前言
前文主要着重介绍了ise当中的FFT IP核的使用方法,本文将介绍Vivado中的FFT IP核使用方法。并且设计一段仿真代码,进行波形仿真,查看输出结果。
提示:以下是本篇文章正文内容
一、Vivado的FFT使用详解
版本号:Fast Fourier Transform v9.1
Xilinx LogiCORE IP快速傅里叶变换(FFT)核心实现了Cooley-Tukey FFT算法,这是一种计算离散傅里叶变换(DFT)的高效计算方法。该IP核使用AXI4总线协议输出数据,通过ready和valid信号实现上下游模块之间的握手。
输入数据按自然顺序显示,输出数据可以按自然顺序显示,也可以按位/数字倒序输出。FFT核接收复杂的数据样本,但可以通过将所有虚数输入设置位零来对实部数据进行转换。由于有限字长效应,在转换过程中,引入了噪声,导致输出数据不是完全的对称,故建议在执行实值FFT时,使用输出数据的后半部分(N/2+1,N)。
1、IP核配置界面介绍
-
Configuration Tab:配置选项卡

- 组件名称:要实例化的核心组件的名称。名称必须以字母开头,由a ~ z、a ~ z、0 ~ 9、_组成。
- 选项卡通道数:选择1 ~ 12的通道数。多通道操作可用于三种突发I/O架构。
- 变换长度:选择所需的点大小。从8到65536的2的所有幂都是可用的。
- 实现选项:选择一个实现选项,如体系结构选项中所述。流水线流I/O、Radix-2 Burst I/O和Radix-2 Lite Burst I/O架构支持点大小为8到65536。Radix-4 Burst I/O架构支持大小为64到65536的点。自动选择选择满足指定目标数据吞吐量的最小实现,前提是在FPGA上实现FFT核心时实现指定的目标时钟频率。目标时钟频率和目标数据吞吐量只用于自动选择一个实现和计算延迟。核心不保证运行在指定的目标时钟频率或目标数据吞吐量。
- 转换长度选项:选择运行时可配置的转换长度。当转换长度不能在运行时配置时,核心使用更少的逻辑资源并具有更快的最大时钟速度。
-
Implementation Tab:实现选项卡

- 数据格式:选择输入和输出的数据样本是定点格式,还是IEEE-754单精度(32位)浮点格式。当核心处于多通道配置时,浮点格式不可用。
- 精度选项:输入数据和相位因数可以独立配置为8至34位的宽度,包括。当“数据格式”为“浮点型”时,输入数据宽度固定为32位,相位因数宽度可根据所需的噪声性能和可用资源设置为24位或25位。
- 缩放选项:有三个选项,适用于所有架构:未缩放-所有的整数位增长被携带到输出。这可以使用更多的FPGA资源。缩放-一个用户定义的缩放计划决定了数据如何在FFT阶段之间缩放。块浮点—核心决定需要多大程度的缩放才能充分利用可用的动态范围,并将缩放因子报告为块指数。
- 控制信号:时钟使能(aclken)和同步清除(aresetn)是可选引脚。如果同时勾选“同步清除”,则会覆盖“时钟启用”。如果不选择一个选项,可以节省一些逻辑资源,并可能获得更高的时钟频率。
- 可选输出字段:XK_INDEX是数据输出通道中的可选字段。OVFLO是数据输出通道和状态通道中的可选字段。
- 节流方案:在性能和数据定时需求之间进行权衡。实时模式通常提供更小、更快的设计,但在必须提供和使用数据时有严格的限制。非实时模式没有这样的限制,但设计可能更大、更慢。更多细节请参见控制FFT核心。
- 舍入模式:在蝴蝶的输出时,需要修剪数据路径中的lbs。这些位可以使用收敛舍入截断或舍入,这是一种无偏置舍入方案。当一个数的小数部分正好等于1 / 2时,如果数是奇数,收敛四舍五入;如果数是偶数,收敛四舍五入。收敛舍入可以用来避免直流电偏置,否则将引入截断后的蝴蝶阶段。选择此选项会增加切片使用量,并由于额外的延迟而导致转换时间的小幅增加。
