息只会占用一个信道。几乎所有的操作都在信道上进行。Channel 极大减少了操作系统建立 TCP connection 的开销。
- message:消息,由 properties 和 body 组成,properties 为对消息进行额外的修饰,包括优先级、队列延迟、消息其他属性等;body 为消息实体。
- Virtual host:虚拟主机,顶层隔离。出于多租户和安全因素设计的,在Broker里可以包含多个 Virtual host ,而一个 Virtual host 里又可以包含多个 Exchange 和 Queue。 同一个虚拟主机下,不能有重复的交换机和 queue。
- Exchange:交换机,接收生产者的消息的,然后根据指定的路由器去把消息转发到所绑定的队列上。
- binding:绑定交换机和队列
- routing key:路由键,路由规则,虚拟机可以用它来确定这个消息如何进行一个路由。
- queue:队列,消费者只需要监听队列来消费消息,不需要关注消息来自哪个Exchange
- Exchange 和 Message Queue 存在着绑定的关系,一个 Exchange 可以绑定多个消息对类。
-
RabbitMQ 六大模式

-
消息流转过程

RabbitMQ 的安装和启动
- 下载安装包
先通过 uname -a 命令查询 Linux 版本,然后下载对应的安装包
然后根据 Linux 版本,在 PackageCloud 查看RabbitMQ与Erlang 支持的版本,及官网https://www.rabbitmq.com/查看RabbitMQ与Erlang对应版本


结合上面,选择并下载RabbitMQ 3.10.0 及 Erlang 23.3.x 版本。

下载完后,通过如 SecureFX 文件上传工具上传到 Linux 服务器上
- 安装
安装 Erlang
rpm -ivh erlang-23.3.4.11-1.el7.x86_64.rpm
安装 RabbitMQ(yum命令需要Linux服务器联网)
yum install rabbitmq-server-3.10.0-1.el7.noarch.rpm
- 常用命令
添加开机启动
chkconfig rabbitmq-server on
启动服务
service rabbitmq-server start
查看服务状态
service rabbitmq-server status
如下图,如果是active (running)则启动完成(activating 为正在启动中,稍微等待重新查看服务状态)
停止服务
service rabbitmq-server stop
开启 web 管理插件(需先停止服务)
rabbitmq-plugins enable rabbitmq_management
如出现如下错误,
将主机名配置修改和上图显式的名称vim /etc/hosts
然后再执行,成功后启动服务
防火墙开发15672端口
firewall-cmd --zone=public --permanent --add-port=15672/tcp
firewall-cmd --reload
浏览器访问
- 添加新用户
创建账号
rabbitmqctl add_user admin 123456
设置用户角色
rabbitmqctl set_user_tags admin administrator
设置用户权限
set_permissions [-p ]
rabbitmqctl set_permissions -p “/” admin “.*” “.*” “.*”
用户admin具有 “/” 这个 virtual host 中所有资源的配置、写、读权限
当前用户和角色
rabbitmqctl list_users
Hello World
简单队列模式
打开IDEA,创建一个空项目
然创建一个Module