- 输出顺序:输出数据选择位/数字反转顺序或自然顺序。基于Radix-2的架构(流水线流I/O, Radix-2突发I/O和Radix-2 Lite突发I/O)提供位反转排序,而基于Radix-4的架构(Radix-4突发I/O)提供位反转排序。对于流水线流I/O架构,选择自然顺序输出顺序会增加核心使用的内存。对于突发I/O架构,选择自然阶输出会增加整体转换时间,因为需要一个单独的卸载阶段。如果输出顺序是自然顺序,可以选择循环前缀插入。循环前缀插入可用于所有体系结构,通常用于OFDM无线通信系统。
-
Detailed Implementation Tab:详细实现选项卡

- 内存选项:数据和相位因数(突发I/O架构):对于突发I/O架构,块RAM或分布式RAM都可以用于数据和相位因数存储。数据和相位因子存储可以在分布式RAM中存储所有的点大小,包括1024点。
- 数据和相位因子(流水线流I/O):在流水线流I/O解决方案中,数据可以部分存储在块RAM中,部分存储在分布式RAM中。每个管道阶段,从输入端计数,使用更小的数据和相位因子存储器比前阶段。您可以选择使用块RAM进行数据和相位因子存储的管道阶段的数量。后期阶段使用分布式RAM。IDE上显示的默认值在这两者之间提供了很好的平衡。如果输出顺序是自然顺序,用于重排序缓冲区的内存可以是块RAM或分布式RAM。对于点大小小于或等于1024的点,重排序缓冲区可以使用分布式RAM。当流水线流I/O架构选择块浮点时,自然顺序和位倒序输出数据需要RAM缓冲区。在这种情况下,重排序缓冲区选项仍然可用,对于所有小于2048的点,都可以选择分布式RAM。
- 混合存储:数据,相位因子,或重新排序缓冲区记忆存储在块内存,如果内存的大小大于一块内存,内存可以由一个混合块公羊和分布式内存,在大多数的数据存储在块公羊和几位剩下存储在分布式RAM。这种混合内存是完全由多个块ram构建内存的替代方案。它减少了块RAM计数,但代价是增加了所使用的片的数量。只有当块RAM用于一个或多个内存,并且混合内存实现所需的片数低于每个内存256个lut的内部阈值时,混合内存才可用。如果满足这些条件,混合存储器就可用,可以选择。
- 优化选项:Complex multiplier:有三种选项可用于定制复杂multiplier的实现:—使用CLB逻辑:所有复杂multiplier都使用切片逻辑构造。适用于性能要求较低的目标应用程序或目标设备的DSP片较少。-使用3-乘法器结构(资源优化):所有复杂的乘法器使用3个实乘,5个加减结构,其中乘法器使用DSP Slices。这减少了DSP Slice计数,但使用了一些Slice逻辑。这种结构可以利用DSP片预加器减少或消除对额外片逻辑的需要,提高性能。-使用4乘法器结构(性能优化):所有复杂乘法器使用4实乘,2加/减结构,利用DSP片。这种结构产生了最高的时钟性能,但牺牲了更专用的乘数。在带有DSP片的设备中,加/减运算是在DSP片内实现的。注意:核心可能会在内部覆盖复杂的乘法器实现,以确保使用最少的DSP片,而不会影响性能。由于这个原因,一些核心配置在3倍增器和4倍增器选项之间切换时,DSP Slice的使用可能没有区别。但是,如果选择使用CLB逻辑,则始终使用切片逻辑。
- 蝶形算法:有两个选项可用于定制蝴蝶实现:-使用CLB逻辑:所有蝴蝶阶段都使用切片逻辑构造。—使用XtremeDSP Slices:对于带有DSP Slices的设备,此选项强制所有蝶形阶段都使用DSP Slices中的加法器/减法器实现。
2、IP核主要端口说明
| 名称 | 方向 | 说明 |
|---|---|---|
| aclk | in | 时钟信号,上升沿采样,输入范围1MHz~100MHz |
| aclken | in | 时钟使能,高电平有效 |
| aresetn | in | 同步清零,低有效 |
| s_axis_config_tdata | in | 配置通道数据输入,承载配置信息:CP_LEN, FWD/INV, NFFT和SCALE_SCH。 |
| s_axis_config_tvalid | in | 配置通道valid信号 |
| s_axis_config_tready | out | 配置通道ready信号 |
| s_axis_data_tdata | in | 数据输入通道,承载采样数据:XN_RE、XN_IM |
| s_axis_data_tvalid | in | 数据输入通道valid信号 |
| s_axis_data_tready | out | 数据输入通道ready信号 |
| s_axis_data_tlast | in | 数据输入通道last信号 |
| m_axis_data_tdata | out | 数据输出通道,承载IP核转换数据:XK_RE、XK_IM |
| m_axis_data_tuser | out | 数据输出通道,承载附加的预采样信息:XK_INDEX,OVFLO,BLK_EXP |
| m_axis_data_tvalid | out | 数据输出通道valid信号 |
| m_axis_data_tlast | out | 数据输出通道last信号 |
| m_axis_data_tready | in | 数据输出通道ready信号 |
| event_frame_started | out | IP核开始处理新帧时发出该信号,持续一个时钟周期 |
| event_tlast_unexpected | out | 当s_axis_data_tlast插入位置不对时,该信号输出,持续一个时钟周期,如果出现多个last信号,也会对应插入多个 |
| event_tlast_missing | out | 当IP核输入的数据数目大于核设置的最大转换点数时,会发出该信号,持续一个时钟周期 |
| event_data_in_channel_halt | out | 当信号在FFT数据输入需要接收数据时,而没有数据可用时,会插入此信号,直到有新的数据插入时,该信号才会变为低电平 |
3、IP核时序说明
数据在AXI4-Stream通道中的传输如图所示。TVALID由通道的源端(主端)驱动,而TREADY由接收端(从端)驱动。TVALID表示有效负载字段(TDATA、TUSER和TLAST)的值是有效的。“TREADY”表示从机已经准备好接收数据。当TVALID和TREADY在一个循环中都为真时,就会发生转移。主、从分别为下一次传输设置TVALID和TREADY。
当选择流水线流I/O且不使用循环前缀时,核心可以将帧的加载与之前帧的处理和卸载重叠。如果上游主程序在前一帧的最后一个符号之后立即为新帧提供第一个符号,那么核心程序立即开始加载它。下图显示了通道流架构中背对背帧的一般时序。
注意,在加载帧和该帧的处理数据可用之间有一个延迟。这个延迟取决于Vivado IDE中为参数化核心所选择的选项。然而,当延迟过去后,经过处理的帧将背靠背出现。
二、FFT核使用例程
1.工程建立
程序运行环境:
- Vivado 2020.2
- ModelSim SE-64 2020.4
利用Vivado建立一个工程,由于需要使用得到后期的频谱图,所以这里需要建立一个DDS IP核,来产生一个可供仿真的正弦波形。而且由于要生成频谱,则在FFT运算完成后的实部、虚部数据进行平方和操作,故需要调用一个乘法器和加法器进行运算。参数配置:我的开发板系统频率是200MHz,所以现在选取FFT的采样频率为200MHz,N=4096;为了实现方便,DDS的系统频率也选取200MHz,相位累加器选取32位位宽,输出正弦波形频率定为10MHz,故DDS的频率控制字=214748365。
下面展示一下我的例化FFT核代码片段:
fft_core fft_core_inst (
.aclk(clk), // input wire aclk
.s_axis_config_tdata(s_axis_config_tdata), // input wire [15 : 0] s_axis_config_tdata
.s_axis_config_tvalid(s_axis_config_tvalid), // input wire s_axis_config_tvalid
.s_axis_config_tready(s_axis_config_tready), // output wire s_axis_config_tready