在pom.xml文件添加依赖
<!--指定jdk编译版本-->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<!--rabbitmq依赖客户端-->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<!--操作文件流的一个依赖-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
- 消息生产者
package com.ql.rabbitmq.one;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 生产者:发消息
*/
public class Producer {
//队列名称
public static final String QUEUE_NAME = "hello";
//发消息
public static void main(String[] args) throws IOException, TimeoutException {
//创建一个连接工厂
ConnectionFactory factory = new ConnectionFactory();
//工厂IP 连接RabbitMQ的队列
factory.setHost("192.168.1.130");
//factory.setPort(15672);
//用户名
factory.setUsername("admin");
//密码
factory.setPassword("123456");
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 生成队列
* 1.队列名称
* 2.队列里面的消息是否持久化(磁盘) 默认消息存储在内存中
* 3.该队列是否只供一个消费者进行消费 是否进行消息共享,true可以多个消费者消费, false:只能一个消费者消费
* 4.是否自动删除 最后一个消费者端开连接以后 该队列是否自动删除 true自动删除 false不自动删除
* 5.其他参数
*/
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//发消息
String message = "hello world";//初次使用
/**
* 发送一个消息
* 1.发送到哪个交换机
* 2.路由的Key值是哪个 本次是队列的名称
* 3.其他参数信息
* 4.发送消息的消息体
*/
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("消息发送完毕");
}
}
运行测试(注,Linux放开5672端口),看到已经有一条消息。
- 消息消费者
package com.ql.rabbitmq.one;
import com.rabbitmq.client.*;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 消费者 接收消息的
*/
public class Consumer {
//队列的名称
public static final String QUEUE_NAME = "hello";
//接收消息
public static void main(String[] args) throws IOException, TimeoutException {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.1.130");
factory.setUsername("admin");
factory.setPassword("123456");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明 接收消息
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println(new String(message.getBody()));
};
//取消消息时的回调
CancelCallback cancelCallback = consumerTag -> {
System.out.println("消息消费被中断");
};
/**
* 消费者消费消息
* 1.消费哪个队列
* 2.消费成功之后是否要自动应答 true 代表的自动应答 false 代表手动应答
* 3.消费者成功消费的回调
* 4.消费者取消消费的回调
*/
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
Work Queues
工作队列模式(又称任务队列)的主要思想是,当有资源密集型任务,把任务封装为消息,并将其发送到队列,由一个或多个工作线程将任务轮询弹出并执行。
轮询分发消息
- 抽取连接工厂工具类
package com.ql.rabbitmq.utils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 此类为连接工厂创建信道的工具类
*/
public class RabbitMqUtils {
//得到一个连接的channel
public static Channel getChannel() throws IOException, TimeoutException {
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.1.130");
factory.setUsername("admin");
factory.setPassword("123456");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
return channel;
}
}
- 工作线程代码
package com.ql.rabbitmq.two;
import com.ql.rabbitmq.utils.RabbitMqUtils;
import com.rabbitmq.client.CancelCallback;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 这是一个工作线程(相当于之前消费者)
*/
public class Worker01 {
//队列的名称
public static final String QUEUE_NAME = "hello";
//接受消息
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
DeliverCallback deliverCallback = (consumerTag, message)->{
System.out.println("接收到的消息:"+new String(message.getBody()));
};
CancelCallback cancelCallback = (consumerTag)->{
System.out.println(consumerTag+"消费者取消消费接口的回调");
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
-
启动2个工作线程
先启动一个

然后IDEA运行配置里开启允许多个实例,再运行


-
生产者代码
package com.ql.rabbitmq.two;
import com.ql.rabbitmq.utils.RabbitMqUtils;
import com.rabbitmq.client.Channel;
import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;
/**
* 生产者 发送大量的消息
*/
public class Task01 {
//队列的名称
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
//队列的声明
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//从控制台当中接受信息
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println("发送消息完成:"+ message);
}
}
}
运行测试


消息应答
消费者完成一个任务可能需要一段时间,如果其中一个消费者处理一个长的任务并仅完成了部分后突然挂掉了,会发生什么情况?RabbitMQ 一旦向消费者传递一条消息,便立即将该消息标记为删除,这种情况下,突然有个消息挂掉了,将会丢失正在处理的消息。
为了保证消息在发送过程中不丢失,RabbitMQ 引入消息应答机制,消息应答就是:消费者在接收到消息并且处理该消息之后,告诉 RabbitMQ 它已经处理了,RabbitMQ 可以把该消息删除了。
-
自动应答
消息发送后立即被认为已经发送成功,这种模式需要在高吞吐量和数据传输安全性方面做权衡。因为这种模式如果消息在接收到之前,消费者出现连接或 channel 关闭,消息就会丢失。另一方面,这种模式消费者没有对传递的信息数量进行限制,这样有可能发生消息的积压导致内存溢出等。所以这种模式仅适合在消费者可以高效并以某种速率能够处理这些消息的情况下使用。 -
手动应答
- Channel.basicAck(用于肯定确认)
RabbitMQ 已知道该消息并且成功的处理消息,可以将其丢弃了 - Channel.basicNack(用于否定确认)
- Channel.basicRejeck(用于否定确认)
与 Channel.basicNack 少一个参数
不处理该消息了直接拒绝,可以将其丢弃
- Channel.basicAck(用于肯定确认)
-
Multiple 批量应答
手动应答的好处是可以批量应答并且减少网络拥堵
Channel.basicAck(deliveryTag, Multiple)
Multiple:
true 代表批量应答 channel 上未应答的消息。比如说 channel 上有传送tag的消息 5、6、7、8 当前 tag 是 8 ,那么此时 5-8 的消息都会被确认收到消息应答
false 不批量应答(强烈推荐)。上面情形,只会应答 8 的消息。 -
消息自动重新入队
如果消费者由于某些原因失去连接(其通道已关闭、连接已关闭或TCP 连接丢失),导致消息未发送ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。
-
消息手动应答代码
生产者Task2
package com.ql.rabbitmq.three;
import com.ql.rabbitmq.utils.RabbitMqUtils;
import com.rabbitmq.client.Channel;
import java.io.IOException;
import java.util.Scanner;
import java.util.concurrent.TimeoutException;
/**
* 消息在手动应答时不丢失、放回队列中重新消费
*/
public class Task2 {
//队列名称
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
//声明队列
channel.queueDeclare(TASK_QUEUE_NAME, false, false, false, null);
//从控制台中输入信息
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("", TASK_QUEUE_NAME, null, message.getBytes("UTF-8"));
System.out.println("生产者发出消息:"+message);
}
}
}
消费者Work03
package com.ql.rabbitmq.three;
import com.ql.rabbitmq.utils.RabbitMqUtils;
import com.ql.rabbitmq.utils.SleepUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 消息在手动应答时不丢失,放回队列重新消费
*/
public class Work03 {
//队列名称
public static final String TASK_QUEUE_NAME = "ack_queue";
//接收消息
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
System.out.println("C1等待接收消息处理时间较短");
DeliverCallback deliverCallback = (consumerTag , message)->{
//沉睡1S
SleepUtils.sleep(1);
System.out.println("接收到的消息:"+new String(message.getBody(), "UTF-8"));
//手动应答
/**
* 1.消息的标记 tag
* 2.是否批量应答
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(), false);
};
//采用手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, (consumerTag ->{
System.out.println(consumerTag+"消费者取消消费接口回调");
}));
}
}
消费者Work04
package com.ql.rabbitmq.three;
import com.ql.rabbitmq.utils.RabbitMqUtils;
import com.ql.rabbitmq.utils.SleepUtils;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DeliverCallback;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 消息在手动应答时不丢失,放回队列重新消费
*/
public class Work04 {
//队列名称
public static final String TASK_QUEUE_NAME = "ack_queue";
//接收消息
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
System.out.println("C2等待接收消息处理时间较长");
DeliverCallback deliverCallback = (consumerTag , message)->{
//沉睡30S
SleepUtils.sleep(30);
System.out.println("接收到的消息:"+new String(message.getBody(), "UTF-8"));
//手动应答
/**
* 1.消息的标记 tag
* 2.是否批量应答
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(), false);
};
//采用手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, (consumerTag ->{
System.out.println(consumerTag+"消费者取消消费接口回调");
}));
}
}
睡眠工具类文章来源:https://www.toymoban.com/news/detail-614414.html
public class SleepUtils {
public static void sleep(int second){
try {
Thread.sleep(1000*second);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 手动应答效果演示
依次启动Task2、Work03、Work04,然后Task2发送两个消息
此时Work03 已收到第一条消息
Work04 收到消息后沉睡30s之后才打印并手动应答,我们在应答前停止Work04
停止Work04 后,第二条消息就会被Work03 重新消费
RabbitMQ 持久化
默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它忽视队列和消息。为了确保消息不会丢失,我们需要将队列和消息都标记为持久化。文章来源地址https://www.toymoban.com/news/detail-614414.html
- 队列实现持久化
上面创建的队列都是非持久化的,RabbitMQ 如果重启的话,该队列就会被删除。如果要队列实现持久化,需要在声明队列的时候把 durable 参数设置为持久化

注:如果之前声明的队列不是持久化的,需要把原先队列先删除,否则出现如下错误
在管理页面先删除队列,重新启动Task2
刷新管理页面,该队列就会多一个D 的持久化标识。
- 消息持久化
修改生产者代码
在发布消息时,添加 MessageProperties.PERSISTENT_TEXT_PLAIN 属性
将消息标记为持久化并不能完全保证消息不丢失,尽管它告诉 RabbitMQ 将消息保存到磁盘,但是这里依然存在消息刚准备存储在磁盘的时候,服务关闭等,此时并没有真正写入磁盘。持久化保证并不强,但是对于简单任务队列是足够了,如果需要更强有力的持久化策略,参考后面发布确认知识点。 - 不公平分发
轮询分发的缺点:当有两个消费者,其中一个处理任务速度非常快,另一个速度很慢,这个时候还用轮询分发,速度快的消费者大部分时间处于空闲状态,而另一个却在一直在处理任务。
为了避免这种情况,我们可以在消费者接收消息的时候,设置参数 channel.basicQos(1) 实现不公平分发。(如果设置为0 则轮询分发)
设置完Work03、Work04 后,重启测试


- 预取值
RabbitMQ的信道上肯定不止只有一个消息,因此这里就存在一个未确认的消息缓冲区,因此希望开发人员能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。这个时候就可以通过使用 channel.basicQos() 方法设置“预取计数”值来完成的。该值定义通道上允许的未确认消息的最大数量。一旦数量达到配置的数量,RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认。
上面的不公平分发,相当于安把预取值设置成了1。
我把上面Work03 、Work04 信道预取值都改成5,然后重启测试
发送多个消息
通过管理界面可看到信道里堆积的消息条数。
到了这里,关于消息队列(一)-- RabbitMQ入门(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!