.s_axis_data_tdata(s_axis_data_tdata), // input wire [15 : 0] s_axis_data_tdata
.s_axis_data_tvalid(s_axis_data_tvalid), // input wire s_axis_data_tvalid
.s_axis_data_tready(s_axis_data_tready), // output wire s_axis_data_tready
.s_axis_data_tlast(s_axis_data_tlast), // input wire s_axis_data_tlast
.m_axis_data_tdata(m_axis_data_tdata), // output wire [15 : 0] m_axis_data_tdata
.m_axis_data_tuser(m_axis_data_tuser), // output wire [15 : 0] m_axis_data_tuser
.m_axis_data_tvalid(m_axis_data_tvalid), // output wire m_axis_data_tvalid
.m_axis_data_tlast(m_axis_data_tlast), // output wire m_axis_data_tlast
.event_frame_started(event_frame_started), // output wire event_frame_started
.event_tlast_unexpected(event_tlast_unexpected), // output wire event_tlast_unexpected
.event_tlast_missing(event_tlast_missing), // output wire event_tlast_missing
.event_data_in_channel_halt(event_data_in_channel_halt) // output wire event_data_in_channel_halt
);
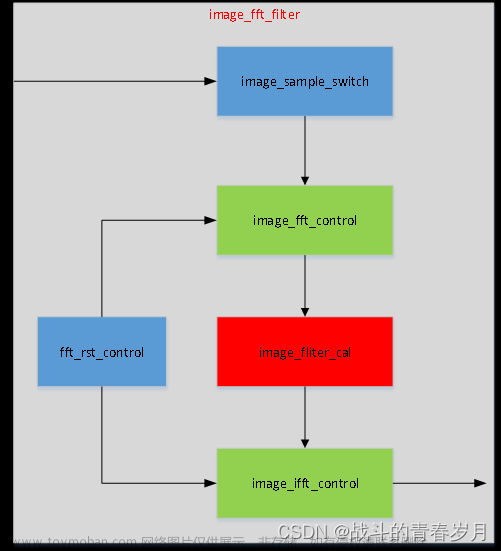
2.程序设计架构
 文章来源:https://www.toymoban.com/news/detail-614440.html
文章来源:https://www.toymoban.com/news/detail-614440.html
3.modelsim仿真
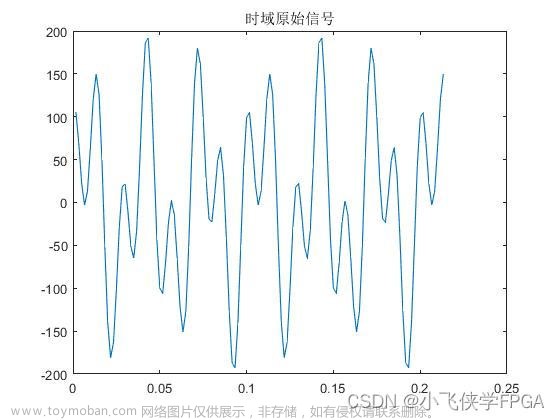
- 首先查看DDS生成的正弦波形是否正常,如下图所示:

- 再将正弦波形输入FFT核,查看输出是否有报错事件信号,如下图:只有event_frame_started信号有脉冲输出,表示开始处理FFT新帧计算,其它事件都为0。

- 输出频谱,如下图所示:

根据查看频谱中最高峰的索引值为3902,经过计算得到最终的信号频率为:(4096-(3902-11))/4096*200=10.009765625≈10MHz。(其中减11是乘法器和加法器的延迟)
总结
本章对Vivado工具中的FFT IP核的应用进行了简单介绍,先介绍了FFT核配置界面的各个选项的功能及配置选项,后又对核的引脚进行了说明,有讲了一个实验例程,对于初学FFT核的同学希望有帮助,如果有不同见解请评论区留言。
注:欢迎大家前来提问探讨。链接:https://pan.baidu.com/s/1ZDuwZBT4E2VYbVWjkKTq9Q
提取码:csdn私信文章来源地址https://www.toymoban.com/news/detail-614440.html
到了这里,关于FPGA中FFT IP核应用(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!